’23년 하이키 라는 걸그룹이 부른 ‘건물 사이에 피어난 장미’이라는 노래를 한 때 많이 들었었다. (JYP DAY6의 YoungK가 작사한 곡이어서..)
힘들지만 꺾이지 않고 이겨내겠다는 의지가 담긴 곡이다.
MIR은 방사선 탐지, 측정, 방호 솔루션 분야 선도 기업이다. 원전 산업이 확장되었을 때 다수 국가/밸류체인이 수주를 위해 경쟁하고 있는 상황 속에서 어느 밸류체인이 주도권을 가질 수 있을지 알 수 없으며, 현 시점에 원전산업 전반적으로 밸류에이션이 상당히 높아져 있는 상황이기 때문에, 매출의 지속성과 틈새시장에서의 점유율 및 시장지배력이 높아 원전 산업 확장의 수혜를 안전하게 받을 수 있는 투자 대안이 선호될 수 있다고 생각했다.
그런 점에서 MIR은 다른 원전 밸류체인 기업들과는 차별화되는 지점이 있다고 생각되었으며, 이에 대해 LTO 멤버들과 나눠보고자 한다.
BM의 이해
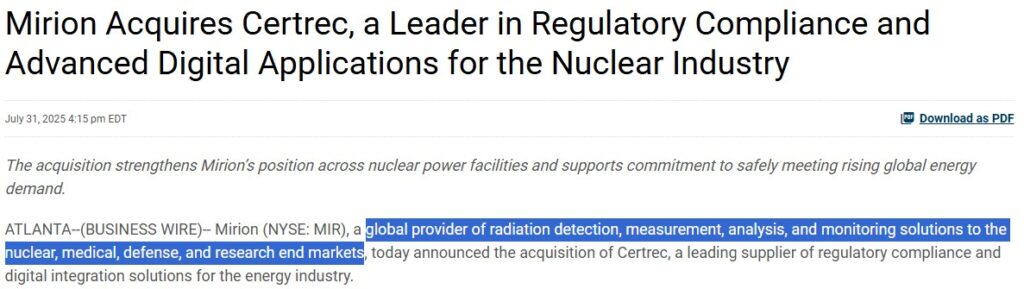
Mirion Technologies(NASDAQ : MIR)는 방사선 탐지·측정 및 방호 솔루션 분야 세계적 선도 기업으로, 원전, 의료(방사선 치료/핵의학), 국방, 연구 시장에 제품과 서비스를 제공한다.
사업 부문은 1) Nuclear & Safety 부문 : R&D 연구소부터 상업 원자력 시설, 군사/국방 현장까지 다양한 방사선 안전 기술을 공급 2) Medical 부문 : 병원 및 암 치료 센터를 대상으로 의료 방사선 분야 솔루션을 제공 으로 양분된다.
주요 제품 및 서비스
Nuclear & Safety 부문은 원자력 발전소용 방사선 감시시스템, 방사능 측정 장비, 원자로 보호계통 부품, 군사/산업용 방사선 센서 등 제품을 판매한다.
Medical 부문은 방사선 치료 품질관리(QA) 장비, 핵의학용 방사능 투여량 계측기(dose calibrator) 및 갑상선 측정기, 방사선 작업자 피폭선량 관리(개인선량계) 솔루션 등 제품을 판매한다. Medical 사업의 약 75%는 암 치료와 직결된 분야로, 방사선 암치료 QA, 핵의학, 작업자 선량 관리 등 암 치료 및 진단 안전에 집중되어 있다. ’21년 인수한 Sun Nuclear는 전세계 방사선 치료 QA 기기의 대표주자로 자리매김하고 있고, ’25년 인수한 Oncospace(Plan AI)는 AI 기반으로 방사선 치료계획을 최적화하는 소프트웨어로 선도적인 방사선 종양학 QA 기술력을 확보하고 있다.
이러한 포트폴리오를 통해 Mirion은 방사선 활용 밸류체인 상에서 핵심적인 계측 및 안전 관리 역할을 담당하며, 고부가가치의 전문 장비와 소프트웨어를 공급한다.
고객 및 지역
Nuclear & Safety 부문의 주요 고객은 원자력 발전소 운영 기업과 설비 OEM(예: Westinghouse, Framatome 등), 규제기관 및 국방/안보 기관, 연구기관이다. 북미를 포함한 글로벌 모든 원전이 Mirion 또는 자회사 제품을 활용하고 있을 정도로 침투했다. ‘25.7월 인수한 Certrec의 규제 준수 소프트웨어는 미국 내 모든 원자로 시설이 사용하고 있다. Mirion은 12개국에 2,800명의 직원을 두고 있으며, 북미와 유럽에 강점을 가지면서 아시아 시장에도 공급망과 파트너 네트워크를 구축해 글로벌 직접판매와 전문 대리점을 병행하고 있다.
Medical 부문은 병원, 암 치료센터, 영상진단센터 등이 중심이다. 미국, 유럽, 일본 등의 방사선 종양학 선진시장에 폭넓게 설치 기반을 보유하고 있어, 신제품이나 소프트웨어를 출시하면 이를 전세계 고객망에 빠르게 확산시킬 수 있는 구조다.
밸류체인 상 위치와 유통
원자력/의료 산업의 Value Chain에서 전문 장비 및 솔루션 공급자로서, 원전 운영 및 환자 치료 과정의 안전성과 품질을 담보하는 필수 장비를 제공한다.
장비들은 규제와 인증이 엄격하여 진입장벽이 높고, 운영 프로세스에 긴밀히 통합되므로 고객가치가 높다.
Mirion의 제품은 주로 자체 영업 및 서비스 조직을 통해 최종 고객에게 직접 공급되며, 일부 지역에서는 현지 유통 파트너를 활용한다. 또한 M&A를 통해 제품 포트폴리오를 확장해왔는데, ’21년 Sun Nuclear 인수를 통해 의료 QA 분야 리더십을 확보했으며, ’25년에는 Paragon Energy Solutions (원전 부품 및 SMR 솔루션), Certrec (원전 규제 소프트웨어), Oncospace (AI 기반 치료계획 소프트웨어) 등을 연달아 인수하며 가치사슬 상 소프트웨어/서비스 비중도 늘리고 있다.
매출 성장성
Mirion의 핵심 시장인 원자력 산업과 의료 방사선 분야는 모두 구조적 성장 사이클에 진입하여, 회사의 중장기 매출 성장에 우호적인 환경이다.
원전산업
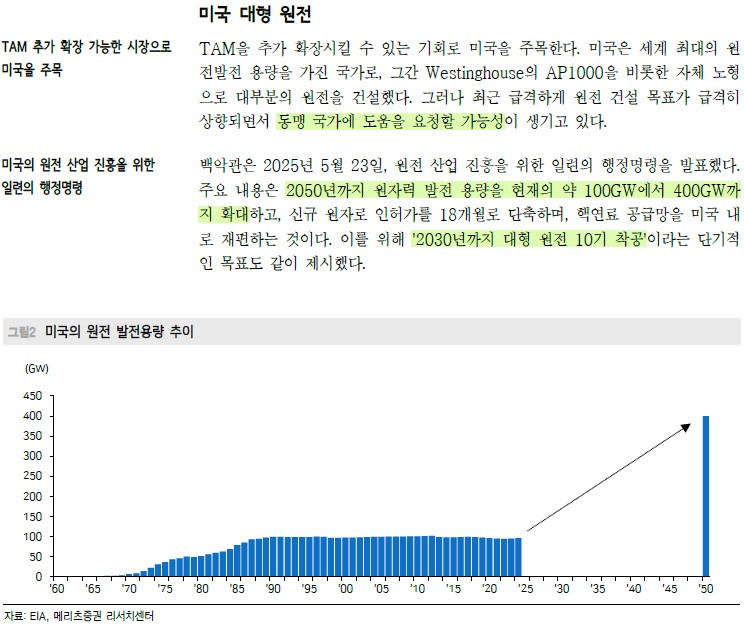
글로벌 ‘원자력 르네상스’ 흐름이 뚜렷하다.
탄소중립 에너지 수요 증가와 에너지 안보 중시로 각국이 원전 건설을 재개하거나 수명연장을 추진하고, 차세대 소형모듈원전(SMR) 개발에도 민관 투자가 확대되고 있다. 이러한 추세에 힘입어 공공 및 민간 차원의 원전 지원정책이 늘어나 Mirion이 속한 방사선 계측/안전 시장도 구조적 성장 기반이 마련되었다.
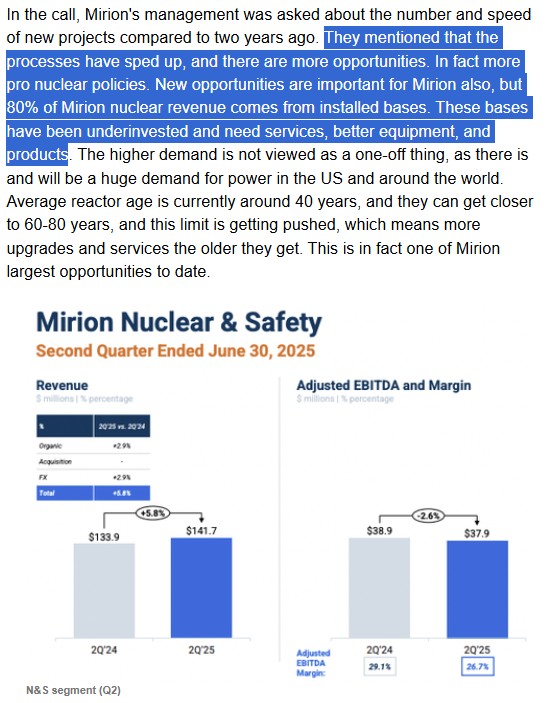
경영진은 ‘25.3Q 실적발표에서 “원자력 발전 엔드마켓의 지속적 모멘텀”을 강조하며, 신규 원전 및 SMR 관련 수요를 적극 공략하고 있다고 밝혔다.
‘25.3Q Mirion은 소형모듈원전 신규 건설 프로젝트로 약 $10M 규모 수주를 따냈고, 이어 10월에는 아시아 지역 기존 원전 설비 교체 수주 $55M를 확보했다. 이로써 회사가 공개했던 $350M 규모의 대형 수주기회 중 약 $65M가 성약되었으며, 나머지 $285M 중 상당 부분도 ’25~’26년에 발주될 것으로 예상된다.
대형 프로젝트 수주는 원자력 산업의 구조적 성장 흐름이 현실화로 향후 매출 성장에 큰 동력이 될 것으로 기대된다. CEO 역시 “원자력 발전의 우호적 시장 환경에서 우리의 노출도를 확대하는 목표를 달성했다”며, Paragon과 Certrec 인수를 통해 원전 매출 비중이 45%까지 상승할 것으로 전망했다. 이는 1~2년 전 40% 수준에서 높아진 것으로, 원전 포트폴리오 확대 가시화를 입증한다.
의료 방사선
의료 부문에서는 방사선 암 치료 및 진단 수요의 구조적 증가가 핵심 동인이다. 세계 인구 고령화와 암 발병률 상승으로 방사선 치료 시장은 꾸준한 성장세를 보이고 있다. Medical 사업의 약 3/4가 암 치료 관련(방사선 치료 품질관리, 암진단 핵의학 등)인 만큼 이러한 메가트렌드의 직접적인 수혜를 본다.
방사선 치료 기기(선형가속기 등) 보급 확대는 품질관리 장비 및 서비스에 대한 수요로 연결되기 때문에, 해당 분야 세계 1위인 Mirion(Sun Nuclear)의 성장률은 평균을 상회할 전망이다. 아울러 원격진료 및 디지털 헬스 추세 속에서 병원의 디지털 선량관리(방사선 작업자가 얼마나 방사선을 받았는지 기록/관리하는 방법) 시스템 전환 수요도 증가하여, Mirion이 개발한 디지털 개인선량계(Instadose) 등의 보급이 가속될 것으로 보인다.
다만 단기적으로는 미국 등 일부 지역에서 의료기관의 예산 압박으로 방사선 치료 QA 장비 투자에 지연이 발생해 Medical 부문 주문이 다소 주춤한 측면도 있다. (Mirion은 미국 의료 시장 환경이 방사선치료 QA 수요에 압력을 주고 있다고 언급) 그럼에도 불구하고 디지털 서비스 매출 증대 및 해외 수요로 이를 상쇄하고 있어, 전반적인 의료 부문은 안정적 성장세를 유지 중입니다.
향후 전망
’25년 올해 유기적 매출성장률 가이던스를 4.5~6.0%로 제시하였고 인수 효과와 환율영향을 포함한 총매출 성장률은 7~9%로 전망했다.
3분기 누적 실적 기준 매출 +7.9% 증가로 목표 범위 내를 달성하고 있으며, 경영진은 “2025년 가이던스 달성이 순조롭다”고 자신감을 나타냈다.
조정 EPS가 전년 동기 대비 50% 상승하는 등 수익성 동반 성장을 이루어낸 점이 고무적이다. ’26년 이후에는 Paragon 인수로 SMR 시장의 성장성을 흡수하고 기존 원전 운영자 대상 교체부품 사업을 확장할 기반을 얻었다. Medical 부문에서도 AI 기반 소프트웨어와 디지털 플랫폼화로 성장을 이어갈 계획이다.
일부 단기 리스크(중국 등 일부 지역 수요 둔화, 특정 방산용 선량계 대형 주문의 지연 등으로 ’25년 유기적 성장 가이던스를 소폭 하향 조정)가 있었으나, 전체적인 시장 구조는 우상향 추세로 평가할 수 있다.
경제적 해자
Mirion의 방사선 계측·안전 산업은 진입장벽이 높고 전문성이 요구되는 틈새 시장으로, 오랜 업력과 기술력으로 여러 측면에서 경쟁우위를 구축하고 있다.
무형자산(브랜드·기술력)
방사선 안전 및 측정 분야의 세계적인 리더로 인정받는 브랜드다. 원자력 업계에서는 Mirion 및 자회사(예: Canberra, MGPI 등으로 오랜 역사를 가진 브랜드)의 신뢰성이 높아, ‘25.9월에는 국제 원자력 기구(IAEA)까지 Mirion과 파트너십을 맺고 글로벌 방사선 안전을 강화하고 있다.
의료 분야에서도 Mirion Medical 자회사 Sun Nuclear는 방사선 치료 품질관리의 사실상 업계 표준으로, Johns Hopkins에 따르면 “방사선 종양학 품질보증의 글로벌 리더”로서 혁신적 솔루션을 전세계에 제공하고 있다.
브랜드 파워는 고객이 안심하고 장비를 채택하도록 하는 신뢰 자본으로, 동종 중소 경쟁사들이 넘보기 어려운 자산이다.
또한 Mirion은 수십 년간 축적된 방사선 계측 기술 특허와 노하우를 보유하고 있고, 최근에는 AI 기술(Oncospace)과 규제 소프트웨어 역량(Certrec)까지 확보하여 제품 차별화를 강화하고 있다.
예를 들어 Certrec의 규제 솔루션은 미 NRC 인가 및 원전 사이버보안 등에 필수적인데, 이러한 전문화된 소프트웨어 역량은 Mirion만의 경쟁력이다.
전환 비용
Mirion 제품이 운영 프로세스에 내재화되므로 고객이 타사로 전환하는 비용과 위험이 높다.
원자력 발전소를 예로 들면, 방사선 모니터링 시스템이나 원자로 보호용 센서는 설치되면 교체나 인증에 많은 비용과 노력이 들기 때문에 수십 년 운영 기간 동안 초기 공급자를 계속 쓴다. Paragon이 보유한 원전 부품 플랫폼은 북미 모든 원전에 채택될 정도로 표준화되어 있는데, 이런 부품을 다른 업체 것으로 변경하려면 추가적인 테스트와 규제 승인 등의 막대한 전환 비용이 발생한다.
Certrec의 소프트웨어도 미국 모든 원전이 이미 사용 중인 상황에서 다른 시스템으로 바꾸기는 사실상 비현실적이다.
의료 분야도 마찬가지로, 병원이 특정 회사의 QA 장비와 소프트웨어로 다년간 워크플로우를 구축하면, 이를 타사 제품으로 바꾸는 데 교육·절차 변경 등의 비용과 비효율이 커진다. 특히 Sun Nuclear의 QA 솔루션은 많은 암센터에서 표준 프로토콜로 활용되고 있어 사실상의 잠김 효과가 있다.
네트워크 효과
소셜 미디어나 플랫폼만큼의 직접적인 네트워크 효과는 크지 않지만, 규모의 경제와 데이터 축적에 따른 간접 네트워크 효과를 누리고 있다.
디지털 Instadose 선량관리 플랫폼은 사용자와 피폭 데이터가 누적될수록 산업 표준으로 자리잡아 더 많은 고객을 끌어들이는 선순환을 만들 수 있다. 최근 인수한 Oncospace AI 플랫폼은 5,000명 이상의 환자 데이터를 학습하여 치료계획을 최적화하는데, Sun Nuclear의 전세계 병원 네트워크를 통해 사용자가 늘어나면 더 많은 데이터가 모여 알고리즘 성능이 향상되고 이는 다시 제품 가치 상승으로 이어진다
즉, Mirion의 광범위한 설치 기반은 새로운 소프트웨어/서비스에 글로벌 확산력을 제공하며, 고객이 동사 에코시스템에 합류할 유인을 높인다. 또한 Mirion은 다양한 제품군을 통합한 디지털 플랫폼 전략(예: 병원의 QA/선량 데이터 통합관리)을 추구하고 있어, 고객이 한번 Mirion의 시스템에 들어오면 여러 서비스를 연계 사용하는 크로스셀링 효과도 기대됩니다.
규모 및 비용우위
방사선 계측 산업은 비교적 좁은 시장이지만 Mirion은 그 안에서 포트폴리오와 매출 규모가 가장 크다. 전세계 2,800명의 인력과 글로벌 생산·서비스 거점을 보유한 Mirion은, 주요 경쟁사가 지역 중소기업이거나 특정 제품 전문회사인 것에 비해 규모의 경제와 원가경쟁력을 갖추고 있다.
자체 공장에서 표준화된 생산을 하여 원가를 절감하고, 부품 조달에서도 구매력 우위를 활용할 수 있다. 또한 최근 인수한 Paragon의 엔지니어링 역량과 부품 조달 노하우를 더해 원전 부품 분야에서 비용 효율성을 강화할 계획이며, 이번 인수로 예상되는 연 $10백만의 시너지효과도 상당 부분 원가절감에서 창출될 것으로 보인다.
아울러 Mirion은 사업통합을 통해 중복 비용을 제거하고 운영 효율을 높여왔다고 밝혔는데, 실제로 2023년에 SG&A 비용을 절감하며 영업이익 개선을 이룬 바 있다. 이러한 규모와 효율성은 Mirion의 수익성에 기여하며, 영세 경쟁사들이 모방하기 어렵다.
경쟁사 대비 현황
각 세부 시장에는 몇몇 경쟁사가 존재하지만, 대부분 특정 부문에서만 Mirion과 겹친다.
원자력 계측에서는 Thermo Fisher의 방사선측정기 사업부나 Fuji Electric, Ludlum 등 일부가 경쟁하지만 제품 폭과 국제 서비스망에서 Mirion이 우위다.
원전 안전장비 분야의 큰 플레이어인 Westinghouse는 원자로 자체를 공급하는 OEM으로 Mirion과 협력 관계에 가깝고, 원전 부품 솔루션의 직접 경쟁사는 Paragon 인수로 상당 부분 흡수되었다.
방사선 의료기기 분야의 글로벌 리더인 Varian Medical (현재 Siemens Healthineers 소속)이나 Elekta 등은 주로 치료장비 제조사로서 Mirion과 보완적 관계가 크며, QA나 선량관리 분야에서는 Mirion이 전문 솔루션을 공급한다.
다만 방사선 치료 QA 장비에서는 IBA의 Dosimetry 사업부, 독일 PTW 등 몇몇 전문업체가 경쟁하고, 작업자 선량관리 서비스에서는 미 Fortive사 소속의 Landauer가 미국 내 강자다. Landauer는 전통적 필름 배지로 시장을 이끌어왔으나 Mirion은 디지털 선량계로 차별화하여 경쟁하고 있다.
전반적으로 Mirion은 각 분야에서 시장 점유율 1~2위를 차지하고 있으며, 광범위한 제품군을 통해 경쟁사 대비 방어력이 탄탄하다.
협상력: 가격·원가·마진 분석
Mirion의 가격 결정력과 비용 통제력을 살펴보면, 최근 몇 년간 수익성 지표 개선을 통해 상당한 협상력 향상을 보여준다.
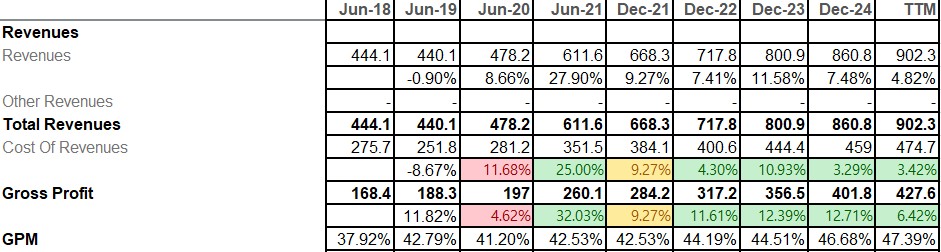
매출총이익률(GPM)
‘25.3Q GPM은 46.8%로 전년 동기 44.9%에서 약 1.9%p 상승했으며, TTM 기준 47.39%로 ’23년의 44.51%, ’24년의 46.68% 대비 지속적인 수익성 개선을 시현하고 있다.
제품 믹스 개선과 가격 인상이 주된 요인으로, Medical 부문의 원가가 전년보다 $1.0M 감소하여 마진이 개선된 반면 Nuclear & Safety 부문의 원가는 매출증가에 따라 $7.4M 늘었지만 이는 주로 물량 증가와 환율 영향에 따른 것이었다.
Medical 부문에서 “높은 마진의 제품/서비스 비중 확대”가 일어나 전체 GPM 상승을 견인했다. 회사는 소프트웨어·서비스 매출 증대로 향후 더 높은 마진율을 추구하고 있으며, 경영진은 Medical 사업에서 소프트웨어/서비스 제공을 늘려 마진을 확대하고 있다고 언급했다. 이는 고정비 증가 없이 추가매출을 올릴 수 있는 구독형 소프트웨어, 클라우드 선량관리 등의 매출 비중이 늘고 있음을 시사한다.
가격(P) 협상력
최근 판매 가격을 성공적으로 인상하며 매출 성장에 기여했습니다. ‘25.3Q Medical 부문 매출 증가는 판매량 증가와 가격 인상, 환율 영향에 따른 것이라고 밝혔다.
Nuclear & Safety 부문 역시 유기적 물량 성장, 가격 인상, 그리고 인수 효과가 매출 상승 요인이었다.
이는 Mirion이 고객에게 일정 수준 가격 전가를 무리 없이 수행했음을 의미한다. ’20년대 초반 원자재·물류비 상승 국면에서도 동사는 가격정책을 통해 마진을 방어했었다.
다만 고객 군이 정부·전력공기업·대형 병원 등 협상력이 강한 기관이 많아 무한정 가격을 올릴 수 있는 구조는 아니므로, Mirion의 가격우위는 제품 차별화에 따른 가치 기반으로 이해된다. 핵심 안전장비나 규제상 필수품목의 경우 대체재가 없어 가격 민감도가 낮기 때문에, Mirion이 그 가치에 걸맞은 프리미엄을 확보할 수 있다.
신형 디지털 선량계나 AI 소프트웨어는 기존 방식 대비 효율이 높아 고객이 더 높은 가격을 받아들일 유인이 크며, Mirion은 해당 분야 선도기업으로서 가격주도자 역할을 할 수 있습니다.
수량(Q) 성장과 운영 레버리지
앞서 언급한 대로 Mirion은 양호한 수요 증가로 판매 물량(볼륨)이 늘고 있으며, 특히 원자력 부문에서는 Q3에 9% 유기적 매출성장을 기록할 정도로 견조한 성장이 있었다. Medical 부문도 미주 일부 부진을 다른 지역 수요로 커버하면서 완만한 물량 증가를 유지했다.
이러한 Q 성장은 생산설비 가동률을 높이고 고정비 비중을 낮추는 효과를 내어 마진율 개선에 기여한다. Mirion은 또한 대형 프로젝트 수주 시 규모의 경제로 납품 단가를 인하해주면서도 이익을 확보할 수 있는 구조를 가지고 있다.
’25년 수주한 $55M 아시아 원전계측 프로젝트는 기존 제품의 해외 확장으로, 추가 개발비용 없이 대량생산 효율을 얻는 케이스다. IBA 등 경쟁사들도 사상 최대 수주잔고를 보고한 것에서 알 수 있듯이, 수주잔고가 늘어나는 추세로 물량 증가에 따른 영업레버리지 효과에 의한 이익률 추가 개선 여지가 있다.
비용(C) 관리 및 원가 협상력
원자재비와 제조원가 측면에서 비교적 양호한 통제력을 보여주고 있다.
‘25.3Q Nuclear & Safety 부문 원가 상승분 $7.4M 중 상당 부분(약 $3.9M)은 매출 증가에 따른 변동비 증가이며, 실질적인 단위당 원가 상승은 $1.3M에 그쳤고, 나머지는 환율 영향이다.
이는 관세 인상으로 인한 글로벌 공급망 인플레이션에도 불구하고 효율적인 조달과 원가 절감 노력으로 비용 상승을 최소화했음을 의미한다. Mirion은 여러 제조 거점을 활용해 환율과 관세 영향을 분산하고 있고, 규모의 경제로 부품 공급업체와의 협상에서도 유리한 조건을 이끌어낼 수 있다.
’24년에는 미국 위스콘신 공장 통폐합 등 제조 footprint 최적화를 통해 비용 절감을 추진했다. 한편, 인건비나 기술인력 비용은 R&D 투자 확대에 따라 다소 증가했으나, 미래 성장을 위한 투자로 이해할 수 있다.
향후 전망
’25년 가이던스에서 Adj. EBITDA 마진 24.0~25.0%를 제시하였고, 3분기 실적 기준 누계 Adj. EBITDA 마진은 약 23%로 연말로 갈수록 상승할 것으로 예상된다.
원자력 부문 고마진 프로젝트 매출이 4분기에 인식되고, 소프트웨어 매출 비중 확대로 추가 마진 개선이 가능하기 때문이다. 특히 Certrec는 ‘25E EBITDA 마진 50% 이상인 고소프트웨어 기업으로, 인수 후 통합되면 전체 EBITDA 마진을 견인할 전망이다. (Certrec 인수 가격이 ’25년 예상 EBITDA의 16.9배였는데, 이는 소프트웨어 업종 특유의 높은 마진과 성장을 반영한 것)
자본배치
Mirion은 강력한 현금창출력을 바탕으로 적극적인 M&A 성장 전략을 구사하고 있다.
현금흐름
’25년 현금흐름(FCF)이 크게 개선되었다.
3Q 조정 FCF는 $18M으로 전년 동기의 약 두 배 수준이며, 1~3분기 누적 FCF는 $53M로 조정 EBITDA의 35%를 현금으로 전환했다. 이는 운전자본 효율화 및 수익성 제고의 결과로, 전년도 같은 기간 대비 큰 폭으로 개선되었다.
경영진은 ‘25년 연간 조정 FCF 가이던스를 $1억~1.15억으로 상향 조정하였는데, (하한을 $95M → $100M로 상향) 이는 Adjusted EBITDA의 45~49%에 달하는 높은 현금전환율로, Mirion 사업의 높은 현금수익 특성을 보여준다. (방사선 장비는 선금/마일스톤 대금 비중이 높고, 서비스 매출은 지속 현금창출) 이처럼 견실한 현금흐름은 Mirion이 공격적 M&A 후에도 재투자 여력과 부채상환 능력을 유지할 수 있게 해주며, 주주환원 여력도 갖추게 한다.
M&A 전략과 성과
Mirion은 지난 1~2년간 전략적 M&A를 통해 포트폴리오를 빠르게 확장했다. ‘25.9월 약 $5.85억에 인수 계약을 체결한 Paragon Energy Solutions는 미국 원전용 부품공급 및 SMR 솔루션 업체로, Mirion의 원전 사업 규모를 확대하는 딜이다.
Paragon은 ’26년 약 $1.5억 매출과 20~22% EBITDA 마진을 전망하고 있어 인수 후 Mirion의 원자력 부문 매출이 30%가량 늘고, SMR 등 신규 성장분야 노출도 증가한다. 인수가는 ’26년 예상 EBITDA의 약 18배 수준으로 다소 높지만, 경영진은 첫해부터 주당순이익(EPS)에 기여하는 인수이며 5년 내 $10M 이상의 시너지(상업/원가) 창출을 자신하고 있다.
‘25.7월에는 Certrec을 $8,100만에 현금 인수하여 원전 규제/컴플라이언스 소프트웨어 영역을 확보했다. Certrec은 매출 대부분이 고마진 구독형으로 지속적 수익원을 제공하며, 미국 모든 원전에 고객기반을 가진 만큼 Mirion의 서비스 비즈니스 모델 전환에 크게 기여할 것이다.
‘25.4월 인수한 Oncospace (Plan AI)는 비교적 소규모 딜이지만 첨단 AI 기술을 손에 넣어 Medical 부문의 경쟁력을 높였다.
연이은 M&A는 Mirion의 핵심 전략으로, 성장 시장에 대한 선제적 투자다. 현재까지 통합 성과도 양호하여, Sun Nuclear 등 과거 인수 자산들이 매출 성장과 마진 개선에 기여하고 있고 Medical 부문에서 디지털 혁신을 주도하고 있다.
자금 조달과 재무정책
Mirion은 M&A 재원을 마련하기 위해 탄력적인 자본조달을 실행했다. Paragon 인수 자금으로 ‘25.9월 약 $325M의 0% 쿠폰 전환사채(’31년 만기)를 성공적으로 발행했고, 동시에 주식 1,730만주 공개발행(주당 $21.35에 약 $3.7억 조달)을 실시했다.
이자비용이 없는 채권과 증자를 병행하여 부채비율을 과도하게 높이지 않으면서도 필요한 현금을 확보하였다. 실제 Mirion은 2021년 SPAC 상장 시 확보한 자금과 이후 현금창출로 순차입금/EBITDA를 ’24년 2.X배까지 낮췄으며, 이번 인수로 일시적 레버리지가 상승해도 신규 EBITDA 기여로 빠르게 디레버리징할 것으로 예상된다.
주주가치 희석을 최소화하기 위해 $3,100만을 들여 자사주 매입을 병행, 시장 충격을 완화했다.
주주환원
성장주로서 현재까지 배당은 실시하지 않고 있으나, 자사주 매입 프로그램을 도입하여 주주환원에 나서고 있다. ‘24.12월 이사회 승인으로 최대 $1억 규모의 자사주 매입을 ’29년까지 시행할 수 있는 프로그램이 시작되었다.
다만 자사주 소각은 이루어지지 않았고, 현 시점에서는 성장 투자(M&A)에 자금 우선 배분을 하는 모습이다. 경영진은 성장 기회가 투자수익이 높다고 판단하기 때문에 당분간 잉여현금은 추가 인수합병, 신제품 개발, 부채상환 등에 활용할 것으로 보인다. (이러한 성장 지향적 자본배치는 고성장 국면의 기업으로서는 합리적이다)
동시에 재무 안정성 지표(순부채/EBITDA 등)를 지속 모니터링하여 투자등급 수준을 유지하는 보수적 재무 관리 기조도 유지하고 있다.
밸류에이션
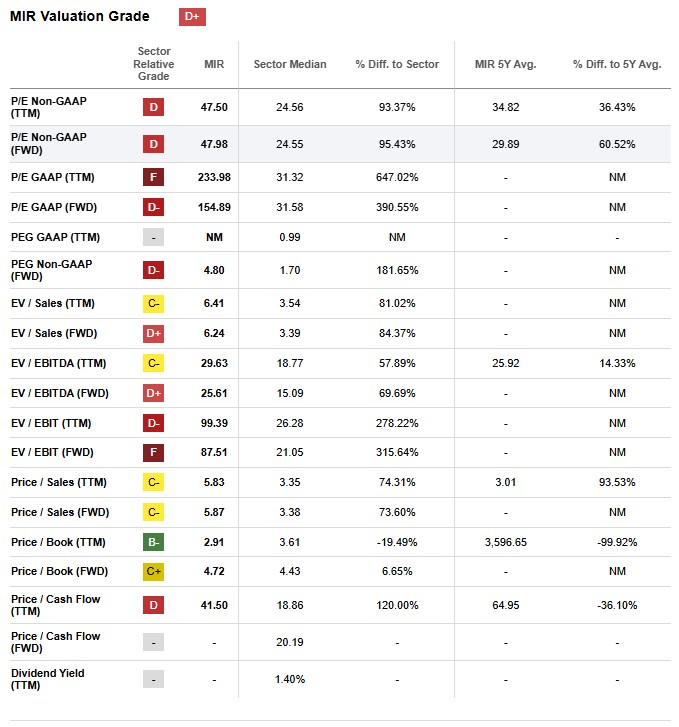
Mirion은 최근 주가 상승으로 절대 수치는 높아졌으나 성장성과 업종 특성을 감안해야 한다. 한 해석이 필요합니다. ‘25.12월 주가는 약 $23 수준이며 시가총액은 약 $60억 달러(약 9조) 수준이다. 조정 주당순이익(EPS) 기준 PER은 fEPS $0.50 내외로 환산시 47.98배다.
GAAP 순이익 기준으로는 ’25년 이제 흑자전환한 상태라 TTM PER이 233.98이다. 이러한 지표만 보면 전통적인 가치평가 관점에서는 상당한 고PER주로 보일 수 있다. 그러나 높은 성장률과 방사선 산업의 특수성도 프리미엄 요인으로 고려해야 한다.
동종 업계 주요 기업들과 비교하면 Mirion의 가치평가는 프리미엄이 붙어 있으나 일부는 정당화되는 측면이 있습니다. 아래 표는 Mirion과 몇몇 관련 기업의 주요 지표 비교입니다:
기업명
2024년 연매출
EBITDA 마진
EV/EBITDA
주가수익비율 (P/E)
Mirion Technologies
~$8.3억
24~25%
~27배
~46배 (조정 EPS 기준)
Fortive (미국 계측 대기업)
$42억
~28% (조정)
~12배
~20배 (Forward)
Elekta (스웨덴 의료기기기업)
$16억
~22%
~13배
~15배 (Forward)
IBA (벨기에 방사선기기)
€4.98억
~3% (REBIT 3.5%)
N/A (변동 큼)
N/A (흑자전환)
Varian Medical (미국 방사선 치료)
~$30억
~25%
~20배 (추정)
~30배 (추정)
위에서 보듯 Fortive(산업 계측 및 Fluke 등을 보유한 대형사)는 안정적인 저성장 사업 포트폴리오로 EV/EBITDA 약 12배, P/E 20배 내외의 낮은 배수를 받고 있다.
Elekta(방사선치료기 제조사)는 최근 구조조정 효과로 이익이 늘고 있으며 EV/EBITDA 12~13배, Forward P/E 15배 수준으로 거래된다.
Mirion은 EV/EBITDA 27배로 확실히 두 배 이상의 프리미엄이며, 이는 중소형 성장주에 대한 시장의 기대를 반영한다. Mirion은 매출 증가율(중기 7~9%)이 높고 소프트웨어 비중 증가로 수익률 확대 여지가 있다는 점에서, 프리미엄을 일부 인정받고 있다. 또한 방사선 계측/안전 분야는 규모는 작아도 독과점적 성격이 강해, 희소 자산으로서 높은 밸류에이션을 받을 수 있다.
결론 : 안정적인 BM, 성장 잠재력을 조금만 더 보여줄 수 있을까
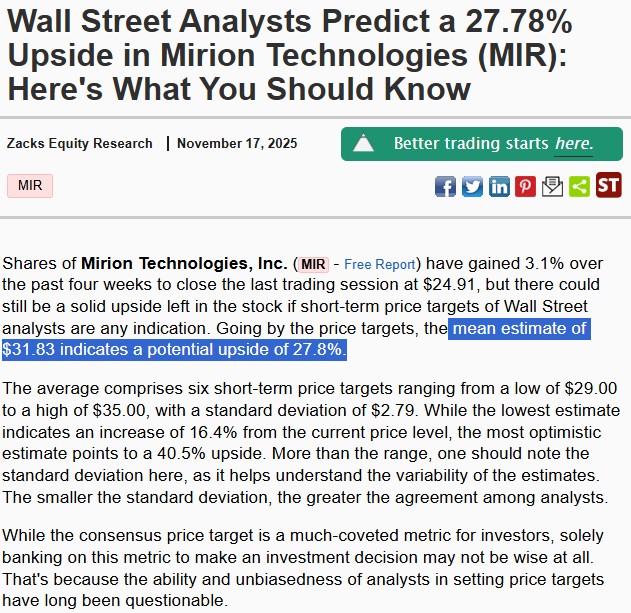
저평가 여부를 판단하기 위해서는 Mirion의 향후 이익 성장에 대한 확신이 중요하다. ’26년 Paragon 인수 실적이 더해지고 원전 르네상스 효과가 본격화되면 성장률이 가속(+20% 이상)될 가능성이 있다. 증권사 컨센서스는 Mirion의 향후 상승 여력 약 +28%를 보고 있으며, 실제 2025년 10~11월에 주가가 실적 호조로 두 자릿수 급등한 후에도 추가 업사이드가 있다고 평가했다.
다만, 유기적 매출 성장이 한자릿수 중반에 머무는 것은 LTO 투자관점으로 봤을 떄 다소 아쉽다고 생각하며, 밸류에이션 또한 안전마진을 제공하는 수준과 거리가 멀다. 즉, 현재 밸류에이션은 앞으로 상당한 성장성을 보여주고도 다소 비싸다는 평가를 받을 수 있는 수준이라고 생각했으며, 경영진은 지속적으로 좋은 자본배치를 할 수 있다는 것을 증명해나가야 하는 부담을 짊어지고 있다.
따라서 MIR를 원전 사이에 피어난 장미라고 인정해주려면 조금 더 활짝 피어 향기를 퍼뜨려야 하지 않을까 생각되었다.
가치투자 커뮤니티를 성장시켜나가고 있습니다. 운영 계획과 방향성을 한 번 읽어보시고, 텔레그램과 유튜브 채널을 통해 소통하고 있으니 공감이 가신다면 참여해주세요! 쌍방향 소통을 원하는 분들은 카카오톡 채널로 와 주시면 좋을 거 같습니다. 자료실을 통해 리포트, 뉴스도 공유하고 있으니 참고하시면 도움이 될 거 같습니다.
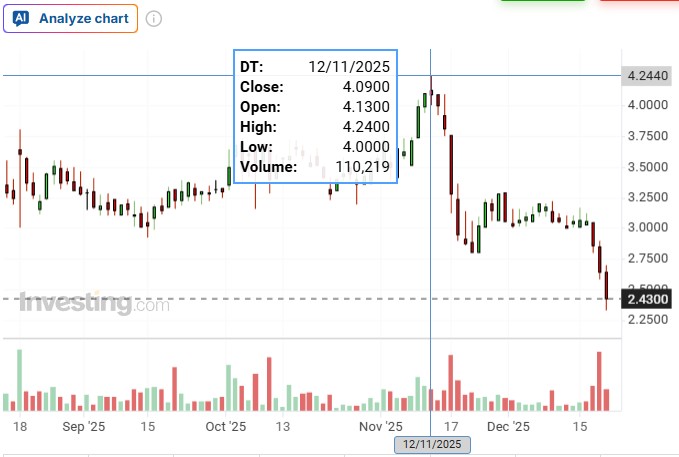
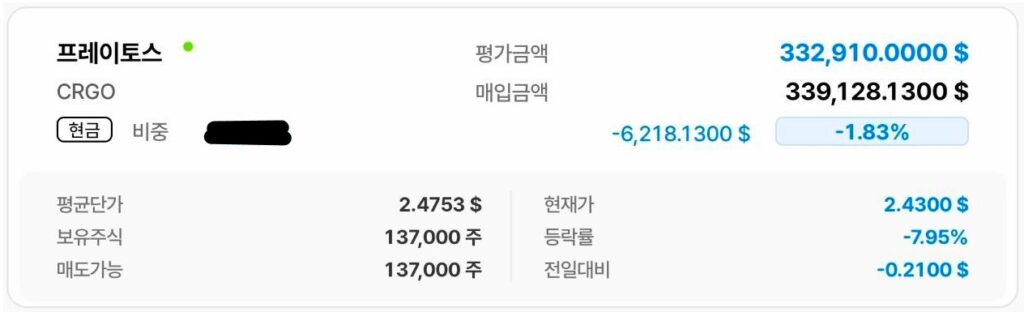
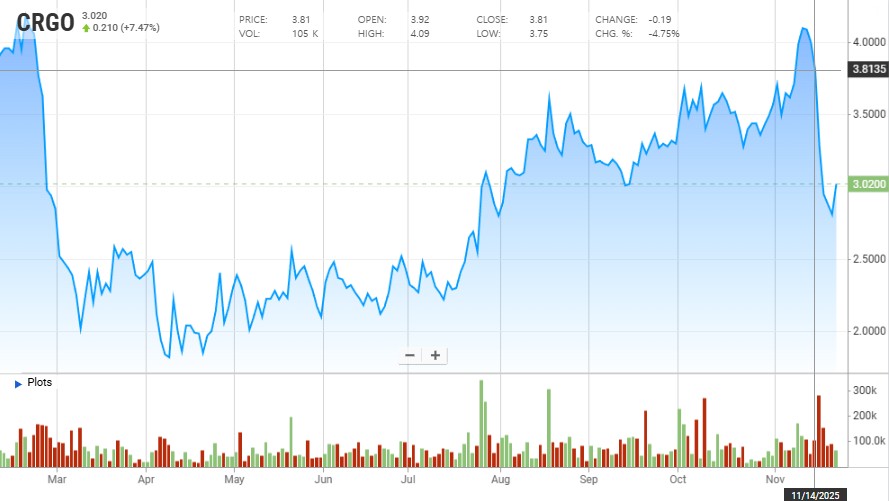
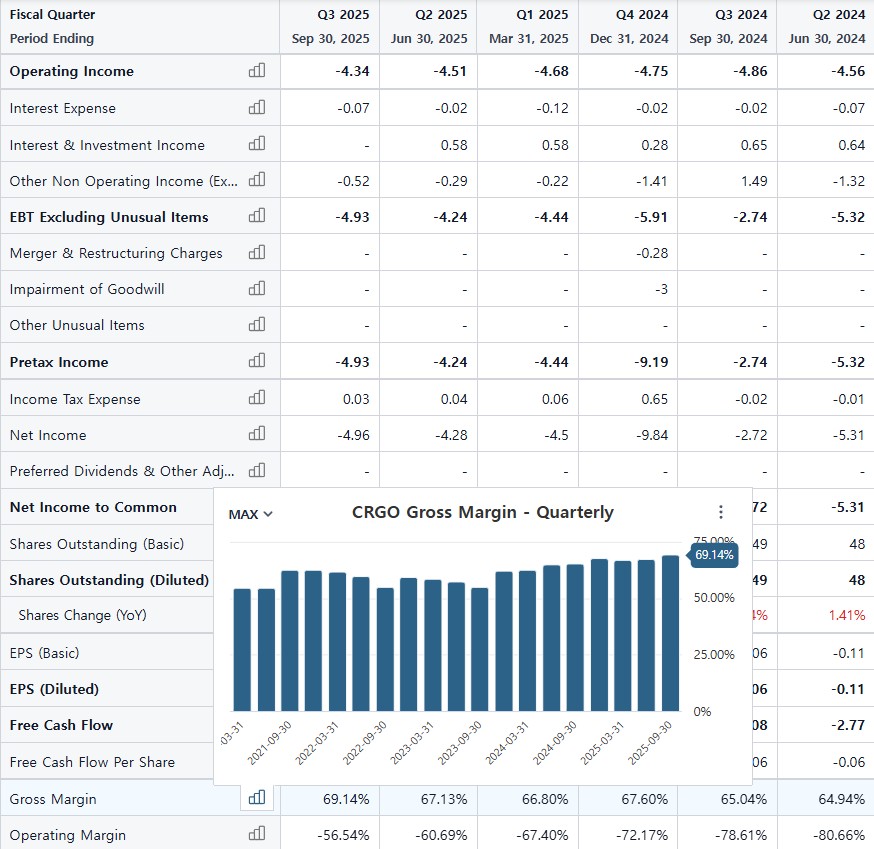
일회성 매출 감소라는 내재가치, 성장성과 무관한 이벤트로 가이던스를 낮춘 CRGO가 이번 주에는 CEO 사임이라는 악재를 만나 주가가 단기간에 1/3이 빠지는 경험을 했다.
137,000 * 1.81 * 1,480 = 366,995,600 나에게도 40일만에 평가손실 3.67억원이 발생헀다. 하지만 후회되지는 않는다.
가장 큰 비중을 CRGO에 투자하고 있었기에 큰 손실을 볼 수밖에 없었지만 그럼에도 불구하고 내가 생각한 투자 아이디어를 변경할만한 사실은 발견되지 않았기 때문에 보유 의견에도 변함이 없다.
‘경제적 해자’에서 팻 도시는 CEO가 기업이 보유한 영속적 해자가 아니라고 주장한다. CEO는 언젠가 기업을 떠나간다. 물론 주주로서 기업과 함께하는 좋은 소유자와 동행하며 누릴 수 있다면 나쁠 이유는 없다. 하지만 우리는 대체로 소유자의 영향력을 과대평가한다. 패턴을 찾기 어려운 것에서도 우리는 쉬운 원인을 찾으려 하고, 그랬을 때 가장 좋은 대상은 CEO가 아닐까?
버핏님께서는 바보도 운영할 수 있는 회사에 투자하라고 하셨다. 나는 지금 CRGO가 이미 변곡점을 지나 선순환 구조를 통해 매출 성장의 기울기가 더 가팔라지고 있기 때문에 바보도 운영할 수 있는 회사라 생각한다. 항공, 해운 물류 수요자와 공급자가 많다는 점 자체가 다른 수요자와 공급자를 끌어들이는 힘의 원천이 된다.
그리고 CEO가 내부자로서 뭔가 부정적 징후를 포착하고 Exit을 하려는 것이라면, SEC는 증권범죄에 대해 잔인하다고 할 정도로 가혹한 처벌을 내리는 것으로 유명하다. 그렇기에 미국이, 뉴욕증시가 자본주의의 첨단에 서 있을 수 있는 것이다. 그리고 Zvi Shreiber는 계속하여 기업가 활동을 추구하는 사람이라는 점에서 법적으로 문제가 없지만 도덕적으로 비난받을만한 행동을 할 유인이 적다.
물론 아직 내가 알지 못하는 어떤 일이 일어날지 모른다. 어떤 돌발 악재가 우리를 기다리고 있을지 알 수 없다. 하지만 그것이 CRGO 내재가치에 직접 영향을 미친다는 충분한 근거가 없는 상황에서 주가만 하락한 시점에 소중한 지분을 헐값에 매각하는 행위는 자산을 축적하는 길과는 반대라고 생각한다.
우리는 대체로 너무 걱정이 많고, 그래서 너무 많이 행동한다.
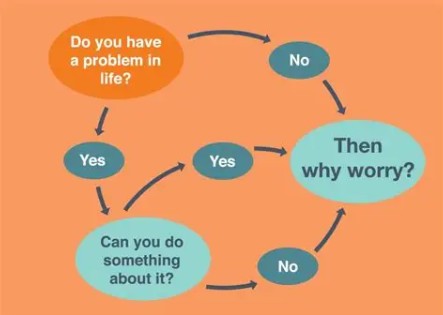
Do you have a problem in life?
애초에 나는 CRGO를 비롯한 커버기업들이 결과적으로 성장 내러티브를 실현할 거라는 데 대한 큰 의심을 품지 않는다. 그렇다면 애초에 주가 하락 자체가 인생에 있어 문제가 될 이유가 없다. 만약 문제가 된다 하면 그것은 투자 방식에 문제가 있었던 것일 가능성이 높다.
만약 문제가 된다면 두 번째 질문으로 넘어가보자.
Can you do something about it?
주가가 하락한 데 대해 뭔가를 할 수 있나?
매도는 하락한 데 따른 효과적인 대응이 아니다. 오히려 더 큰 손실을 가져올 뿐이며, 실제 가치와 주가의 괴리가 커져서 올라갈 일만 남은 주식을 파는 것은 바보같은 일이다. 조금씩 매수를 해볼 수는 있겠지만 이를 통해 주가를 조정해보려고 하는 것은 무모하다. 결국 주가 자체에 영향을 미치려 할 방법도, 이유도 존재하지 않는다.
Then why worries?
이렇게 말하고 있지만 작지 않은 평가손실이 나를 아프게 하는 것은 변함없는 사실이다. 그리고 더 아픈 것은 내 투자 아이디어에 공감하여 CRGO에 투자한 동료들의 손실이다.
하지만 나는 이 시기를 빌어 LTO 투자관을 더 강조할 수밖에 없다. 그리고 이런 시련의 시기를 견뎌내는 경험을 통해 더 견고하게 나아갈 기반을 마련하자고 여러분에게 더 강하게 권유할 수밖에 없다.
그리고 이런 어려운 시기를 빌어 모두에게 다시 한 번 감사한 마음을 전하고 싶다.
가치투자 커뮤니티를 성장시켜나가고 있습니다. 운영 계획과 방향성을 한 번 읽어보시고, 텔레그램과 유튜브 채널을 통해 소통하고 있으니 공감이 가신다면 참여해주세요! 쌍방향 소통을 원하는 분들은 카카오톡 채널로 와 주시면 좋을 거 같습니다. 자료실을 통해 리포트, 뉴스도 공유하고 있으니 참고하시면 도움이 될 거 같습니다.
여러번 언급했던 바와 같이, 서구 AI가 독자적인 점유율을 지켜나갈 수 있다면 MDB 투자에 대해 전혀 걱정이 없다. 하지만 DeepSeek, Kimi K2 등 낮은 트레이닝 비용으로 만든 AI 모델을 실리콘밸리에서 실제 사용하고 있다는 소식은 서구 AI 모델들의 경쟁력에 대한 근본적 의문을 제기하게 하였다.
‘스푸트니크 모먼트’라고 하는데, 쉽게 말하면 우리가 가만히 있다가는 큰일나겠다는 절박함을 느끼게 되는 시점을 의미한다. 미국은 스스로 세계적으로 기술을 선도하고 있다고 생각하고 있었는데 1957년 소련이 세계 최초 인공위성인 스푸트니크 1호를 발사하면서 엄청난 충격을 받게 된 사건이 역사상 첫번째 스푸트니크 모먼트가 되었다.
그 이후 미국은 다시 기술 패권을 찾을 수 있었다. DeepSeek이후 중국 AI는 다시 미국에 스푸트니크 모먼트를 제공하고 있다. 그 결론은 다시 미국을 포함한 서구권 AI 밸류체인의 승리로 귀결될까? 아니면 Will it be different this time?
그리고 그 안에서 LTO는 어떤 투자 기회를 찾을 수 있으며, 커버기업인 MDB의 성장성과 수익성에는 어떤 영향을 미칠지 고민해보겠다.
서구 vs. 중국 : AI 모델의 근본적인 차이와 전망
개발 모델의 차이: CAPEX 중심 vs. 비용 효율성
’25년 초 DeepSeek, 최근 Kimi K2 등 중국의 AI 모델들은 서구의 거대 AI 모델들과 비교해 극도로 저렴한 비용으로 유사한 성능을 보여주며 글로벌 AI 시장에 충격을 주고 있다. 이는 단순한 기술적 성과를 넘어, AI 개발과 상용화에 대한 근본적인 접근 방식의 차이를 드러내는 ‘스푸트니크 모트‘로 받아들여지고 있다.
서구와 중국의 AI 모델은 개발 철학, 비용 구조, 그리고 시장 전략에서 대조를 이루고 있으며, 이는 향후 AI 산업의 발전 방향과 투자 전략에 중대한 영향을 미칠 것으로 예상된다.
서구의 AI 모델은 대규모 CAPEX에 기반한 독점적이고 폐쇄적인 시스템을 구축하는 반면, 중국은 오픈소스를 활용하고 정부의 전략적 지원을 받아 비용 효율성을 극대화하는 개방적인 모델을 추구하고 있다. 이 두 모델의 충돌과 공존은 향후 수년간 AI 산업의 핵심 화제가 될 것이다.
서구 AI : 고비용 독점 모델
서구, 특히 미국의 AI 산업은 민간 기업을 중심으로 한 대규모 자본 투자(CAPEX) 중심의 개발 모델을 특징으로 한다.
OpenAI, Google, Microsoft, Meta 등 빅테크는 수십억 달러 규모의 자본을 투입하여 초대형 AI 모델을 개발하고, 이를 독점적으로 운영하고 있다. 이들은 고성능 GPU 클러스터, 대규모 데이터 센터, 그리고 최고 수준의 인재 확보에 막대한 비용을 지출하며, 이는 중국 기업들의 투자 규모를 크게 상회한다.
이러한 전략은 기술적 우위를 확보하고, 고성능 모델을 통해 시장을 선점하는 데 목적이 있다. 그러나 이는 동시에 AI 기술의 진입 장벽을 높이고, AI 서비스의 가격을 비싸게 만들어 중소기업이나 개발자들의 접근성을 제한하여 자본을 소유한 소수의 대기업과 고급 사용자에게 AI의 혜택을 집중시키는 결과를 낳을 수 있다.
중국 AI : 저비용 오픈소스 모델
중국의 AI 개발 모델은 서구와는 대조적으로, 비용 효율성과 오픈소스를 통한 생태계 확장에 초점을 맞추고 있다. (독재 정치 시스템을 갖고 있는 중국에서 오히려 더 분산적인 구조의 AI 모델이 발전하고 있다는 것이 아이러니하다)
중국 기술 기업들은 서구 기업들에 비해 상대적으로 적은 CAPEX로도 경쟁력 있는 AI 모델을 개발하는 데 성공하고 있다. 일부 분석가들은 중국의 대형 기술 기업들이 미국 기업들의 10분의 1 수준의 CAPEX만으로도 운영하고 있다고 지적한다.
이는 중국 기업들이 오픈소스 모델을 적극 활용하고, 커뮤니티 기반의 개발을 통해 비용을 절감하는 전략을 채택하고 있기 때문이다. 또한, 중국 정부의 전폭적인 지원과 대규모 데이터 보유, 다양한 응용 시나리오를 활용한 학습 등이 이러한 저비용 고효율 개발을 가능하게 하는 요인으로 작용하고 있다. 중국의 AI 모델들은 종종 오픈소스로 공개되어, 개발자들이 자유롭게 접근하고 활용할 수 있도록 하며, 이는 AI 기술의 빠른 확산과 다양한 응용 분야에서의 실험을 촉진하고 있다. 이러한 전략은 AI 기술의 대중화와 산업 전반의 AI 도입을 가속화시키며, 특히 개발 도상국이나 예산에 제약이 있는 기업들에게 매력적인 대안이 되고 있다.
Kimi K2와 DeepSeek의 사례 분석
중국 AI의 저비용 고성능 전략을 가장 잘 보여주는 사례는 Moonshot AI의 Kimi K2와 DeepSeek의 모델들이다.
이들 모델은 서구의 최첨단 AI 모델들과 비교해 뒤처지지 않는 성능을 보여주면서도, 훨씬 저렴한 가격으로 API를 제공하고 있어 글로벌 AI 시장의 주목을 받고 있다. 이들의 성공은 단순히 기술적 우수성을 넘어, 중국 AI 산업의 실행력을 보여주는 증거다.
Kimi K2는 초장문 맥락 이해 능력으로, DeepSeek는 오픈소스를 통한 빠른 기술 혁신으로 각각 주목받고 있으며, 이들은 중국 AI가 단순히 서구 기술을 모방하는 것이 아니라, 독자적인 혁신을 통해 경쟁력을 확보하고 있음을 입증하고 있다.
Moonshot AI가 개발한 Kimi K2는 1조 개 이상의 총 매개변수와 320억 개의 활성화 매개변수를 가진 대규모 언어 모델이다. 이 모델은 특히 ‘24.3월, 단일 대화에서 최대 200만 개의 중국어 문자를 처리할 수 있는 초장문 맥락 이해 능력으로 주목을 받았다. 이러한 성과는 의료, 교육, 고객 서비스 등 문서 중심의 업무에서 매우 실용적인 가치를 지닌다.
Kimi K2는 Mixture-of-Experts (MoE) 아키텍처를 채택하여, 전체 매개변수를 활용하는 것보다 훨씬 적은 계산 리소스로도 높은 성능을 달성할 수 있게 해준다. MoE 구조의 우수성과 서구 AI 모델이 이런 전략을 사용하지 않은 이유에 대해 Chat GPT에 분석을 요청하여 얻은 결과를 아래 공유한다.
Kimi K2의 MoE 구조와 비용 효율성: 서구권 LLM들과의 비교
Kimi K2와 MoE 모델 개요
중국 Moonshot AI가 2025년 공개한 Kimi K2는 약 1조 개의 매개변수를 갖춘 대화형 **대규모 언어 모델(LLM)**입니다intuitionlabs.ai. 이 모델의 가장 큰 특징은 MoE(Mixture of Experts), 즉 ‘전문가 혼합’ 구조를 채택했다는 점입니다. MoE란 하나의 거대한 신경망을 여러 개의 “전문가” 하위 모델로 나누고, 입력에 따라 일부 전문가만 활성화하여 응답을 생성하는 방식입니다medium.comblogs.nvidia.com. 다시 말해, 모든 질문에 모델의 모든 부분을 다 쓰지 않고, 관련된 부분만 선택적으로 사용합니다. 이는 사람이 뇌의 특정 영역만 사용하여 과제를 수행하는 것에 비유할 수 있습니다. 아래 그림에서처럼 MoE 모델은 입력에 따라 해당 분야 전문가들만 가동하고 나머지는 쉬게 하여, 불필요한 연산을 줄입니다blogs.nvidia.com. 이러한 스파스(sparse) 구조 덕분에, Kimi K2는 1조 개에 달하는 거대한 파라미터를 갖고 있음에도 매 토큰(token)마다 약 32억 개 정도의 파라미터만 활성화되는 효율성을 보입니다arxiv.org. (즉, 전체의 약 3%에 해당하는 파라미터만 사용됩니다.) 이는 Kimi K2가 384개의 전문가 네트워크를 갖추고, 그중 8개 전문가만 선택적으로 동작하도록 설계되었기 때문입니다intuitionlabs.ai.
MoE 모델의 개념도: 거대한 신경망을 여러 “전문가”로 나누고 입력마다 관련된 일부 전문가들만 활성화하는 구조를 보여준다. 뇌가 작업별로 특정 부위를 사용하는 것처럼, MoE 모델은 라우터(router)를 통해 매 토큰마다 최적의 전문가들을 골라낸다blogs.nvidia.com.
Kimi K2는 이러한 구조 덕분에 초록(context) 길이를 128k 토큰까지 지원하며, 복잡한 단계적 추론과 도구 활용에 특화된 에이전틱(agentic) 지능을 목표로 설계되었습니다intuitionlabs.ai. 예를 들어 여러 단계를 거쳐 계획을 세우고 도구를 호출하는 등, 단순 문장 답변을 넘어 자율적으로 사고하고 행동을 결정하는 능력을 키우려 한 것입니다. Kimi K2의 기본(pre-training) 모델은 이러한 에이전틱 AI 능력을 염두에 두고 방대한 데이터를 학습했으며, 이후 **지시 튜닝(Instruction Tuning)**과 자체 생성한 다단계 문제 해결 데이터로 추가 학습을 거쳐 대화형 임무에 최적화되었습니다intuitionlabs.ai.
Kimi K2 MoE 구조의 기술적 특징과 장점
Kimi K2의 MoE 구조에는 몇 가지 핵심 구조적 혁신과 기술적 장점이 있습니다:
효율적인 거대 모델 구현: MoE를 통해 규모와 효율성의 균형을 달성했습니다. Kimi K2는 총 1조 개의 파라미터로 거대한 모델이지만, 토큰 당 활성화되는 파라미터는 32억 개 수준이라서 사실상 300억 규모 모델처럼 동작합니다arxiv.org. 이는 동일 성능의 밀집(dense) 구조 모델 대비 계산량을 크게 줄이는 효과가 있습니다. 실제로 전체 모델 용량은 키우면서도 매 연산에 드는 비용을 줄였기 때문에, 거대한 모델을 기존 자원으로도 훈련시키고 활용할 수 있었습니다cameronrwolfe.substack.comblogs.nvidia.com.
전문가 분업으로 인한 특화 효과: MoE의 각 전문가 네트워크는 서로 독립적으로 학습되며 특정 입력 유형이나 작업에 특화될 수 있습니다medium.commedium.com. 예를 들어 어떤 전문가는 코드를 잘 처리하고, 다른 전문가는 창의적 글쓰기나 수학 문제에 능할 수 있습니다. 입력 질문이 들어오면 **게이팅 네트워크(라우터)**가 자동으로 관련 높은 전문가들을 선택하고 해당 부분만 계산을 수행합니다medium.commedium.com. 이렇게 하면 모델 전체를 모두 동원하는 경우보다 더 정확하고 풍부한 응답을 낼 수 있습니다. Kimi K2의 경우 이러한 구조로 코딩, 추론, 수학 등 여러 분야에서 최고 수준의 성능을 보이며, 일부 영역에서는 GPT-4나 GPT-5 같은 폐쇄형 최첨단 모델들을 능가하기도 합니다intuitionlabs.ai. 실제 보고에 따르면, Kimi K2의 지시-튜닝 버전은 코드 생성 테스트에서 GPT-4.1을 능가하고(패스@1 기준 53.7% vs 44.7%), 고난도 벤치마크 시험(“Humanity’s Last Exam”)에서도 GPT-5를 앞서는 점수를 기록했습니다 (K2 44.9% vs GPT-5 41.7%)intuitionlabs.ai. 이러한 성과는 MoE 구조가 성능을 희생하지 않으면서도 효율을 높일 수 있음을 입증합니다.
안정적인 초대규모 학습 기법: 1조 파라미터나 되는 거대 MoE 모델을 학습하려면 기존 방법으로는 학습 불안정성 문제가 컸는데, Kimi K2 팀은 이를 해결하는 전용 최적화기를 도입했습니다. 예를 들어 MuonClip이라는 새로운 옵티마이저를 사용하여 15.5조 토큰이라는 막대한 데이터로 사전학습을 시키면서도 학습 손실 폭발이나 불안정 현상 없이 안정적으로 진행할 수 있었다고 합니다intuitionlabs.ai. 특히 QK-Clip이라는 가중치 클리핑 기법을 적용해, 초거대 모델에서 발생하는 그래디언트 폭주를 억제했다고 합니다intuitionlabs.ai. 그 결과 Kimi K2는 1조 규모 학습에서도 손실 스파이크가 한 번도 없이 끝까지 훈련을 마쳤다고 보고되었습니다arxiv.orgarxiv.org. 이는 그만큼 MoE 구조에서의 대규모 학습 안정화 기술을 확보했음을 의미합니다.
실용적인 긴 맥락 처리와 툴 사용: Kimi K2는 맥락 길이를 128K 토큰까지 확장하여, 아주 긴 문서나 대화도 한 번에 처리할 수 있습니다intuitionlabs.ai. 또한 다양한 툴(예: 계산기, 코딩 인터프리터 등)을 다단계로 호출하며 문제를 해결하도록 훈련된 에이전트형 데이터로 튜닝되어, 수백 단계에 걸친 연속 작업도 논리 흐름을 유지하며 수행할 수 있습니다intuitionlabs.ai. 독립 평가에 따르면 Kimi K2는 300회 이상의 연속적인 툴 호출도 문맥을 잃지 않고 이어갈 정도로 긴 추론에 강인함을 보였습니다intuitionlabs.ai. 이런 능력은 일반적인 LLM보다 복잡한 시나리오 처리나 자율 에이전트 실행에 유리합니다.
경량화 및 배포 용이성: MoE 구조라고 해서 반드시 복잡한 장비가 필요한 것은 아닙니다. Kimi K2 팀은 양자화(quantization) 기법을 적용해 모델을 4비트 정밀도로 압축하면서도 성능 저하를 최소화했습니다intuitionlabs.ai. 그 결과 Kimi K2의 추론 모델은 4비트 정밀도로도 원래와 유사한 품질을 내며, 덕분에 상대적으로 적은 GPU 자원으로도 구동이 가능합니다. 실제 보도에 따르면 Kimi K2는 최신형 애플 M3 Ultra GPU 두 장만으로도 초당 15 토큰 정도의 생성 속도를 낼 수 있다고 하니, 이 정도면 개인 개발자가 고사양 PC로 시험해볼 수도 있는 수준입니다intuitionlabs.ai. 또한 Kimi K2는 오픈 소스로 공개되어(변형 MIT 라이선스) 누구나 모델 가중치를 내려받아 활용할 수 있기 때문에, 연구자나 기업들이 저렴한 비용으로 최첨단 AI를 활용해볼 수 있게 했다는 점도 큰 장점입니다intuitionlabs.aiintuitionlabs.ai.
MoE 구조의 비용 효율성 분석
Kimi K2가 주목받는 가장 큰 이유 중 하나는 뛰어난 비용 효율성입니다. 앞서 언급했듯, MoE 모델은 계산 자원을 절약하면서도 거대 모델의 이점을 얻을 수 있는 구조입니다. Dense(밀집) 모델에서는 입력 하나를 처리할 때 매번 모델의 모든 파라미터를 연산해야 합니다. 예컨대 GPT-3처럼 175억 파라미터 짜리 모델이면 질문 하나에 175억 개 모두를 계산에 사용합니다. 반면 MoE 모델에서는 거대한 전체 파라미터 중 필요한 일부만 활성화하지요medium.commedium.com. Kimi K2의 경우 1조 개 중 32억 개 정도(약 3%)만 사용하므로, 사실상 32억짜리 모델을 돌리는 정도의 연산비용만 들게 됩니다arxiv.org. 이러한 선택적 계산(conditional computation) 덕분에 성능 대비 비용 효율이 훨씬 높습니다. NVIDIA의 분석에 따르면, 최첨단 MoE 모델들은 동일 하드웨어에서 밀집 모델 대비 최대 10배 빠른 속도로 작동하며, 토큰당 비용을 1/10 수준으로 절감할 수 있다고 합니다blogs.nvidia.comblogs.nvidia.com. 이는 곧 같은 돈으로 10배 더 많은 추론 작업을 처리하거나, 동일한 연산으로 더 똑똑한 모델을 활용할 수 있다는 뜻입니다.
이 비용 상의 이점은 실제 사례에서도 확인됩니다. **Kimi K2 팀은 약 4백만 달러(한화 50억 원 남짓)**의 비교적 적은 예산으로 이 1조 파라미터 모델의 학습을 완료했다고 알려져 있습니다pub.towardsai.net. 놀랍게도 이렇게 훈련된 Kimi K2는 세계 최고 수준으로 꼽히는 GPT-5 수준의 모델과 어깨를 나란히 하거나 일부는 앞서는 성능을 냈습니다pub.towardsai.netintuitionlabs.ai. 반면 GPT-4나 GPT-5와 같은 모델을 개발한 서구권 기업들은 수천억 원 규모의 투자와 초대형 데이터센터 인프라가 필요했다고 전해지죠. 예를 들어 OpenAI의 GPT-4 모델은 **학습에만 수천만 달러(추정 약 7천8백만 달러)**가 소요된 것으로 추산되고cybolink.com, 구글의 차세대 Gemini 모델은 훈련 비용이 1억 9천만 달러에 달했다는 보고도 있습니다cybolink.com. 이를 감안하면, Kimi K2는 경쟁 모델 대비 10분의 1 이하 비용으로 비슷한 성능을 구현해낸 셈입니다. 실제로 한 애널리스트는 Kimi K2의 혁신을 가리켜 “불과 1%의 비용으로 실리콘밸리를 이겼다”고 평했는데pub.towardsai.net, 이는 과장이 아니라 그만큼 MoE 구조가 경제성 면에서 파괴적인 임팩트를 보여줬다는 의미일 것입니다.
또한 추론(서비스) 비용 측면에서도 MoE 모델은 유리합니다. 한 보고에 따르면 Kimi K2를 활용해 복잡한 코딩 작업 하나를 완료하는 데 드는 비용이 **약 0.5위안(한화 100원 미만, $0.07 정도)**에 불과했다고 합니다intuitionlabs.ai. 반면 동일한 작업을 폐쇄형 상용 모델 API로 시도하면 수십 배 이상 비용이 들 수 있습니다 (예: 한 폐쇄 모델은 백만 토큰당 약 $3 달러, 즉 비슷한 작업에 몇 달러의 비용 추산)intuitionlabs.ai. 결국 MoE 기반 Kimi K2는 한 번 답변을 생성하는 데 들어가는 계산량과 금전적 비용 모두 매우 저렴하며, 이는 사용자들이 낮은 비용으로 고성능 AI 서비스를 이용할 수 있음을 뜻합니다. 특히 Kimi K2처럼 오픈소스로 공개된 MoE 모델은 클라우드 API 사용료 없이 자체 서버나 로컬 환경에 올려 운용할 수도 있으므로, 기업 입장에서 장기 운용 비용을 크게 절감할 잠재력이 있습니다intuitionlabs.aiintuitionlabs.ai.
정리하면, MoE 구조의 기술적 장점은 다음과 같이 요약할 수 있습니다:
연산 효율 증대: 필요할 때만 일부 모델 파라미터를 사용하므로, 토큰당 연산량이 감소되어 응답 속도와 비용 면에서 유리합니다blogs.nvidia.com.
전문가의 전문성 활용: 여러 전문가 네트워크가 각기 다른 지식/능력을 담고 있어, 한 모델에 다양한 분야의 최적화된 지능을 동시에 갖출 수 있습니다.
확장성과 유연성: 전문가 수를 늘리는 방식으로 비교적 쉽게 모델 용량을 키울 수 있어 확장성이 좋습니다arxiv.org. 또한 일부 전문가만 수정/재학습하는 식의 모듈식 업데이트도 잠재적으로 가능합니다.
비용 접근성: 연구팀이나 중소기업도 비교적 적은 예산으로 최첨단 모델을 학습/활용할 수 있는 길을 열어줍니다. 실제로 Kimi K2의 사례에서 수십 배 비용 절감 효과가 입증되었습니다pub.towardsai.netcybolink.com.
서구권 LLM들과의 비교: 왜 MoE를 선택하지 않았나?
한편, OpenAI나 Google 같은 서구권 주요 AI 플랫폼들은 지금까지 Kimi K2와 같은 극단적인 MoE 구조를 적극 도입하지 않고, 주로 **대규모 자본 지출(CAPEX)**을 통한 하드웨어 투자를 바탕으로 성능을 끌어올리는 전략을 취해왔습니다. 예컨대 GPT-5.2 (OpenAI의 차세대 GPT 시리즈)나 Google의 Gemini 3.0 같은 모델들은 내부 구조를 상세히 공개하진 않았지만, 업계 관측에 따르면 수백억~천억 개 이상의 파라미터를 지닌 거대 모델을 밀집 구조로 운용하고 있는 것으로 보입니다. 이들은 모델 구조 혁신보다는 막대한 컴퓨팅 자원 투입으로 성능을 확보하는 경향이 있습니다cybolink.comcybolink.com. 실제로 OpenAI는 GPT-4 등을 개발하면서 마이크로소프트 애저 클라우드에 수십억 달러 규모의 연산 리소스를 투입했고, 2024년 한 해에만 추론 서비스 비용으로 120억 달러 이상을 지출했다는 보도도 있습니다theregister.com. 구글 역시 자체 AI 모델들을 위해 대규모 **TPU 팟(pod)**과 데이터센터 증설에 아낌없이 투자해 왔습니다. 다시 말해, 서구 빅테크들은 충분한 자본력과 인프라를 지렛대 삼아 모델을 키우고 돌리는 방식을 선택한 것입니다.
이러한 “브루트포스(Brute-force)형” 접근을 택한 이유는 몇 가지로 분석됩니다:
자본 및 인프라의 여유: OpenAI나 구글 같은 기업들은 일찌감치 수십억 달러의 투자를 유치하고 거대한 데이터센터를 확보했습니다. 돈과 자원이 넉넉하다 보니, 새로운 아키텍처를 모색하기보다는 검증된 밀집 모델을 더 크게, 더 많이 돌리는 것이 현실적이었습니다. 예를 들어 GPT-3에서 GPT-4로 갈 때 모델 파라미터 수와 학습 데이터량을 대폭 늘리고, 그에 맞춰 슈퍼컴퓨터 급 하드웨어를 증설하는 식으로 성능을 끌어올렸습니다cybolink.comcybolink.com. 이는 기술적 모험을 줄이고도 최고 성능을 달성할 수 있는 길이기도 했습니다. 기업 입장에서는 확실한 방법에 자본을 투입해 단기간에 목표 성능에 도달하는 것이, 새로운 구조를 탐색하다 실패하는 위험을 지는 것보다 낫다고 판단한 것입니다.
MoE 구조의 복잡성과 성숙도 문제: MoE 자체는 새로운 개념은 아니지만(구글이 2021년 Switch Transformer 등을 통해 선도적으로 연구한 바 있음medium.com), 이를 상용 대규모 모델에 안정적으로 적용하는 데에는 어려움이 많았습니다. MoE 모델을 훈련/서빙하려면 여러 GPU에 전문가들을 분산시키고, 매 토큰마다 동적으로 통신하여 결과를 합쳐야 하는데, 이는 소프트웨어 최적화부터 하드웨어 연결까지 해결해야 할 난관들이 존재합니다blogs.nvidia.comblogs.nvidia.com. NVIDIA 역시 “MoE 모델을 실제 제품 수준으로 확장하는 것은 악명 높게 어렵다(notoriously difficult)”고 지적하면서, 이를 위해서는 하드웨어-소프트웨어의 극한 최적화가 필요하다고 밝혔습니다blogs.nvidia.com. 다시 말해, 빅테크들이 MoE를 채택하지 않은 한 가지 이유는 구현과 운영의 복잡성입니다. 실제로 OpenAI GPT-4의 경우도 내부적으로 일부 MoE 기법을 활용했을 가능성이 거론되지만medium.com, OpenAI는 정확한 구조를 공개하지 않았고, 안정성 문제 등으로 완전한 MoE 모델을 내세우지는 않은 것으로 추정됩니다. 기업들은 수백 명의 엔지니어 팀으로도 촉박한 일정에 모델을 만들어야 하다 보니, 상대적으로 보수적인 선택을 한 것으로 볼 수 있습니다. (한 스타트업 관계자도 “MoE 모델 학습은 정말 어렵다. 우리는 수많은 과학적·성능상의 도전과제를 겨우 극복하며 파이프라인을 구축했다”고 밝힌 바 있는데cameronrwolfe.substack.com, 이처럼 MoE는 전문 지식과 노하우가 필요한 어려운 길입니다.)
품질 및 일관성에 대한 고려: 새로운 MoE 구조가 항상 기존 밀집 모델보다 나은 품질을 보장하는 것은 아니며, 특히 미세조정(파인튜닝)이나 RLHF(인간 피드백 강화학습) 단계에서 제어가 까다로울 수 있습니다. 여러 전문가로 나뉘어 있다 보니 학습이 고르게 이루어지지 않으면 특정 전문가에 지식 편중이 생기거나, 응답 생성 시 예측 불가능한 변동성이 나타날 수 있다는 지적도 있었습니다. 예를 들어 MoE 모델은 내부에 다양한 전문가들이 경쟁하듯 상호작용하기 때문에, 동일한 입력에도 비결정론적(non-deterministic) 결과를 낼 가능성이 더 높다는 분석도 제기되었습니다152334h.github.io. 반면 단일 거대 모델은 하나의 거대한 분포를 학습하므로 상대적으로 출력이 일관되고 튜닝하기 용이할 수 있습니다. OpenAI나 구글이 초창기에는 밀집 모델로도 충분한 성능을 끌어낼 자신이 있었고, 그 거대한 모델을 사람 피드백으로 직접 미세조정하면서 안정적인 성능 확보에 집중한 것으로 보입니다. 요컨대, 일정 수준 이상 자원이 있다면 검증된 방식을 통해 안전하게 고품질 모델을 만드는 게 유리하다고 판단한 것입니다.
데이터 및 생태계 측면: 서구권 거대 모델들은 단순히 모델 아키텍처뿐만 아니라 훈련 데이터의 양과 질, 그리고 후처리 기법 등에서도 강점을 지니고 있습니다. 예를 들어 OpenAI는 인터넷 전체를 아우르는 방대한 텍스트에 더해, 인간 전문가들이 레이블링한 정제된 데이터와 피드백을 통해 모델을 조율합니다. 이렇게 얻은 지식의 풍부함과 응답의 세련됨이 경쟁 우위인데, 이는 부분적으로 모델 크기 덕분에 담을 수 있는 정보량과 후처리 단계의 투자 덕분입니다. MoE 구조를 도입하면 모델 자체는 효율적이지만, 결국 데이터가 부족하면 성능이 제한되기 마련입니다. 서구권 기업들은 여전히 “더 큰 모델+더 많은 데이터” 전략을 주된 무기로 삼았고, 이 접근을 뒷받침하기 위해 자본을 데이터 수집과 인프라에 투입해온 것입니다. 반면 중국을 비롯한 다른 플레이어들은 방대한 공개 데이터 접근이나 인적자원 측면에서 핸디캡이 있기에, 모델 구조 혁신을 통한 차별화에 무게를 실었다고도 볼 수 있습니다.
독점 기술 및 모방 우려: 마지막으로, 서구권 리더들이 MoE 구조를 기피한 이유 중 하나는 기술 모방에 대한 견제심리일 수 있습니다. MoE 모델의 개념과 구현법은 학계와 오픈소스 커뮤니티를 통해 비교적 공유되기 쉬운 편입니다. 만약 OpenAI가 GPT-4부터 대놓고 MoE를 전면 도입했다고 가정해보면, 그 개념 자체는 새로운 것이 아니므로 다른 경쟁자들도 비슷한 구조를 따라하면서 빠르게 추격할 가능성이 있습니다. 그러나 초거대 밀집 모델을 막대한 자본으로 학습하는 방식은 따라하려 해도 웬만한 기업이나 연구소는 엄두를 낼 수 없는 진입장벽이 됩니다. 즉, **“돈의 장벽”**을 세움으로써 경쟁 우위를 지키는 측면도 있었던 것이죠. 실제로 GPT-4 수준의 모델을 새로 개발하려면 수천억 원대의 투자와 전문 인력, 그리고 수년간 축적된 노하우가 필요해 쉽게 모방할 수 없습니다. 반면 Kimi K2가 시연한 MoE 접근법은 비용 면에서는 문턱이 낮지만, 기술적 구현력이 필요하다는 점에서 또 다른 장벽이 있습니다. Kimi K2 팀이 공개한 보고서를 보면, 1조 파라미터 MoE를 훈련하기 위해 256대 이상의 GPU를 병렬로 연결하고arxiv.orgarxiv.org, 체크포인팅과 통신을 최적화하는 복잡한 분산 시스템을 개발해야 했습니다arxiv.orgarxiv.org. 이러한 시스템 엔지니어링 역량과 알고리즘 혁신 없이는 단순히 MoE 아이디어만 안다고 해서 따라 만들기 어렵습니다. 요컨대, 서구권은 자본 장벽, Kimi K2는 기술 장벽으로 각자의 모방 난이도를 높인 양상이라고 할 수 있습니다.
결론 및 시사점
Kimi K2의 등장은 초거대 언어모델 개발 패러다임에 중요한 물음을 던졌습니다. 과거에는 최고 성능의 AI를 얻으려면 천문학적 비용의 연산 자원 투입이 불가피하다고 여겨졌지만, Kimi K2는 창의적인 모델 구조 설계와 효율화로 비용 장벽을 크게 낮출 수 있음을 보여주었습니다pub.towardsai.netcybolink.com. MoE 구조의 스케일-효율 트레이드오프 극복은 연구 공동체와 업계에 모델 대형화의 새로운 길을 제시했고, 실제로 최근에는 개방형 LLM들 중 상당수가 MoE를 채택하며 급속히 발전하고 있습니다blogs.nvidia.comblogs.nvidia.com. 반면 여전히 OpenAI, 구글 등 거대 기업들은 자체 자본과 인프라를 바탕으로 한 정공법으로 차세대 모델을 밀어붙이고 있으며, 이는 단기간 내 최고의 성능을 끌어내는 데 유효한 전략입니다. 다만 이 접근법은 막대한 비용 구조를 수반하기에, 상용 서비스의 채산성이나 AI 기술의 민주화 측면에서 제약이 있다는 지적도 나오고 있습니다theregister.com.
향후에는 이 두 흐름이 서로 수렴할 가능성도 있습니다. 즉, MoE와 같은 효율적 아키텍처를 점진적으로 도입하면서도, 여전히 막대한 훈련 데이터와 튜닝 기법을 활용하는 혼합 전략이 등장할 수 있습니다. 이미 구글의 Gemini 모델 일부 버전에 MoE 아이디어가 접목되고 있다는 보고가 있고ibm.combdtechtalks.substack.com, OpenAI도 비용 절감을 위해 다양한 최적화를 모색 중인 것으로 알려져 있습니다. 결국 핵심은 “지능 대비 비용”을 얼마나 낮추느냐인데, Kimi K2가 보여준 바와 같이 새로운 발상과 과감한 설계가 있다면 거대한 자본 없이도 최첨단 AI를 달성할 수 있음을 우리는 목격했습니다. 이는 국내외 많은 연구자와 기업들에게 효율적인 AI 연구개발의 중요성을 환기시켰고, AI 기술의 접근성 확대라는 긍정적 효과도 가져왔습니다. 앞으로도 이러한 MoE 모델의 발전과 기존 방식의 경쟁을 주시함으로써, 더 뛰어나면서도 모두가 활용하기 쉬운 AI를 향한 길이 열리길 기대해 봅니다.
이러한 효율적인 설계는 Kimi K2의 운영 비용을 크게 절감시켜, 이를 API 가격에 반영할 수 있게 했습니다. Kimi K2의 API 가격은 OpenAI의 GPT-4에 비해 약 10분의 1 수준으로 알려져 있어, 개발자들에게 매력적인 대안이 되고 있습니다. 또한, Kimi K2는 코드 생성, 디버깅, 최적화 등 AI 코딩 분야에서 국내 최고 수준의 성능을 보이며, 복잡한 작업을 자동으로 분해하고 실행할 수 있는 강력한 Agent 구축 능력을 제공합니다. 이러한 기술적 우수성과 경제적 이점의 결합은 Kimi K2가 중국 AI 시장을 넘어 글로벌 시장에서도 주목받는 이유입니다.
DeepSeek: 오픈소스 모델의 경쟁력
DeepSeek는 또 다른 중국 AI 스타트업으로, 오픈소스 모델을 통해 빠르게 기술력을 쌓고 있다. DeepSeek의 모델은 오픈소스 커뮤니티를 통해 활발히 개발되고 있으며, 이는 기술의 빠른 반복과 개선을 가능하게 한다. DeepSeek의 모델들은 코딩, 수학, 논리적 추론 등에서 높은 성능을 보여주며, 특히 DeepSeek-v3-0324 모델은 Kimi K2와의 비교에서도 경쟁력 있는 성과를 거두었다.
DeepSeek의 전략은 기술의 민주화와 AI 생태계의 확장에 기여하며, 이는 중국 AI가 단순히 기술 추종자가 아니라, 혁신적인 개발 모델을 통해 글로벌 AI 시장에서 독자적인 위치를 구축하고 있음을 보여준다. DeepSeek의 오픈소스 접근법은 개발자들이 모델을 자유롭게 활용하고 개선할 수 있도록 하여, AI 응용 분야의 다양성과 창의성을 촉진하고 있다. 이는 중국 AI가 기술적 우수성뿐만 아니라, 생태계 구축과 커뮤니티 기반의 혁신을 통해 지속 가능한 경쟁력을 확보하고 있음을 뜻한다.
근본적 차이의 원인 : 기업 vs. 정부 주도
서구와 중국의 AI 개발 모델이 이렇게 극단적으로 다른 방향으로 발전할 수 있었던 근본적인 원인은 두 지역의 AI 산업을 주도하는 주체의 차이에서 찾을 수 있다.
서구는 민간 기업, 특히 대형 기술 기업들이 AI R&D와 투자를 주도하는 반면, 중국은 정부가 전략적 목표 하에 AI 산업을 체계적으로 육성하고 지원하는 체계를 구축하고 있습니다. 이러한 주도권의 차이는 AI 개발의 속도, 방향, 그리고 최종 목표에 있어서 명확한 차이를 만들어내고 있으며, 향후 AI 경쟁의 양상을 결정짓는 핵심 요인이 될 것이다.
서구 : 민간 기업 중심의 투자와 R&D
서구의 AI 산업은 OpenAI, Google, Microsoft, Meta 등과 같은 민간 기업들이 주도한다.
이들 기업은 주주 이익 극대화를 목표로 하며, AI 기술을 통해 새로운 수익원을 창출하고 기존 사업을 강화하는 데 초점을 맞추고 있다. 이러한 민간 주도의 개발 모델은 시장의 수요와 기술의 가능성에 따라 빠르게 반응하고, 혁신적인 제품과 서비스를 출시하는 데 강점을 가지고 있다.
그러나 동시에, AI 개발은 수익성과 관련된 단기적 성과에 집중될 수 있으며, 장기적이고 기초적인 연구에는 상대적으로 소홀할 수 있는 한계가 있다.
민간 기업들은 AI 기술을 독점적으로 보유하고, 시장 지배력을 확보하려는 경향이 있어, AI 기술의 민주화와 보편적 혜택 실현에는 제약이 있을 수 있다.
즉, 서구의 AI 개발은 기업의 전략적 선택과 시장의 논리에 따라 움직이기 때문에, AI의 사회적, 윤리적 측면에 대한 고려가 상대적으로 부족할 수 있다.
중국 : 정부 주도의 전략적 투자와 생태계 조성
중국의 AI 산업은 정부가 전략적으로 주도하고 있다. 중국 정부는 ‘차세대 AI 발전 계획’ 등을 통해 AI를 국가 핵심 전략 산업으로 육성하고, 막대한 자금과 정책적 지원을 아끼지 않고 있다. ‘25년 한 해에만 중국은 AI에 8900억 위안(약 1250억 달러)을 투자했으며, 이는 전년 대비 18% 증가한 수치다. 특히, 정부의 직접 지원이 3450억 위안(39%)으로, 정부의 역할이 매우 크다. Top 50+ Chinese AI Investment Statistics [2025] | Second Talent
중국 정부는 AI 기초 연구, 인프라 구축, 산업 융합, 인재 양성 등 AI 밸류체인 전반에 걸쳐 체계적인 지원을 하고 있으며, 이는 중국 AI가 빠르게 성장할 수 있는 원동력이 된다. 또한, 중국 정부는 AI 기술을 사회 전반에 걸쳐 확산시켜, 스마트 시티, AI+제조업, AI+의료 등 다양한 응용 분야에서 AI를 활용하는 데 적극적이다.
AI 발전 방향에 미치는 영향
서구와 중국의 이러한 근본적인 개발 모델의 차이는 향후 AI 산업의 발전 방향에도 큰 영향을 미칠 것으로 예상된다.
서구는 기술 우위를 유지하고, 고급 시장을 집중 공략하는 전략을 지속할 가능성이 높으며, 중국은 대규모 상용화와 다양한 응용 분야의 확장을 통해 AI 산업의 규모와 영향력을 키워나갈 것으로 보인다.
이러한 두 가지 전략의 충돌과 공존은 향후 AI 산업의 지형도를 재편할 것이며, 투자자들에게는 새로운 기회와 도전을 동시에 제시할 것이다.
서구: 기술적 우위 유지와 고급 시장 집중
서구의 AI 기업들은 고성능 GPU, 첨단 반도체 설계, 그리고 기초 AI 알고리즘 등 AI 밸류체인의 상류에서의 기술적 우위를 유지하는 데 집중할 것으로 예상된다. NVIDIA, AMD, Intel 등의 미국 기업들은 세계 최고 수준의 AI 칩 설계 기술을 보유하고 있으며, 이는 서구 AI가 지속적인 경쟁력을 확보할 수 있는 핵심 요소다.
OpenAI, Anthropic, Google 등은 기초 모델 개발에서 여전히 선두를 달리고 있으며, 이들은 고성능 AI 모델을 통해 엔터프라이즈 솔루션, 의료, 금융 등 고부가가치 시장을 공략하는 전략을 지속할 것이다.
서구 AI는 정확성, 투명성, 안정성을 중시하는 분야, 예를 들어 제약, 은행, 정부 기관 등에서 강점을 가질 것으로 보이며, 이들 분야는 높은 수익성과 규제 준수를 요구하기 때문에 서구 AI의 고급화 전략과 부합한다.
그러나, 중국 AI의 저비용 공세가 지속될 경우, 서구 AI는 점차 가격 경쟁력에서 밀리고, 상대적으로 좁은 시장에 집중될 수 있다는 리스크도 존재한다.
중국: 대규모 상용화와 응용 분야 확장
중국의 AI 산업은 정부의 전략적 지원과 대규모 내수 시장을 바탕으로 AI 기술의 대규모 상용화와 다양한 응용 분야로의 확장을 가속화할 것으로 예상된다. 중국은 이미 AI+제조업, AI+의료, AI+금융, AI+에너지 등 다양한 산업 분야에서 AI를 적극적으로 도입하고 있으며, 이는 AI 기술의 가치를 검증하고, 산업 전반의 생산성을 향상시키는 데 기여하고 있다. 중국의 AI 모델들은 낮은 비용과 높은 활용성을 바탕으로, 소매, 소비재, 미디어 등 B2C 서비스 분야에서 강점을 가질 것으로 보인다.
또한, 중국은 AI 기술을 스마트 시티, 정부 플랫폼 등에 통합하여, AI를 일상 생활에 밀접하게 연결하는 데 성공하고 있다. 이러한 대규모 상용화 전략은 AI 기술의 보급을 가속화하고, AI 산업의 규모를 빠르게 키워나가는 데 효과적이다. 향후 중국은 AI 기술의 독자적인 표준을 확립하고, 글로벌 AI 시장에서 미국과 양분하는 독자적인 생태계를 구축할 가능성이 높다.
AI 밸류체인 분석 : 서구와 중국의 각축장
AI 산업은 Upstream(반도체, 클라우드 인프라), Midstream(AI 알고리즘, LLM), Downstream(AI 응용 서비스, 소프트웨어)으로 구성된 복잡한 밸류체인을 형성하고 있다.
서구와 중국은 이 밸류체인의 각 단계에서 서로 다른 강점과 약점을 가지고 있으며, 이는 두 지역의 AI 경쟁 양상을 결정짓는 핵심 요인이다.
서구는 상류의 반도체와 기초 연구에서 강점을 가지는 반면, 중국은 하류의 응용 분야와 대규모 데이터, 시장 규모에서 우위를 점하고 있습니다. 이러한 밸류체인별 경쟁 구도는 향후 AI 산업의 가치 창출 구조와 주요 기업들의 협상력 변화에 큰 영향을 미친다.
상류는 AI 시스템의 하드웨어적 기반을 제공하는 계층으로, 반도체 칩, 클라우드 인프라, 데이터 센터 등이 포함된다. 중류는 AI 시스템의 소프트웨어적 핵심인 AI 알고리즘, 기계 학습 프레임워크, 대형 언어 모델(LLM) 등으로 구성된다. 하류는 AI 기술이 실제로 적용되는 응용 서비스와 소프트웨어로, AI 챗봇, 자율주행, 스마트 팩토리, AI 기반 의료 진단 등 다양한 분야에 걸쳐 있다.
세 계층은 서로 긴밀하게 연결되어 있으며, 각 계층의 발전이 전체 AI 산업의 성장에 기여한다.
상류 : 반도체, 클라우드 인프라
AI 밸류체인의 상류는 AI 시스템이 작동하기 위한 물리적 기반을 제공한다. 이 계층에는 AI 연산을 수행하는 데 핵심적인 반도체 칩(특히 GPU), 대규모 데이터를 저장하고 처리하는 클라우드 인프라, 그리고 데이터 센터가 포함된다. 이 계층은 막대한 자본 투자와 첨단 기술이 요구되며, 높은 수익성을 보장한다.
NVIDIA, AMD, Intel 등의 미국 기업들이 설계에서 강점을 가지고 있으며, 대만의 TSMC와 한국의 삼성이 제조에서 주도권을 가지고 있다.
중국은 이 분야에서 미국의 수출 규제에 직면해 있지만, Huawei, Cambricon 등의 기업을 통해 자체 반도체 개발에 박차를 가하고 있으며, 동시에 희토류 등 반도체 제조에 필요한 핵심 소재의 공급에서 전략적 우위를 확보하고 있다.
중류 : AI 알고리즘, LLM
AI 밸류체인의 중류는 AI 시스템의 ‘두뇌’에 해당하는 계층으로, AI 알고리즘, 기계 학습 프레임워크, 대형 언어 모델(LLM)이 이에 속한다. 이 계층은 AI 기술의 핵심적인 혁신이 일어나는 곳으로, 기술적 난이도가 높고, 연구 개발 역량이 중요하다.
중류 계층은 AI 산업에서 혁신과 산업 가치 측면에서 가장 중요한 부문으로, 이 분야의 경쟁력이 전체 AI 산업의 경쟁력을 결정짓는 핵심 요소다.
미국은 OpenAI, Google, Anthropic 등이 GPT, Gemini, Claude 등의 선도적인 LLM을 개발하며, 이 분야에서 기술적 우위를 유지하고 있다.
중국은 Baidu, Alibaba, Tencent 등의 대기업과 Moonshot AI, DeepSeek 등의 스타트업이 빠르게 추격하고 있으며, 특히 중국의 방대한 데이터와 다양한 응용 시나리오를 활용한 학습을 통해, 서구 모델들과의 기술 격차를 빠르게 좁히고 있다.
하류 : AI 응용 서비스, 소프트웨어
AI 밸류체인의 하류는 AI 기술이 실제로 우리의 삶과 산업에 적용되는 부문이다. AI 챗봇, 자율주행 자동차, 스마트 팩토리, AI 기반 의료 진단, 개인화된 콘텐츠 추천 등 다양한 응용 서비스와 소프트웨어가 이에 해당한다. 이 계층은 AI 기술의 상용화와 보급을 결정짓는 가장 중요한 분야로, 시장 규모와 성장 잠재력이 매우 크다. (개인적으로는 이 분야가 결국 가장 많은 부가가치를 가져가게 될 것이라 생각한다)
중국은 방대한 인구와 다양한 산업 구조를 바탕으로, 이 분야에서 매우 빠른 성장을 보이고 있다. 특히 스마트 홈, 자율주행, AI 기반 도시 관리 시스템 등에서 중국은 선도적인 위치를 차지하고 있으며, AI 응용 서비스의 대규모 상용화에 성공하고 있다.
서구와 중국의 주요 기업 분석
서구와 중국의 AI 밸류체인에는 각각 강력한 기업들이 포진하고 있으며, 이들은 각자의 전략과 강점을 바탕으로 AI 경쟁에서 주도권을 확보하려 하고 있다. 서구는 NVIDIA, OpenAI, Google, Microsoft 등이 하드웨어, 기초 모델, 클라우드 인프라에서 강력한 영향력을 가지고 있는 반면, 중국은 Alibaba, Tencent, Baidu, Huawei, 그리고 Moonshot AI, DeepSeek 등의 신생 강자들이 정부의 전략적 지원을 등에 업고 빠르게 성장하고 있다.
구분
서구 주요 기업
중국 주요 기업
상류 (인프라)
NVIDIA (GPU), AMD, Intel (반도체 설계)
Huawei (Ascend 칩), Cambricon (AI 칩 설계)
중류 (모델)
OpenAI (GPT), Google (Gemini), Anthropic (Claude)
Moonshot AI (Kimi K2), DeepSeek, Alibaba (Qwen), Baidu (Ernie)
NVIDIA는 AI 연산에 필수적인 GPU 시장의 절대강자로, 세계 AI 인프라의 핵심을 제공한다. OpenAI는 GPT 시리즈를 통해 생성형 AI의 새로운 지평을 열었으며, 고성능 LLM 개발의 선두 주자로 자리잡았다. Google은 DeepMind를 비롯한 자체 AI 연구소를 통해 AI 기초 연구에서 선도적인 역할을 하고 있으며, Gemini 모델을 통해 OpenAI와 경쟁하고 있다. Microsoft는 OpenAI와의 전략적 파트너십을 통해 Azure 클라우드에 AI 기능을 통합하며, 엔터프라이즈 AI 시장에서 강력한 입지를 구축하고 있다.
이들 기업은 막대한 자본과 인재, 그리고 축적된 기술력을 바탕으로 AI 밸류체인의 상류와 중류에서 강력한 경쟁력을 보유하고 있다.
중국: Alibaba, Tencent, Baidu, Huawei, Moonshot AI
중국 AI 산업은 대기업과 스타트업이 협력하며 빠르게 성장하고 있다.
Alibaba는 전자상거래와 클라우드 사업을 바탕으로 AI 기술을 다양한 분야에 적용하고 있으며, Moonshot AI 등 AI 스타트업에 전략적 투자를 하며 AI 생태계를 구축하고 있다. Tencent는 소셜 미디어와 게임 사업을 통해 축적한 데이터와 기술력을 바탕으로 AI를 개발하며, 특히 AI+제조업 분야에 집중하고 있다. Baidu는 중국의 대표적인 AI 기업으로, 자율주행, 음성 인식, LLM 등 다양한 AI 분야에서 선도적인 역할을 하고 있다. Huawei는 AI 칩 개발에 집중하며, 미국의 수출 규제에 대응하며 중국 AI 산업의 자립을 위한 핵심 기업으로 성장하고 있다. Moonshot AI와 DeepSeek 등의 스타트업은 Kimi K2, DeepSeek-v3 등의 혁신적인 모델을 개발하고 있다.
밸류체인별 협상력
AI 밸류체인의 각 계층에서는 서로 다른 기업들이 협상력을 가지고 있으며, AI 트렌드가 심화될수록 이러한 협상력의 균형은 변화할 것으로 예상된다. 현재는 상류의 반도체 기업들이 막대한 협상력을 가지고 있지만, 향후 AI 기술이 보편화되고, 응용 분야의 중요성이 커질수록 하류의 AI 소프트웨어 및 서비스 기업들의 협상력이 강화될 것이다.
현재 : 상류 반도체 기업의 지배력
현재 밸류체인에서 가장 큰 협상력을 가지고 있는 것은 상류의 반도체 기업들, 특히 NVIDIA다. AI 모델의 학습과 추론에 필수적인 고성능 GPU를 독점적으로 공급하고 있는 NVIDIA는 전 세계 AI 기업들이 그들의 제품 없이는 AI 개발을 할 수 없을 정도로 막강한 영향력을 가지고 있습니다
미국의 수출 규제로 인해 중국 기업들이 NVIDIA의 최신 GPU를 구하기 어려운 상황은, 반도체가 AI 산업에서 얼마나 전략적인 자원인지를 보여주는 단적인 예다.
상류 기업들의 지배력은 AI 산업의 초기 단계에서는 당연한 현상이지만, AI 기술이 성숙해지고, 소프트웨어와 응용 분야의 중요성이 커질수록 점차 약화될 수 있다.
협상력의 변화 : 하류 응용 분야의 부상
AI 트렌드가 심화되고, AI 기술이 보편화될수록, 밸류체인의 협상력은 상류에서 하류로 이동할 것으로 예상된다. AI 기술 자체가 차별화 요소가 아니라, AI를 어떻게 활용하느냐, 어떤 가치를 창출하느냐가 더 중요해질 것이기 때문에 AI를 활용한 혁신적인 서비스와 응용 프로그램을 개발하는 하류 기업들이 점차 더 높은 협상력을 가지게 될 것이다.
AI를 활용해 의료 진단의 정확도를 높이는 기업, 자율주행 기술을 상용화하는 기업, 개인화된 교육 서비스를 제공하는 기업 등은 AI 기술을 실질적인 가치로 전환시키는 역할을 하기 때문에, 시장에서 더 높은 평가를 받을 수 있다.
또한, 소비자가 직접 비용을 지불하는 B2C AI 서비스가 성장함에 따라, 사용자 경험과 브랜드, 마케팅 역량이 중요해지며, 이는 하류 기업들의 협상력을 강화하는 요인이 될 것입니다.
소비자 직접 지불 모델의 협상력
AI 산업의 지속 가능한 성장을 위해서는, 기업이나 정부의 보조금이 아닌, 소비자가 직접 비용을 지불하는 AI 소프트웨어 응용 분야가 활성화되어야 한다. 이러한 B2C AI 서비스는 AI 기술의 실질적인 가치를 검증하고, AI 기업들의 수익성을 보장하는 데 핵심적인 역할을 한다.
AI 소프트웨어 응용 분야의 성장
AI 소프트웨어 응용 분야는 AI 기술이 실제로 우리의 일상과 산업에 스며들어, 새로운 가치를 창출하는 분야다.
AI 기반의 개인 비서, 창의적인 콘텐츠 생성 도구, 스마트 홈 제어 시스템, 개인화된 건강 관리 앱 등은 소비자들이 직접 비용을 지불할 만한 충분한 가치를 제공할 수 있다. 이러한 응용 분야는 AI 기술의 보편화와 함께 폭발적인 성장을 할 것으로 예상되며, 이는 AI 산업의 새로운 성장 동력이 될 것이다. 특히, 중국은 내수 시장이 크고 중국 정부도 내수 주도 경제성장을 추구하고 있어 AI 소프트웨어 응용 분야에서 세계적인 강자로 성장할 잠재력을 가지고 있다.
B2C AI 서비스의 경쟁력
B2C AI 서비스는 AI 기술의 최종 수혜자인 소비자들에게 직접적인 가치를 제공하는 서비스다. 이러한 서비스는 AI 기술의 복잡성을 소비자가 쉽게 이해하고 활용할 수 있도록 하는 것이 핵심이며, 사용자 경험, 편의성, 개인화된 기능이 중요한 경쟁 요소가 된다.
중국의 AI 기업들은 WeChat, Taobao 등의 플랫폼을 통해 AI를 일상 생활에 밀접하게 통합하고 있으며, 이는 중국 AI가 B2C 시장에서 강력한 경쟁력을 가질 수 있는 기반을 마련한다.
향후 B2C AI 서비스는 AI 산업의 주요 수익원이 될 것이며, 이 분야에서의 경쟁력은 AI 기업의 지속 가능한 성장을 결정짓는 핵심 요소가 될 수밖에 없다.
AI 경쟁 시나리오 분석과 가능성 예측
서구와 중국의 AI 경쟁은 단순한 기술 경쟁을 넘어, 경제, 정치, 군사 등 다양한 측면에서 전개되는 전면적인 경쟁이다.
경쟁의 미래는 여러 가지 시나리오로 전개될 수 있으며, 각 시나리오의 가능성을 예측하는 것은 AI 관련 투자 전략을 수립하는 데 매우 중요하다.
중국 AI의 저비용 고성능 전략이 성공적으로 이어진다면, 중국이 AI 트렌드에서 확고한 우위를 차지하는 시나리오가 실현될 수 있으며, 반대로 서구가 수출 통제를 통해 중국 AI의 성장을 억제하는 시나리오도 가능하다. 또한, 두 진영이 서로 다른 강점을 인정하고, 공존하며, 협력하는 하이브리드 모델도 현실적인 대안이 될 수 있다.
시나리오
가능성
핵심 근거
주요 리스크
중국 AI의 지배적 우위
중간
– 저비용 고성능 모델의 경쟁력 – 대규모 데이터와 정부 지원
– 기술 격차 존재 – 반도체 의존 (미국 수출 규제)
서구-중국 AI의 공존
높음
– 하이브리드 AI 전략 (기업별 맞춤형 사용) – 기술 교류의 필요성 (글로벌 이슈 해결) – 글로벌 기업들의 중국 AI 활용 사례
– 지정학적 긴장의 심화 – 기술 표준의 분화
서구의 기술 통제로 중국 AI 축소
낮음
– 반도체 수출 규제 – 기술 봉쇄 정책
– 중국의 자체 기술 개발 (Huawei 등) – 중국의 막대한 내수 시장
중국 AI의 지배적 우위 (가능성: 중간)
중국 AI가 저비용, 대규모 데이터, 정부의 전폭적인 지원을 바탕으로 서구 AI를 앞서며, AI 트렌드에서 확고한 우위를 차지하는 시나리오다. 이 경우, 중국은 AI 기술의 표준을 주도하고, 글로벌 AI 시장을 장악하며, 서구 AI는 점차 시장 점유율을 잃고, 축소되는 상황에 직면하게 됩니다.
비용 경쟁력은 AI 기술의 대중화와 산업 전반의 AI 도입을 가속화시킬 것이다. 또한, 중국은 방대한 인구와 다양한 산업에서 생성되는 대규모 데이터를 보유하고 있으며, 정보보호 규제가 낮은 수준으로 거의 제한없이 데이터를 활용할 수 있어, AI 모델의 학습과 고도화에 유리한 조건을 가지고 있다. 무엇보다도, 중국 정부의 전략적이고 체계적인 지원은 중국 AI 산업의 지속 가능한 성장을 보장하는 가장 강력한 원동력이다.
이러한 요인들이 결합된다면, 중국 AI가 단기간에 글로벌 시장에서 지배적인 위치를 차지하는 것이 가능해질 수 있다.
리스크: 기술 격차, 반도체 의존
그러나 이 시나리오에는 몇 가지 리스크가 존재한다. 첫째, 아직까지는 서구 AI 모델, 특히 OpenAI의 최신 모델과 비교했을 때, 중국 AI 모델이 약간의 기술적 격차를 보이고 있다. 격차가 빠르게 좁혀지고 있지만, 완전히 해소되지는 않았다.
둘째, 중국 AI 산업은 여전히 고성능 AI 칩, 특히 NVIDIA의 GPU에 상당히 의존하고 있다. 미국의 수출 규제가 지속된다면, 중국 AI 산업의 성장에 병목 현상이 발생할 수 있다. 중국이 자체 반도체 기술을 빠르게 개발하고 있지만, 아직까지는 서구 수준에 도달하지 못했기 때문에, 이는 중국 AI의 지속적인 성장에 불확실성을 더하는 요소다.
서구-중국 AI의 공존 (가능성: 높음)
서구와 중국이 각자의 강점을 살려, 서로 다른 영역에서 경쟁하며 공존하는 시나리오다. 서구는 기술적 우위를 바탕으로 고급 시장을, 중국은 저비용을 바탕으로 대중 시장을 공략하는 형태로 발전할 수 있다.
하이브리드 AI 전략, 기술 교류
서구와 중국의 AI 경쟁이 극단적인 대립 양상으로 치닫지 않고, 공존의 방향으로 발전할 수 있는 근거는 여러 가지가 있다.
첫째, 하이브리드 AI 전략의 가능성이다. 많은 글로벌 기업들이 서구 AI와 중국 AI를 병행하여 사용하는 전략을 취할 가능성이 높다. 예를 들어, 고성능이 필요한 연구 개발에는 서구 AI를, 일반적인 상용 서비스에는 중국 AI를 활용하는 방식이다. 이는 기업들의 비용을 절감하면서도, AI 기술의 활용도를 극대화할 수 있는 전략이다.
둘째, 기술 교류의 필요성이다. AI는 기후 변화, 질병 치료, 에너지 문제 등 지구적 문제를 해결할 수 있는 잠재력을 가진 기술로, 서구와 중국의 AI 기술이 협력하고, 기술 교류를 활성화해야 한다는 공동의 이해관계는 서구-중국 AI의 공존을 가능하게 하는 중요한 요인이 될 수 있다.
Nestlé, Starbucks의 중국 AI 활용
일부 글로벌 기업들은 이미 중국의 AI 기술을 활용하기 시작했다. 예를 들어, Nestlé, Starbucks 등은 중국의 AI 기술을 활용해 고객 데이터를 분석하고, 마케팅 전략을 수립하는 등의 활동을 하고 있다.
이는 중국의 AI 기술이 이미 상업적으로 충분한 가치를 지니고 있음을 보여주는 사례이며, 향후 더 많은 글로벌 기업들이 중국 AI를 활용할 가능성이 있음을 시사한다. 이러한 사례들은 서구와 중국의 AI가 단순한 경쟁 관계를 넘어, 협력과 공존의 가능성도 열어두고 있음을 보여준다.
서구의 기술 통제로 중국 AI 축소 (가능성: 낮음)
서구권이 반도체 수출 규제, 기술 봉쇄 등을 통해 중국의 AI 발전을 억제하고, 중국 AI가 축소되는 시나리오다.
반도체 수출 규제, 기술 봉쇄
서구권, 특히 미국은 이미 중국에 대한 반도체 수출 규제를 시행하고 있으며, 이는 중국의 AI 발전에 큰 제약이 되고 있다.
고성능 AI 칩이 없으면, 대규모 AI 모델의 학습과 고성능 AI 서비스의 제공이 어려워진다. 또한, 서구권은 AI 관련 핵심 기술과 소프트웨어에 대한 중국의 접근을 제한하는 기술 봉쇄 정책도 시행하고 있다. 기술 통제가 강화된다면, 중국 AI의 발전은 상당히 둔화될 수 있다.
중국의 자체 기술 개발, 역내수요
그러나 서구의 기술 통제가 중국 AI를 완전히 축소시킬 가능성은 낮다. 첫째, 중국의 자체 기술 개발이다. 중국은 Huawei 등 국내 기업을 통해 자체 AI 칩과 소프트웨어를 개발하는 데 막대한 투자를 하고 있으며, 언젠가는 서구 수준의 기술력을 갖추게 될 가능성이 높다.
둘째, 역내수요다. 중국은 14억 인구를 가진 내수 시장을 보유하고 있다. 내수 시장만으로도 중국 AI 기업들은 충분한 성장 동력을 확보할 수 있으며, 서구 시장에 대한 의존도를 줄일 수 있다. 따라서 서구의 기술 통제가 중국 AI를 완전히 멈추게 하기는 어려울 것으로 예상된다.
중국 AI 밸류체인내 MongoDB의 위치와 전망
MongoDB는 NoSQL DBaaS(Database-as-a-Service) 시장의 선두 주자로, AI 시대의 데이터 관리 수요 증가에 따라 중요한 역할을 하고 있다. 다만, 시나리오에 따라서는 중국의 AI 밸류체인에서 MongoDB의 위치와 전망 분석이 투자 결정에 있어 중요한 요소가 될 수 있다.
MongoDB의 현재 : 데이터 인프라 핵심 기업
MongoDB는 유연한 문서 기반 데이터 모델과 강력한 확장성을 바탕으로, AI 애플리케이션 개발에 적합한 데이터베이스로 주목받고 있다. AI는 다양하고 비정형적인 데이터를 처리해야 하며, MongoDB의 스키마리스(Schema-less) 구조는 이러한 AI의 요구사항을 충족시키는 데 탁월하다.
중국 AI 밸류체인에서 MongoDB의 역할
MongoDB는 중국의 AI 밸류체인에서도 중요한 역할을 하고 있습니다. 중국의 주요 클라우드 기업들과의 전략적 파트너십을 통해, 중국 시장에 진출하며, 중국의 AI 애플리케이션 개발에 핵심적인 데이터베이스로 활용되고 있다.
Tencent Cloud, Alibaba Cloud와의 전략적 파트너십
MongoDB는 Tencent Cloud, Alibaba Cloud 등 중국의 주요 클라우드 기업들과 전략적 파트너십을 맺고 있다. 이를 통해 MongoDB는 중국 내에서 안정적인 서비스를 제공할 수 있으며, 중국의 개발자들에게 익숙한 환경에서 MongoDB를 사용할 수 있게 해준다. 이러한 파트너십은 MongoDB가 중국 시장에서의 입지를 강화하고, 중국의 AI 생태계에 깊숙이 통합되는 데 기여하고 있다.
VolcEngine (ByteDance)과의 협업
MongoDB는 ByteDance의 클라우드 서비스인 VolcEngine과의 협업을 통해, 중국의 AI 밸류체인에서 핵심적인 역할을 하고 있다.
VolcEngine은 MongoDB를 “AI 데이터 베이스”로 포지셔닝하며, 다양한 AI 애플리케이션에 MongoDB를 활용하고 있다. 예를 들어, ByteDance의 AI 챗봇 ‘豆包’ 는 MongoDB를 활용해 실시간 음성 대화의 컨텍스트를 관리하며, AI 캐릭터 플레이 앱 ‘猫箱’ 은 MongoDB를 활용해 AI 캐릭터의 기억을 저장하고 검색한다.
이러한 사례들은 MongoDB가 중국의 AI 애플리케이션 개발에 실질적으로 활용되고 있음을 입증한다.
MongoDB의 미래 전망
MongoDB의 중국 AI 밸류체인에서의 미래는 세 가지 시나리오로 전개될 수 있다. 대체 가능성, 나름의 영역 유지, 그리고 지배적 사업자로의 성장이다.
대체 가능성 : 중국 내국산 DBMS (신창)
MongoDB가 중국에서 대체될 수 있는 가장 큰 리스크는 신창(信创) 정책이다.
신창은 ‘정보 기술 응용 혁신’을 의미하며, 중국 정부가 주도하는 국내 IT 산업 보호 및 육성 정책이다. 이 정책의 핵심은 정부 기관, 공공 기관, 그리고 중요한 산업 분야에서 외국 기술 대신 중국 자체의 기술과 제품을 사용하도록 장려하는 것이다. 이는 MongoDB와 같은 외국 데이터베이스 기업들에게는 중대한 도전이다. 신창 정책에 따라, 많은 중국 기업들이 외국 데이터베이스 솔루션 대신 국내에서 개발된 대체품을 선택해야 하는 압력을 받고 있다.
이는 MongoDB가 중국의 핵심 산업이나 정부 프로젝트에 진입하는 것을 어렵게 만든다.
나름의 영역 유지 : 파트너십을 통한 시장 진입
비록 신창 정책과 같은 도전에 직면하고 있지만, MongoDB는 Tencent Cloud와 같은 현지 파트너들과의 전략적 협력을 통해 중국 시장에서 나름의 영역을 유지하고 확장할 수 있다. Tencent Cloud와의 파트너십은 MongoDB에게 중국 시장에 진입할 수 있는 중요한 통로를 제공한다. 협력을 통해 MongoDB는 Tencent의 광범위한 고객 기반과 클라우드 인프라를 활용할 수 있으며, 이는 MongoDB가 독자적으로 달성하기 어려운 수준의 시장 침투를 가능하게 한다.
또한, MongoDB는 AI 시대에 맞춰 지속적으로 제품을 혁신하고 있으며, 이는 중국 시장에서의 경쟁력을 강화하는 데 기여한다. MongoDB는 Atlas Vector Search와 같은 AI 네이티브 기능을 도입하여, AI 애플리케이션의 핵심 요구사항인 벡터 검색을 지원하고 있으며, 이러한 기술적 혁신은 MongoDB가 단순한 데이터 저장소를 넘어, AI 애플리케이션의 핵심 인프라로 진화하고 있어 다른 중국 회사의 DBaaS로 쉽게 대체되기 어렵다는 근거를 제공한다.
지배적 사업자로의 성장 : AI 네이티브 기능 강화
MongoDB가 중국 AI 밸류체인에서 지배적 사업자로 성장하기 위해서는 AI 네이티브 기능을 지속적으로 강화하고, AI 애플리케이션의 핵심 데이터 플랫폼으로 자리 잡는 것이 중요하다. MongoDB는 이미 이 방향으로 나아가고 있으며, AI 검색 및 검색 기능을 데이터베이스 레이어로 가져오는 것을 목표로 하고 있다. 이미 알고 있는 것처럼, Voyage AI의 인수는 이 전략의 핵심 부분이었다. 기술 통합을 통해 MongoDB는 개발자들이 별도의 시스템을 관리하거나 외부 API를 사용하지 않고도, MongoDB 내에서 고품질의 임베딩을 생성하고, 벡터 검색을 수행하며, 결과를 재순위 매길 수 있도록 한다.
이러한 종합적인 전략을 통해 MongoDB는 단순한 NoSQL 데이터베이스를 넘어, AI 시대의 핵심 데이터 플랫폼으로 진화하고 있으며, 이는 중국을 포함한 글로벌 시장에서 지배적 사업자로 성장할 수 있는 강력한 기반을 제공한다.
중국 AI DBaaS 투자 기회 : MDB 투자 리스크 보완
중국 AI 데이터베이스 시장의 특징
중국의 AI 데이터베이스 시장은 서구와는 다른 독특한 특징을 가지고 있다. 전통적으로 MySQL, PostgreSQL과 같은 오픈소스 관계형 데이터베이스가 중심이었지만, AI 시대의 도래와 함께 AI-Ready 및 AI-Native 데이터베이스로의 전환이 빠르게 진행되고 있다.
이는 중국 AI DBaaS 시장이 매우 역동적이며, 새로운 투자 기회를 제공하고 있음을 의미한다.
MySQL, PostgreSQL 중심의 생태계
중국의 데이터베이스 시장은 오랜 기간 동안 MySQL, PostgreSQL과 같은 오픈소스 관계형 데이터베이스가 중심이었다.
이는 중국의 많은 인터넷 기업들이 초기에 오픈소스 솔루션을 채택하여 빠르게 성장할 수 있었기 때문이다. 전통적인 데이터베이스들은 트랜잭션 처리와 정형 데이터 관리에 강점을 가지고 있지만, AI 시대의 비정형 데이터, 대규모 확장성, 그리고 유연한 스키마 요구사항에는 한계를 보이고 있다.
그러나 이미 구축된 방대한 생태계와 개발자들의 익숙함 때문에, 여전히 중국 시장에서 중요한 위치를 차지하고 있다.
AI-Ready 및 AI-Native로의 전환
AI 시대의 도래와 함께, 중국의 데이터베이스 시장은 AI-Ready 및 AI-Native로의 전환을 가속화하고 있다.
AI-Ready 데이터베이스는 기존의 데이터베이스에 AI 기능을 추가하거나, AI 애플리케이션과의 통합을 강화한 것을 의미한다. 예를 들어, 관계형 데이터베이스에 벡터 검색 기능을 추가하거나, AI 모델의 학습 데이터를 효율적으로 제공하는 기능을 강화하는 것이 이에 해당한다.
AI-Native 데이터베이스는 AI 애플리케이션의 요구사항에 맞춰 처음부터 설계된 데이터베이스로, 벡터 데이터베이스가 대표적인 예다.
이러한 전환은 중국의 AI DBaaS 시장이 매우 빠르게 진화하고 있으며, 새로운 기술과 비즈니스 모델이 등장할 수 있는 기회의 장을 제공하고 있다.
5.2. 주요 투자 후보 기업 분석
중국의 AI DBaaS 시장은 빠르게 성장하고 있으며, MongoDB를 보완하거나 대체할 수 있는 다양한 투자 기회를 제공한다.
중국의 주요 클라우드 서비스 제공업체들은 AI에 최적화된 데이터베이스 서비스를 개발하고 있으며, 이는 중국의 AI 밸류체인에서 중요한 역할을 한다. 또한, 벡터 데이터베이스와 같은 AI 네이티브 데이터베이스를 전문으로 하는 스타트업들도 주목할 만하다. 이러한 기업들은 중국의 AI 발전에 맞춰 특화된 솔루션을 제공하며, 빠른 성장 잠재력을 가지고 있다.
Alibaba Cloud: Lindorm, Tair, DashVector
Alibaba Cloud는 중국의 AI DBaaS 시장에서 가장 중요한 플레이어 중 하나다. Alibaba Cloud는 AI에 최적화된 다양한 데이터베이스 서비스를 제공하며, 이는 중국의 AI 밸류체인에서 핵심적인 역할을 한다. 그들의 데이터베이스 포트폴리오는 Lindorm, Tair, 그리고 DashVector와 같은 제품들을 포함한다. Lindorm은 HBase와 호환되는 고도로 최적화된 NoSQL 데이터베이스로, 높은 처리량과 동시성을 요구하는 시나리오에 적합하다. Tair는 Alibaba Cloud의 인메모리 데이터베이스 서비스로, 매우 낮은 지연 시간을 요구하는 애플리케이션에 적합하다. DashVector는 Alibaba Cloud의 벡터 데이터베이스 서비스로, AI 애플리케이션의 핵심 요구사항인 의미 검색 및 유사성 검색을 지원한다.
Tencent Cloud : X-Stor, MongoDB 파트너십
Tencent Cloud는 중국의 AI DBaaS 시장에서 또 다른 핵심 플레이어다. 그들은 자체 개발한 멀티모델 NoSQL 데이터베이스인 X-Stor를 통해 독특한 경쟁력을 확보하고 있다. X-Stor는 그래프, 와이드 컬럼, 문서, 시계열 등 다양한 데이터 모델을 하나의 시스템에서 처리할 수 있도록 설계되었다. 이는 Tencent가 소셜 네트워크, 비디오 스트리밍, 온라인 게임 등 다양한 서비스를 운영하면서 발생하는 복잡한 데이터 관리 요구사항을 해결하기 위해 개발되었다. 또한, Tencent Cloud는 MongoDB와의 전략적 파트너십을 통해 중국의 AI DBaaS 시장에서 강력한 입지를 구축하고 있다.
Huawei Cloud : GeminiDB, Document Database Service
Huawei Cloud는 중국의 AI DBaaS 시장에서 기술 자립을 추구하는 대표적인 기업입니다. 그들은 자체 개발한 GeminiDB를 통해 NoSQL 데이터베이스 서비스를 제공하며, 이는 MongoDB와 같은 문서 데이터베이스의 기능을 제공합니다.
GeminiDB는 고성능, 고가용성, 그리고 강력한 보안 기능을 자랑하며, 특히 정부, 금융, 통신 등 엔터프라이즈급 시장에서 강점을 가지고 있다. 또한, Huawei Cloud는 Document Database Service를 제공하여, MDB API와 호환되는 서비스를 제공함으로써, 기존 MDB 사용자들이 쉽게 전환할 수 있도록 지원한다.
Huawei는 “신창” 정책의 수혜를 입는 대표적인 기업으로, 중국의 AI DBaaS 시장에서 중요한 역할을 할 것으로 예상된다.
Zilliz : Milvus 벡터 데이터베이스
Zilliz는 중국의 AI DBaaS 시장에서 AI 네이티브 데이터베이스를 전문으로 하는 대표적인 스타트업이다. 그들의 핵심 제품인 Milvus는 오픈소스 벡터 데이터베이스로, AI 애플리케이션의 핵심 요구사항인 고차원 벡터 데이터의 효율적인 저장 및 검색을 전문으로 한다.
Milvus는 의미 검색, 이미지 검색, 추천 시스템, 그리고 생성형 AI 애플리케이션에서 중요한 역할을 한다. Zilliz는 Milvus를 기반으로 Zilliz Cloud라는 완전 관리형 DBaaS를 제공하며, 이는 기업들이 벡터 데이터베이스의 복잡한 운영 및 유지보수 없이도 AI 애플리케이션을 개발하고 운영할 수 있도록 한다. Zilliz는 Alibaba Cloud와 같은 주요 클라우드 서비스 제공업체들과의 협력을 통해 중국의 AI 생태계에서 중요한 역할을 하고 있다.
5.3. 투자 전략 제안
중국 AI의 급부상과 AI 산업의 빠른 변화는 투자자들에게 새로운 기회와 도전을 제시하고 있다. MDB에만 투자하는 것은 서구 AI가 축소되는 시나리오하에서 리스크가 있을 수 있으므로, 중국의 AI DBaaS 기업들을 포트폴리오에 추가하는 것을 고려해볼 수 있다. 이는 리스크를 분산시키고, 중국 AI의 성장에 따른 수익을 기대할 수 있는 전략이다.
포트폴리오 다각화 : MDB와 중국 기업 병행 투자
MDB와 중국의 AI DBaaS 기업들을 병행 투자하는 것은 AI 산업의 불확실성에 대응하는 효과적인 전략이다. MDB는 글로벌 시장에서의 선도적인 위치와 기술력을 바탕으로, 서구 AI가 지속적으로 성장하는 시나리오에서 수익을 창출할 수 있다.
반면, 중국의 AI DBaaS 기업들은 중국의 막대한 내수 시장과 정부의 전략적 지원을 바탕으로, 중국 AI가 지배적인 위치를 차지하는 시나리오에서 높은 성장 잠재력을 가지고 있다. 따라서, 이 두 가지 투자를 병행함으로써, 어느 시나리오가 실현되더라도 포트폴리오의 안정성을 확보할 수 있다.
HTAP, 다모달, 데이터 플랫폼 관심
AI 시대의 데이터베이스는 단순한 데이터 저장소를 넘어, HTAP(Hybrid Transactional /Analytical Processing), 멀티모달(Multimodal), 데이터 플랫폼으로 진화하고 있다.
HTAP는 트랜잭션 처리와 분석 처리를 하나의 시스템에서 수행할 수 있도록 하여, 실시간 AI 애플리케이션의 성능을 향상시킨다.
멀티모달은 텍스트, 이미지, 비디오 등 다양한 형태의 데이터를 처리할 수 있도록 하여, AI 애플리케이션의 범위를 확장시킨다.
데이터 플랫폼은 데이터베이스, 데이터 레이크, 데이터 분석 등 다양한 데이터 관리 기능을 통합한 플랫폼으로, AI 개발의 생산성을 높인다.
투자자들은 이러한 기술 트렌드에 주목하고, 이를 구현하고 있는 기업들에 투자하는 것을 고려해야한다.
가치투자 커뮤니티를 성장시켜나가고 있습니다. 운영 계획과 방향성을 한 번 읽어보시고, 텔레그램과 유튜브 채널을 통해 소통하고 있으니 공감이 가신다면 참여해주세요! 쌍방향 소통을 원하는 분들은 카카오톡 채널로 와 주시면 좋을 거 같습니다. 자료실을 통해 리포트, 뉴스도 공유하고 있으니 참고하시면 도움이 될 거 같습니다.
점점 자동번역이 보편화되고 있지만, 그럴수록 높은 품질로, 오류 없이 작성된 언어간 번역의 쌍, 말뭉치의 중요성은 오히려 높아지고 있다.
더 높은 정확도로 빠른 시간 안에 번역 서비스를 제공하기 위해 필요한 것이 정확하게 정의된 표준에 따라 작성된 말뭉치이다.
기계와 알고리즘에만 의존하게 되면 위와 같이 맥락에 맞지 않는 결과물을 얻게 된다. 우리야 웃어넘길 수 있지만 더 정확한 의미 전달이 필요할수록, 그리고 신뢰하고 사용할 필요성이 클수록 ‘사람이 맥락을 정확히 정의해놓은 데이터’의 중요성이 더욱 커진다.
Flitto는 그런 정확한 데이터를 파는 기업이다. 이 BM이 정확히 어떤 가치를 발생시키며, 다른 기업이 진입하기 힘든 이유를 파악하는 것이 투자의 전제가 된다는 점에서 지금 작성하는 Flitto에 대한 최초 분석 글의 많은 부분은 정확한 BM을 이해하는데 할애하려고 한다.
Flitto의 매출
세부 매출 비중
플리토의 매출은 크게 1) AI 학습용 언어 데이터 판매, 2) 플랫폼 서비스, 3) AI 통·번역 솔루션 세 부문으로 나뉜다.
매출의 약 3/4을 차지하는 데이터 판매 사업은 Flitto가 집단지성을 활용해 수집·가공한 다국어 병렬 말뭉치(언어쌍 데이터)를 글로벌 기업 등에 판매하는 사업 모델이다.
플랫폼 서비스는 플리토의 번역 앱/웹 플랫폼에서 발생하는 매출로, 개인 사용자들의 번역 의뢰나 콘텐츠 이용 등에 따른 수익이며 약 15~25% 비중을 차지한다.
AI 솔루션 부문은 플리토가 자체 개발한 실시간 통·번역 엔진을 이벤트 행사나 기업 고객에 제공하여 올리는 매출로, 최근 수년간 새롭게 성장한 분야이며 약 5~8% 수준이다.
매출 단위
“기업 고객들이 더 큰 규모의 데이터를 발주했다”는 말은 고객사들이 AI 학습용 언어 데이터의 주문량을 늘렸다는 의미다. 처음에는 소규모 데이터 샘플을 제공받은 고객이 결과에 만족하여 점차 더 많은 양의 말뭉치(언어 데이터 세트)를 요구하게 되었다는 것이다.
한 글로벌 IT 기업(A사)은 초기에 Flitto로부터 소규모 번역 말뭉치를 받아본 뒤 만족하여 이후 계약 규모를 54억 원, 67억 원, 42억 원으로 계속 확대하며 추가 발주를 했다. 여기서 발주 혹은 판매의 “단위”는 특정 프로젝트별 데이터 양으로 보면 된다. 즉 몇 문장이나 단어 등 말뭉치의 분량을 단위로 계약하는 것이 일반적이며, 이를 금액으로 환산하여 계약 규모를 결정한다.
기업 입장에서는 필요한 언어쌍의 문장쌍 데이터를 수십만~수백만 문장 등 분량으로 발주하며, 플리토 같은 업체는 그에 맞춰 데이터를 수집·가공해 납품한다. 계약된 데이터는 그 프로젝트 범위 내에서 일회성으로 제공되지만, 만족한 고객은 이후 더 큰 용량이나 추가 언어의 데이터를 추가 발주하게 되어 계약 규모가 커진 것이다.
그리고 시점이 경과하게 되면 사용하는 언어, 문체가 변하기 때문에 동일한 카테고리에 해당되는 언어쌍도 업데이트가 필요하게 되며, 그러한 수요에 기반하여 반복 매출이 발생하게 된다.
언어쌍 데이터의 품질
AI 학습용 언어 말뭉치에도 품질의 차이가 존재한다. 데이터의 출처와 정제 수준, 그리고 추가 가공 여부에 따라 저품질과 고품질로 나눌 수 있다.
초기에는 단순 수집 및 정제만 거친 비교적 기본적인 병렬 말뭉치를 제공했다면, 최근에는 레이블링(Labeling) 등 추가 정보가 붙은 고품질 언어 데이터를 요구하는 추세다.
플리토 경영진은 “초기에는 단순 데이터 수집·정제에 그쳤으나 최근에는 레이블링 등이 적용된 고품질 언어 데이터를 요구하고 있다”고 밝혔다.
여기서 고품질이란 문장이 문법적으로 정확하고 오탈자나 번역 오류가 없으며, 필요하다면 문장별 메타정보나 도메인 태그(레이블)가 붙은 데이터를 말한다. 기업들은 AI 모델 성능 향상을 위해 이런 정교하게 가공된 말뭉치를 선호하며, 품질에 따라 데이터도 등급화된다.
고품질 병렬 코퍼스(말뭉치)는 기계번역 성능 향상에 매우 중요하다는 연구 결과도 있다. 플리토도 수요 변화에 맞춰 특정 분야(도메인)별 전문 용어가 포함된 데이터셋을 전문 인력 검수를 거쳐 구축하는 등 데이터 품질을 높이는 방향으로 가공하여 서비스를 고도화하고 있다.
최근 5년 매출 추이
’18년 매출 35억원에 불과하던 플리토는 사업모델 특례상장 이후 일시적인 부진(’19년 매출 20억원)을 겪었으나, 이후 매출이 가파르게 증가했다.
특히 ’20년부터 AI 학습용 데이터 수요가 폭발하면서 ’22년 178억원, ’23년에는 203억원으로 창사 이래 최고 매출을 기록했고, ‘25.3Q 누적 매출만 258억원으로 전년 대비 75% 급증하여 폭발적 성장세를 이어가고 있다. 매출 급성장과 함께 ’24년 첫 연간 흑자를 달성했고, ’25년에도 분기 연속 흑자를 이어가고 있다.
데이터 판매 부문은 최근 5년 성장을 주도했다. ’19년 매출의 76%였던 데이터 판매 비중은 지속적으로 75% 안팎을 유지하며 성장을 견인했다. ‘23년 매출 203억 중 약 150억 원 이상이 데이터 판매에서 발생했고, ’25년 상반기에도 매출 139억 중 75%가 데이터 판매였다.
플랫폼 서비스 매출도 사용자층 확대로 절대액은 증가했으나 데이터 사업 급성장에 비해 완만한 성장률을 보여 비중이 감소했다.(’18년 24% → ’25.상반기 17.7%) 수준으로 낮아졌다.
AI 통·번역 솔루션은 ’21년 시작되어 ’23년 약 6%(10억원 수준)으로 성장했고, 최근 출시한 챗 트랜스레이션(Chat Translation) 등의 기여로 빠른 성장세를 보여, ’25년에는 대형 국제행사 공급 등으로 분기 매출 20억 원대까지 증가했다.
매출 증가 요인 : 고객 수 vs ARPU
데이터 판매 부문의 고성장은 기존 거래처의 주문 확대(고객당 매출 증가)와 신규 고객 확보가 모두 기여했다.
플리토는 애플, 메타 등 해외 빅테크로부터 처음에는 소규모 샘플 공급을 시작했으나 만족한 고객이 갈수록 더 큰 규모의 데이터를 발주하여 단일 고객 매출이 누적 164억원에 달할 만큼 거래 규모가 커졌다.
이처럼 주요 고객당 매출(ARPU)이 크게 상승한 것도 데이터 사업 성장의 원인이지만, 동시에 ’23~’25년 사이 신규 글로벌 IT기업들과도 잇따라 계약을 체결(예: ‘23.3월 67억원, 10월 42억원 수주)하며 고객 풀 자체도 확대되었다.
플랫폼 서비스의 경우 불특정 다수 소비자를 대상으로 하는 만큼 이용자 수와 사용량 증가가 매출 증대의 핵심이었다. 플리토는 전세계 1,400만 가입자 기반을 확보하고 있으며, 그중 적극적인 참여자 증가와 콘텐츠 이용 확대로 플랫폼 매출이 늘었다. 개인 이용자 플랫폼에서는 ARPU 개념이 크지 않고 소액 결제나 광고 등 수익모델이기 때문에, 전체 이용자 규모 확대가 매출 증대로 직결되었다.
솔루션 사업은 초기에는 국내외 몇몇 행사를 대상으로 시작했으나 ’23년 부산 BIFF 포럼, APEC 등 공급처가 다양화되었다([i-point]플리토, 3분기 어닝 서프라이즈… 매출·이익 ‘껑충’) 즉 솔루션 고객 수가 늘어난 것이 매출 성장 요인이 되었다. 하지만 동시에 행사 당 계약금액(ARPU)도 대형 행사일수록 커져 평균 단가도 상승했다.
플리토 경영진도 고품질 데이터 수요 증가로 평균 판매단가(ASP)가 높아지고 있다고 밝혔는데, 이는 같은 고객이라도 예전보다 더 고가의 정제 데이터셋을 요구하게 되고 있음을 의미한다.
Flitto의 사업모델
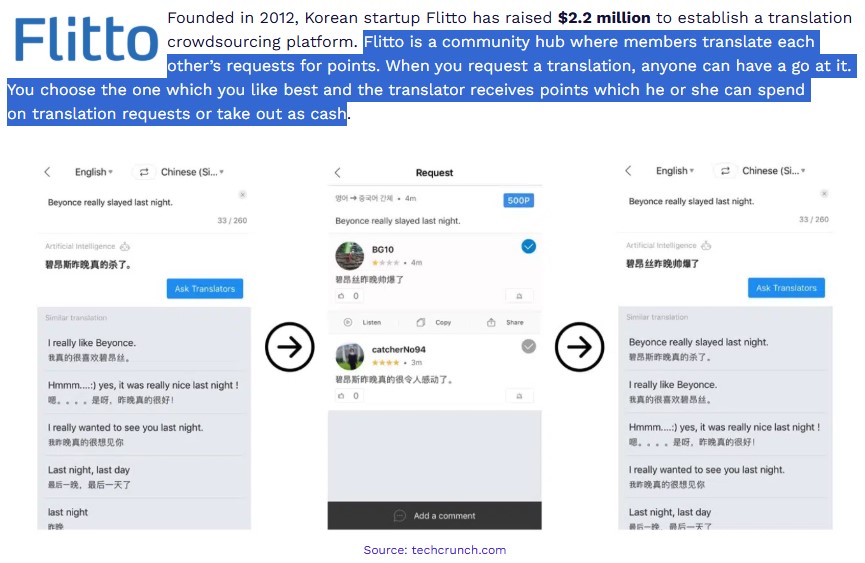
Flitto는 ’12년 설립되어 AI 언어 데이터 및 번역 서비스를 제공하는데, 다수의 사용자 참여를 통해 다국어 데이터를 수집·가공하는 플랫폼을 운영한다. 처음에는 크라우드소싱 번역 앱으로 출발하여, 이용자들이 올린 번역 요청을 다른 이용자들이 포인트를 받고 번역해주는 커뮤니티형 서비스로 성장했다.
Flitto는 현재 “AI 시대의 원유”로 불리는 언어 데이터를 수집부터 검수·정제까지 자체 플랫폼 기반 파이프라인으로 처리하여 낮은 비용에 고품질 데이터를 공급하고 있다. 약 1,400만 명의 글로벌 이용자가 참여하는 생태계를 통해 텍스트·음성·이미지 데이터를 연계 수집하며, 이러한 구조는 외부 하청에 의존하는 경쟁사 대비 진입장벽으로 작용하고 있다.
Flitto의 번역 데이터는 다수 사용자의 검수(좋음/나쁨 투표)를 거쳐 99.8%의 정확도를 달성하여, 경쟁사들의 정확도 90~98%를 상회한다. 또한, 한국어, 몽골어, 아프리카계 언어 등 저자원 언어 분야의 방대한 데이터를 확보하고 있어, 호주의 Appen 등 대비 아시아 언어 데이터에서 우위를 점하고 있다.
현재는 이렇게 플랫폼에서 생성된 방대한 번역 데이터(텍스트, 음성, 이미지)를 바탕으로 AI 학습용 언어 말뭉치(corpus)를 구축하여 기업들에게 판매하는 것이 주요 수익원이다. ’17년 매출의 80%가 축적된 언어 데이터를 판매한 데서 나왔으며, Microsoft, Tencent, Baidu, NTT DoCoMo 등 글로벌 기업들이 Flitto의 말뭉치를 구매해 자체 기계번역 엔진 훈련에 활용했다. Flitto 데이터는 슬랭, 대중문화 용어, 방언 등 기존에 얻기 어려운 고품질 번역쌍을 포함하고 있어 경쟁력이 높다고 평가된다.
경쟁사
Flitto와 유사한 비즈니스 모델을 가진 글로벌 기업으로는 Appen처럼 AI 데이터 전문 기업, Rozetta/Conyac처럼 크라우드 번역 기반 데이터 판매 기업, Unbabel·Lilt처럼 인간+AI 병행 번역 플랫폼 등이 있다. Flitto는 이들 가운데서도 저자원 언어와 크라우드 플랫폼 통합 운용이라는 차별점으로 고품질 데이터를 낮은 비용에 생산하는 역량이 높다.
반면 글로벌 빅테크들은 자체 인프라로 데이터를 확보하거나 서비스 자체로 수익을 내는 경우가 많아, 데이터 판매를 주 사업으로 삼는 Flitto와 직접적 경쟁은 적지만 대체재를 내재화할 잠재력을 가졌다.
결국 Flitto의 경쟁우위는 “자사가 구축한 방대한 다국어 코퍼스를 필요로 하는 기업은 많지만, 이를 자체적으로 모으기 어려운 경우가 많다”는 수요-공급의 틈새에서 형성되어 있다.
Appen (호주)
시드니 증시에 상장된 Appen은 텍스트, 음성, 이미지, 영상 등 대규모 주석 데이터(annotation)를 제공하는 글로벌 선도 기업이다.
데이터 어노테이션이란?(feat. GPT)
**데이터 어노테이션(Data Annotation)**은 데이터 라벨링과 거의 같은 의미로 쓰입니다. **어노테이션(annotation)**이란 “주석을 달다”라는 뜻으로, 원본 데이터(텍스트, 이미지, 음성 등)에 사람이 해석한 정보를 덧붙여주는 작업을 가리킵니다. 예를 들어 텍스트 문장에 정답 번역을 달아 병렬 말뭉치를 만들거나, 이미지 속 객체들에 테두리를 그려 이름을 붙이는 작업, 음성 녹음 파일에 그 내용을 문자로 작성하는 작업 등이 모두 데이터 어노테이션입니다. 이러한 어노테이션을 통해 AI 모델이 무엇이 정답이고 어떤 패턴을 학습해야 하는지 알 수 있게 되므로, 데이터 어노테이션은 AI 학습의 필수 토대 서비스라 할 수 있습니다appen.com. AI는 학습 데이터의 품질과 양에 성능이 좌우되기 때문에, 양질의 어노테이션 서비스는 AI 모델의 성공에 결정적 가치를 제공합니다appen.com. 흔히 “AI 시대의 원유는 데이터”라고 하는데, 그 원유를 정제해서 깨끗한 연료로 만드는 과정이 바로 데이터 어노테이션인 셈입니다.
서비스 제공 방식은 주로 B2B(기업 대상 프로젝트) 형태입니다. 데이터 어노테이션 전문 기업들은 의뢰한 기업(예: AI 개발사)이 필요로 하는 데이터를 정의한 후, 다수의 인력을 투입해 해당 데이터를 수집·가공하여 납품합니다. 이때 인력은 회사의 전담 직원일 수도 있지만, 대규모 크라우드소싱 플랫폼을 통해 전세계 프리랜서 혹은 아르바이트 인력을 모아서 수행하는 경우가 많습니다appen.com. 예를 들어 Appen은 수백만 명 규모의 전세계 크라우드 라벨러 풀(pool)을 보유하고 있고, Flitto 역시 1,400만 명 이상 사용자가 참여하는 크라우드 번역/데이터 수집 플랫폼을 운영하고 있습니다flitto.medium.comdatalab.flitto.com. 이 플랫폼을 통해 필요한 언어, 조건의 데이터를 대량으로 수집하고 여러 단계의 검수로 품질을 높여 최종 데이터셋을 만들어 냅니다flitto.medium.com. 어노테이션 완료된 데이터는 디지털 파일 형태로 납품되며, 텍스트 말뭉치라면 평문 파일이나 CSV, JSON 등으로, 이미지라면 바운딩 박스 좌표 정보와 함께, 음성은 전사된 텍스트와 함께 전달하는 식입니다. 때로는 고객사의 시스템에 직접 업로드하거나 API를 통해 제공하기도 합니다.
가치 제공 측면에서, 데이터 어노테이션 서비스는 AI 모델의 정확도를 높여 개발 일정을 단축해주고, 기업이 자체적으로 하기 어려운 대량의 전문 라벨링 작업을 대신 수행해준다는 가치가 있습니다. 예를 들어 자체 직원으로 100만장의 이미지를 일일이 태깅하기는 불가능에 가깝지만, 전문 업체에 맡기면 체계적인 품질 관리 하에 단기간 내 완료할 수 있습니다appen.comappen.com. 또한 신뢰성 있는 라벨링을 통해 오류를 줄이고, AI의 편향을 완화하는 등 결과적으로 더 나은 AI 서비스를 만들 수 있게 해주는 핵심 밸류를 제공합니다. 요약하면, 데이터 어노테이션 업체는 데이터 준비 과정의 번거로움과 전문성 부족 문제를 해결해주는 파트너라고 볼 수 있습니다.
유통과 광고 방식은 전형적인 B2B 솔루션과 유사합니다. 이러한 기업들은 업계 행사나 네트워크를 통해 AI 개발 기업을 대상으로 마케팅을 하고, 자사 웹사이트나 브로셔를 통해 성공 사례(case study)와 품질 우수성을 홍보합니다. 예컨대 “자율주행 업체 A에 데이터 어노테이션을 제공하여 정확도를 N% 향상” 같은 사례를 공유하면서 신규 고객을 유치합니다. 또한 가격, 소요 시간, 지원 언어/도메인 등을 제안서 형태로 제공하여 기업 고객과 계약을 맺습니다. Appen이나 Flitto 모두 글로벌 지사를 설립하고, 웹사이트에 데이터 서비스 포트폴리오를 게시하며, 영업사원이 직접 고객사에 제안을 하는 등으로 시장에 서비스를 알리고 있습니다.
과금 방식은 프로젝트 단위로 견적을 내는 경우가 대부분입니다. 이는 데이터 종류와 난이도, 분량에 따라 천차만별이기 때문입니다. 일반적으로 **“데이터 포인트당 가격”**을 산정하여 계산합니다. 예를 들면 문장 1개를 이중 언어로 번역하여 검수까지 하는데 0.X달러 혹은 이미지 1장 당 라벨링에 X원 이런 식입니다. 때로는 **시간 기준(라벨러 작업 시간 기준 시급)**으로 비용을 책정하기도 합니다. 예를 들어 Appen 크라우드 작업자들에게는 프로젝트별로 시급 6~12달러 수준으로 비용을 책정하고, Appen은 이를 종합해 고객사에 청구하는 식입니다sweetoffee.tistory.com. 그러나 일반 공개 가격표가 정해져 있다기보다는, 고객의 요구사항(정확도 수준, 데이터 양, 납기 등)에 맞춰 맞춤형 견적을 내는 B2B 계약입니다. 고품질이 요구될수록 다단계 검수와 전문가 투입이 필요하므로 단가가 높아지고thelec.kr, 반대로 간단한 태깅 작업이면 비교적 낮은 단가로 대량 처리합니다. 이런 방식으로 어노테이션 서비스 제공업체는 프로젝트 완료 후 데이터 납품과 함께 대금을 받는 수익 구조입니다.
Appen은 외주 네트워크를 동원하여 AI 엔진 훈련용 언어자원 등 데이터를 수집·가공하며, Search 엔진 평가 등 컨텐츠 라벨링 서비스도 제공한다.
폭발적인 AI 수요에 힘입어 Appen의 매출은 ’17년 1.11억 AUD에서 ’18년 1.66억 AUD로 50% 이상 성장했고, 시가총액 10억 달러에 육박하기도 했다. 고객층은 구글, 마이크로소프트 등 빅테크부터 자율주행, 음성인식 개발사 등 광범위하며, 수익모델은 계약 기반의 데이터 수집·라벨링 용역이다. Appen은 크라우드 외주 네트워크를 활용하지만, 품질 편차와 작업자 관리 이슈도 존재한다. 이에 최근 시장에서는 데이터 품질과 특화성 면에서 Appen 대안으로 Flitto 같은 플랫폼 기반 기업이 주목받고 있다.
Appen의 매출은 데이터 라벨링 서비스가 대부분을 차지하고 소규모의 플랫폼 툴 판매(클라우드 SaaS)가 존재한다는 점에서 플리토와 유사하다. Appen은 ’15년 상장 이후 폭발적 성장세를 이어와 ’19년 매출 약 $4억(YoY +47%)을 달성했다. 성장 동력은 주력 고객군의 발주 확대로, 검색엔진 최적화 등 데이터 매출이 37% 증가하여 전체의 80% 수준이었다. 다만, 매출 성장의 상당 부분이 기존 거대 고객사들로부터 더 많은 주문(즉 고객당 매출 증가)에 의존했으며, ’17~’20년 Appen의 최대 매출처들이 AI 데이터 수요를 대폭 늘리며 회사 매출이 급증했으며, ’19년 기존 고객 프로젝트 확대 및 Figure Eight 인수를 통해 성장했다.
그러나 ‘21년 이후 성장세가 둔화되어 ’20년 약 6억 AUD 내외에서 정점에 달하고, ’21년 소폭 감소 후, ‘22년 5.59억 AUD(-8%), ‘23년 약 4.11억 AUD(-27%)로 급감했다. 매출 하락의 주요 원인은 주요 고객 예산 축소와 테크 업계 둔화로 인한 ARPU 하락이다. 특히 Appen 매출이 몇몇 빅테크에 편중되어 있었기 때문에 나타난 현상이다. 새로운 고객 확보 노력도 있었지만, 이미 글로벌 상위 테크기업 대부분을 고객으로 확보한 상황에서 추가로 매출을 크게 늘릴 만한 신규 고객군 발굴이 어려웠다. 소규모 신규 고객이 늘어도 절대 매출에서는 큰 비중을 차지하지 못했고, 거대 기존 고객의 발주 변동이 매출을 좌우했다.
결국 Appen의 초기 고성장은 소수 대형 고객의 프로젝트 수요 급증(ARPU 증가)에 기인했고, 최근 정체는 그들의 수요 감소로 인한 것이다.
Lionbridge AI (미국)
전통적인 대형 번역/로컬라이제이션 회사이지만, 최근 기계학습용 데이터 공급 사업을 강화했다.
’17년 이후 기존 번역으로 축적한 다국어 말뭉치와 인력풀을 기반으로 Machine Intelligence 부서를 신설하고 AI 훈련 데이터 서비스를 시작했다.
Lionbridge의 AI 데이터 부문은 이후 TELUS International에 인수되어 TELUS AI Data Solutions로 재편되었으며, Appen 등과 경쟁한다. 고객은 빅테크 및 자율주행 등이고, 제공방식은 번역사+크라우드 혼합으로 데이터 수집·라벨링을 수행하는 형태다. Lionbridge의 강점은 기존 전세계 번역사 네트워크로 정제된 고품질 번역 데이터를 많이 보유했다는 점이며, 이를 내재화된 독자 데이터셋으로 활용한다는 점이 Flitto와 다르다.
Conyac (일본)
Conyac은 ’09년 시작된 일본의 번역 크라우드소싱 서비스로, Flitto와 유사하게 개인 간 번역 의뢰를 중개해왔으며, ’16년 일본 AI기업 Rozetta에 인수된 이후, 축적된 번역 말뭉치 데이터 판매를 새 비즈니스로 도입했다.
현재 Conyac/Rozetta는 번역 크라우드로 모은 텍스트 코퍼스를 비롯해 음성인식용 데이터, 챗봇 대화 데이터 등을 외부에 판매하고 있다. Rozetta는 “’25년까지 완전 자동통역기를 개발한다”는 비전을 내세워, 자사 번역 플랫폼을 통한 코퍼스 구축을 수익화하고 있다.
고객은 일본 내 IT기업, 연구기관 등이며, 수익모델은 구축한 병렬 말뭉치를 필요에 따라 판매하는 형태다. Flitto와 매우 유사한 전략으로, 크라우드 번역 → 데이터화 → 판매를 실행한 케이스다. 다만 일본어 중심이어서 글로벌 언어 커버리지는 Flitto가 더 넓다.
Unbabel (포르투갈/미국)
Unbabel은 2013년 포르투갈에서 창업하여 Y Combinator, 구글벤처스 등으로부터 누적 9천만 달러 이상을 투자받은 스타트업이다. “AI + 인간 편집”이라는 하이브리드 접근으로, 기계번역으로 초안을 만든 뒤 다수의 프리랜서 편집자(50,000여 명 커뮤니티)가 교정하여 품질을 높이는 번역 플랫폼을 제공한다.
고객은 세일즈포스, Zendesk, Facebook 등 기업 고객 지원(Customer Support) 분야가 많고, API로도 Unbabel의 번역을 불러쓸 수 있다. 수익모델은 건당 번역 서비스 요금 및 기업 소프트웨어 연동이고, 번역 결과 자체를 외부에 데이터 판매하지는 않는다.
다만 Unbabel은 운영 과정에서 방대한 다국어 교정 데이터를 내부 자산으로 축적하며, 맞춤 MT 엔진 개선에 활용한다. Flitto와 비교하면, Unbabel은 데이터를 외부에 파는 대신 자체 번역서비스 품질개선에 쓰는 모델이다. 고객 측면에서도 Flitto는 AI 개발사 중심 (데이터 판매), Unbabel은 고객지원/콘텐츠 현업 중심 (번역 결과 제공)으로 차이가 있다.
Lilt (미국)
Lilt는 ’15년 전 구글 Translate 팀 출신들이 실리콘밸리에서 창업한 업체로, 인공지능 보조 번역(CAT) 도구를 제공하는 기업이다. Lilt의 플랫폼은 문장을 번역사가 입력하면 실시간으로 다음 단어 제안을 하고, 수정할수록 맞춤형 엔진이 학습되어 점점 정확도가 높아지는 적응형 번역 기술을 특징으로 한다.
이를 통해 인간 번역사의 생산성을 3~5배 높인다고 주장하며, 기업 대상 번역 관리 솔루션으로 판매한다.
매출모델은 소프트웨어 구독 및 전문 번역 서비스이며, Lilt도 번역 과정에서 축적한 번역 메모리와 용어 데이터를 자체 AI 개선에 사용한다. ’20년까지 약 3,750만 달러 투자를 유치했고, SAP 등 대기업과 파트너십을 맺었다. Flitto와 비교하면 Lilt 역시 데이터 판매가 주수익은 아니고, 번역 서비스형 비즈니스다. 다만 Lilt의 모형은 번역 중 생성되는 양질의 데이터를 고객별로 비공개 유지하며 맞춤 MT에 활용하는 것이므로, Flitto처럼 여러 고객에 동일 데이터셋 판매를 하지는 않는다.
빅테크
빅테크는 자체 서비스 강화를 위해 번역 기술을 활용하고 외부에 데이터를 판매하지는 않는다. 자체 번역 엔진 보유 빅테크들도 고품질 데이터 수요가 있으므로 Flitto의 잠재적 경쟁자이며 고객이다.
Google은 Google Translate라는 세계 최대 기계번역 서비스를 운영하며, 방대한 웹 크롤링으로 수집한 평행코퍼스와 자원봉사 번역 참여를 통해 데이터를 확보해왔다. ’14년 시작된 Google Translate Community에서는 수만 명의 사용자가 번역 검수와 새 번역 제안을 제공하여, 구글 번역 품질 향상과 저자원 언어 확장에 기여했다. (이 프로그램은 2024년 봄에 종료되었으나, 그동안 44개 언어에서 최대 40% 품질 개선 효과를 거두었다)
또한 구글은 자사 검색 엔진에서 수집된 다국어 웹페이지들을 활용하고, 필요시 특정 언어에 대해 직접 번역 데이터를 제작하기도 한다. ’23년에는 115개의 저자원 언어에 대해 전문 번역사가 번역한 평행 데이터(SMOL 프로젝트)를 공개하는 등, 자체적으로 데이터를 구축하여 번역기를 개선했다. 구글은 막대한 크롤링 인덱스와 플랫폼 이용자 풀로 Flitto 없이도 데이터를 확보할 수 있어, 데이터 판매 시장에서는 Flitto의 고객이자 궁극적으로는 경쟁상대다.
Naver의 파파고는 한국의 Naver가 자사 검색 데이터를 기반으로 개발한 NMT 번역기다. Papago는 한국어에 특화되어 자연스러운 번역으로 정평이 있으며, Naver 검색 DB의 방대한 한-외국어 컨텐츠를 학습에 활용하는 것이 강점이다.
이처럼 검색엔진을 보유한 기업들은 내부 빅데이터 활용이 가능하여 Flitto와 모델이 다르지만, 고품질 번역 데이터 확보라는 측면에서는 방향을 같이한다. 한편 Microsoft나 Baidu, Tencent 등은 자사 번역 시스템을 갖추었음에도 불구하고 외부 데이터 공급원을 활용하는 전략을 취해왔다. 실제로 Flitto는 MS, 바이두, 텐센트에 데이터를 판매한 바 있으며, 이러한 빅테크들은 특정 도메인이나 부족한 언어쌍에 대해 Flitto 같은 전문업체의 데이터를 수혈하여 번역엔진 한계를 보완하고 있다. 이는 곧 Flitto에게는 고객이자, 동시에 이들이 내부적으로 충분한 데이터를 쌓을 경우 경쟁위협이 될 수 있는 양면성이 있다.
경쟁 관계의 배타성 vs 보완성
언어 데이터, 번역 서비스 시장 특성상 경쟁사와 Flitto의 성장은 보완성이 강하다.
우선 여러 언어쌍 데이터 수요는 상호 대체되지 않고 독립적이다. 한 기업이 특정 언어쌍의 말뭉치를 많이 보유하고 시장을 선도하더라도, 다른 언어쌍에 대한 수요까지 없애지는 못한다. 예를 들어 한 업체가 영어-스페인어 병렬말뭉치를 장악해도, 영어-베트남어 같이 새로운 언어쌍 데이터에 대한 수요는 여전히 별도로 존재한다. 플리토가 저자원 언어 데이터에 강점이 있어도, 경쟁사들은 또 다른 언어 또는 도메인 특화 데이터를 공급하는 방식으로 공존하고 있다.
동일한 언어쌍에 대해서도 데이터의 질과 용도가 천차만별이라서 한 기업의 데이터가 다른 기업을 완전히 대체하기 어렵다. 실제 사례로, 구글이나 메타 같은 빅테크 기업들이 자체 번역 엔진과 방대한 데이터를 보유하고 있음에도 불구하고 플리토의 특화된 고품질 언어 데이터를 추가로 구매·채택한다.
플리토의 정밀한 병렬 데이터는 범용 번역기가 커버하지 못하는 고유명사, 전문 분야 표현 등의 한계를 보완하기 위해 사용되며, 경쟁사의 번역 품질을 향상시키는 보완재 역할을 한다.
또한 사용자도 복수의 번역 서비스나 데이터 소스를 병행 활용한다. 기업 고객은 기본 기계번역 엔진은 구글 것을 쓰면서도, 별도로 플리토의 전문 번역 플랫폼을 통해 부족한 언어쌍 데이터를 확보하기도 한다.
결국 한 시장에 한 업체만 있으면 충분하다기보다, 언어 종류와 활용 분야별로 여러 플레이어들이 각자의 강점을 살려 공존하는 구조다. 특정 분야에서 한 기업이 성공하면 해당 분야 번역 수요의 확대를 통해 더 전문적인 번역이나 다른 서비스에 대한 관심도 늘어나고, 타사의 데이터나 솔루션 수요도 함께 증가한다. 결론적으로 경쟁사의 매출과 성장은 플리토와 배타적이라기보다는 대체로 보완적인 관계다. 말뭉치(언어쌍) 자체의 특성도 언어별로 독립적인 자산이므로, 한 업체가 특정 말뭉치를 많이 확보한다고 해서 다른 말뭉치에 대한 필요성이 없어지지 않는다.
다만 동일한 좁은 분야에서 직접 경쟁하는 경우(예: 두 회사 모두 몽골어-영어 데이터만 취급 등)에는 한쪽이 시장을 거의 차지하면 다른 쪽 입지가 좁아질 수는 있다. 그러나 현재 플리토와 주요 경쟁사들은 각기 좀 다른 언어, 영역에 강점을 가져 완전한 대체재 관계에 놓여있지는 않다.
데이터 소유권
Flitto의 데이터 정책
플랫폼에서 수집·생성된 모든 언어 데이터의 저작권 및 소유권은 Flitto에 귀속된다. 이용자들이 Flitto에 제공한 번역 컨텐츠는 모두 회사가 자유롭게 활용·판매할 수 있는 자산으로 취급되고 있다.
Flitto의 ’19년 코스닥 상장 당시 증권신고서 및 관련 보도에 따르면 사용자가 웹과 앱을 통해 생산해내는 텍스트, 음성, 이미지 언어데이터는 모두 Flitto에 귀속된다고 명시되어 있다.
즉, 사용자들이 자발적으로 올린 번역 결과물이든, 참여형 미션으로 얻어진 대화 데이터든 일단 플랫폼에 축적되면 Flitto가 그 독점적 권리를 보유하게 되며, 원천 번역 데이터에 대해 완전한 배타적 지식재산권을 확보한다. 따라서 이용자들이 번역에 기여하면 포인트 등의 보상을 받을 뿐, 해당 번역 결과를 개별적으로 외부에 팔거나 할 권리는 없고 Flitto가 일괄 소유하여 상품화하는 구조다.
이러한 독점적 소유권을 바탕으로 Flitto는 데이터를 라이선스 형태로 고객사에 제공한다. 또한, Flitto가 데이터를 판매한다고 데이터의 소유권이 고객에게 이전되는 것이 아니다. Flitto는 비독점적 라이선스로 데이터를 여러 곳에 공급하며 “한 번 구축한 말뭉치를 한 곳에 팔고 끝내지 않는다”는 One Source, Multi-Use 전략을 취하고 있다.
Flitto가 구축한 한국어-영어 100만 문장 말뭉치를 삼성전자에 판매했어도, 삼성만 사용하고 끝나는 것이 아니라 동일 말뭉치를 다른 기업에도 반복 판매함으로써 추가 수익을 창출할 수 있다. 경영진은 “누군가는 데이터를 하드웨어처럼 한 군데 팔면 없어지는 걸로 여기는데, 말뭉치는 무형자산이라 여러 고객에 재사용된다”고 언급하여 데이터가 소프트웨어나 저작권에 가까운 무형 자산으로, 한 번 제작되면 무한 복제가 가능하고 여러 번 활용될 수 있다는 점을 강조했다.
또한 계약 방식 면에서, Flitto는 특정 고객사에 맞춤 데이터를 제공하는 경우라도 해당 데이터의 권리는 여전히 Flitto가 유지한다. Flitto는 주요 고객과 데이터 제공 계약을 맺을 때도 이를 라이선스 판매로 인식하며, 계약 종료 후에도 유사 데이터를 재가공하여 다른 용도로 활용할 수 있다.
’22년부터 ’25년까지 한 미국 빅테크 A사와 한국어 등 언어 데이터 공급 계약을 3차례에 걸쳐 체결했는데, 이는 건별 프로젝트 계약이지만 Flitto 입장에서는 반복적인 수익원으로 자리잡았다고 밝혔다. A사에 제공한 데이터도 Flitto가 지속 업그레이드하며 공급을 이어가는 형태로, 일정 기간 독점 사용권을 그 기업에 주었을 수는 있어도 영구적 소유권을 양도한 것은 아니다. 결국 Flitto는 자신이 보유한 원천 데이터를 계속 축적하고 고도화하면서, 다수의 기업에 제공하는 방식으로 사업을 운영하고 있다고 정리할 수 있다.
이러한 소유권 구조는 Flitto의 데이터가 곧 회사 핵심자산이자 해자(Moat)임을 보여주며, 데이터를 통한 추가 서비스 개발이나 솔루션 판매에도 유연하게 활용될 수 있게 해준다.
경쟁사의 데이터 보유 형태 : 직접 보유 vs 접근권
플리토는 자체 플랫폼을 통해 수집한 병렬 말뭉치 데이터를 핵심 자산으로 직접 보유한다.
이에 반해 대부분의 경쟁사는 플리토처럼 데이터를 직접 축적하여 재판매하는 모델이 아니라, 고객사의 의뢰에 따라 데이터를 수집·가공해 전달하는 서비스형 모델을 운영한다. Appen은 전세계 크라우드소싱 인력을 동원해 다국적 기업의 AI 학습 데이터를 수탁 생산하나, 생산된 데이터셋의 소유권은 주로 발주한 고객사에 귀속된다. Appen은 프로젝트 단위로 데이터 접근권을 제공할 뿐, 플리토처럼 통합된 언어쌍 데이터베이스를 구축해 자체 재산으로 보유하는 방식은 아니다. 따라서 수행 후 결과물을 넘기면 그때그때 소유권이 넘어가는 경우가 많다.
구글, 메타, 네이버 등 빅테크는 방대한 자사 사용자 데이터와 웹 크롤링 등을 통해 언어 데이터를 자체 축적하고 있지만 이들은 해당 데이터를 자체 서비스 개선에 활용할 뿐 외부에 판매하거나 공유하지는 않아, 플리토와 직접적 경쟁 관계에 놓이지는 않으며, 오히려 플리토가 빅테크가 필요로 하는 특정 언어쌍/도메인 데이터를 판매하는 파트너십 관계다.
결과적으로, 플리토와 같이 방대한 병렬 말뭉치를 직접 보유한 형태의 경쟁사는 찾기 어렵다. 이는 플리토만의 데이터 판매 비즈니스 모델(한번 모은 데이터를 반복 판매)을 가능케 하며, 경쟁사들은 흉내내기 어렵다.
데이터 소유 여부가 BM에 미치는 영향 : 반복 판매 가능성
플리토처럼 자체 구축한 말뭉치를 판매하는 기업들은 동일한 말뭉치를 여러 번 판매하여 반복적으로 매출을 올릴 수 있다. 플리토는 이미 구축해둔 다양한 언어쌍, 도메인의 병렬 말뭉치 라이브러리를 갖추고 있어 필요한 기업에 그 데이터 세트를 ‘라이선스 형태’로 판매한다. 예를 들어 영어-스페인어 일반 회화 말뭉치 100만 문장을 한 번 만들어 놓으면, 이를 구글에도 팔고, 다른 스타트업에도 팔고, 여러 번 판매할 수 있다. 플리토 입장에서는 한 번 데이터 자산을 구축해 놓으면 다수의 고객에게 파는 데이터 거래 플랫폼 사업이 가능하다. 실제로 플리토는 자사 DataLab을 통해 대규모 데이터셋 라이브러리를 공개하고, 여기에 다양한 고객들이 접근하여 필요한 데이터를 구매할 수 있도록 하고 있다. 이런 데이터 서비스형 사업모델(Data as a Service)에서는 동일 데이터의 중복 판매가 수익 극대화의 핵심이다.
다만 일부 대형 계약의 경우 고객이 독점적 사용을 원할 수 있고, 또는 해당 데이터셋이 그 고객의 특정 목적을 위해 커스터마이징되어 다른 곳에 바로 재활용하기 어려울 수도 있다. 다만, 플리토는 해당 프로젝트를 통해 구축한 노하우와 언어 자원을 활용해 유사한 요구를 가진 다른 고객에게 변형된 데이터 서비스를 제공할 수는 있을 것이다. 개별 계약으로 맞춤 생산된 데이터셋은 보통 그 계약 대상에게만 제공되며, 그 동일분량을 또 팔아 같은 매출을 내는 것은 계약상 불가능하거나 현실적으로 쉽지 않을 수 있다.
Appen의 경우는 애초에 고객사의 전용 데이터에 라벨링 작업을 해주는 서비스가 대부분이라, 그 결과물을 다른 곳에 재판매하지 않으므로 동일 작업으로 반복 매출을 내는 구조가 아니었다. 그렇기에 한 번 잃은 매출이 쉽게 반복되지 않아 최근 매출 감소가 지속되고 있는 것이다. 반면 데이터셋 판매형 모델을 부분적으로 가지고 있는 플리토는, 이미 확보한 병렬 말뭉치로 꾸준한 판매를 기대해볼 수 있다는 차이가 있다.
주요 번역 프로그램별 데이터 사용 현황
Google, DeepL, Meta 등 기업들은 자력으로 데이터를 얻고 있으며, 파파고, MS, 바이두는 플리토 데이터를 보완적으로 사용하고 있다.
Google Translate (구글 번역)
구글은 Flitto의 데이터를 직접 사용한다는 공식 정보는 없다. 앞서 언급한 바와 같이, 구글은 막강한 자체 리소스로 번역 품질을 향상시켜 왔다. 주요 데이터 소스로는 웹 크롤링을 통한 평행 코퍼스 자동수집, 유엔/유럽연합 등 공개된 다국어 문서 코퍼스, 그리고 사용자 기여 번역이 있었다. 구글은 ’14년 “Translate Community”를 출범시켜 전세계 자원봉사자들이 번역 문장을 평가하거나 직접 번역하게 함으로써, 데이터가 부족한 언어의 번역 품질을 높였다.
마오리어, 우르두어 등 저자원 언어의 경우 이 커뮤니티 기여가 큰 도움이 되었으며, 실제로 수년간 다수 언어에서 눈에 띄는 향상을 이끌어냈다. 이 크라우드소싱 프로그램은 ’24년까지 운영되었고 그 후에는 대규모 언어 모델(LLM)의 발전으로 인해 방식이 전환되었다.
한편, 구글은 자사 검색엔진이 전세계 웹사이트의 번역쌍을 방대하게 보유하고 있다는 강점을 적극 활용한다. 구글 검색 크롤러는 다국어로 제공되는 웹페이지(예: 위키백과 다언어 버전, 다국어 뉴스사이트 등)를 수집하여, 이를 문장 단위로 정렬함으로써 자동으로 번역 데이터베이스를 구축해왔다. 이렇듯 크롤링 + 크라우드소싱 + 공개코퍼스 활용을 통해 구글은 Flitto에 의존하지 않고도 108개 이상의 언어쌍에 대한 번역 모델을 발전시켰다. 오히려 구글은 자체적으로 희귀 언어 데이터셋을 제작하여 공개하기도 하는데, ’22년 Meta가 발표한 NLLB(No Language Left Behind)처럼 다언어 평행말뭉치를 만들거나, ’23년에는 구글이 주도하여 115개 저자원 언어에 대한 전문 번역 문장 데이터(SMOL)를 마련하는 등 업계 전반에 데이터를 축적하는 움직임이 활발하다.
이러한 배경을 감안할 때 Google Translate는 Flitto의 데이터에 크게 의존하지 않고, 독자적 데이터를 기반으로 서비스하는 것으로 보인다. 다만 구글이 간접적으로라도 Flitto의 공개 자료나 일부 데이터셋을 활용했는지는 알 수 없다. 예를 들어 Flitto가 학계나 공개 경진대회를 통해 데이터를 공유했다면 구글이 그것을 참고했을 가능성은 있으나, 상업적 계약으로 Flitto 데이터를 구매했다는 소식은 전해진 바 없다.
DeepL (딥엘)
DeepL은 ’17년에 등장한 독일의 기계번역 서비스로, 특히 유럽 언어 정확도가 뛰어나다. Flitto 데이터 사용 여부를 공식적으로 밝힌 적은 없다.
DeepL의 강점은 원래 Linguee라는 온라인 번역 사전 서비스에서 시작되었다는 점이다. Linguee는 수년간 인터넷의 양질의 번역문(예: EU 공식문서, 특허 번역, 웹사이트 다국어 표기 등)을 크롤링하여 10억 문장 이상의 대규모 바이링구얼 코퍼스를 구축했다. DeepL 번역기는 바로 이 Linguee 말뭉치를 기반으로 개발되었으며, 회사 측 설명에 따르면 DeepL의 모델은 Linguee가 수집한 바이링구얼 코퍼스와 크롤러를 지속적으로 운영하여 웹상에 새로 등장하는 번역 쌍을 찾아내고 정확도를 검증한 후 훈련데이터에 추가하는 프로세스를 통해 품질을 높이고 있다.
이처럼 DeepL은 자체 크롤링 데이터 자산이 핵심이므로, Flitto와 접점이 거의 없다. Flitto가 보유한 한국어 등 아시아 언어 데이터에 관심을 가질 수는 있지만, ’23년부터 DeepL은 한국어, 중국어 등도 지원하기 시작하면서 여전히 자체 수집한 데이터와 대규모 신경망 학습으로 품질을 높이고 있다. DeepL의 성공 요인은 Linguee 기반 유럽언어 코퍼스와 딥러닝 기술력으로 평가된다. 따라서 DeepL도 Flitto 데이터는 사용하지 않고, 웹 크롤링 및 자체 데이터 구축으로 서비스를 제공하고 있다.
NAVER Papago (네이버 파파고)
Papago는 ’16년 출시된 네이버의 AI 번역 앱/웹서비스로, 특히 한국어 번역에 강점을 보인다. ’19년 코스닥 상장 전 Flitto가 배포한 자료에 “플리토의 전방산업은 국내 AI 시장으로, 그 중 음성인식(SKT 누구, KT 기가지니 등 AI스피커)과 통번역(파파고 등 기계번역기)에 플리토의 언어데이터가 제공되고 있다”고 명시되어 Flitto의 학습용 데이터 고객임을 알 수 있다.
이는 네이버가 자체적으로 한국어↔영어 데이터를 확보할 수 있지만, 한국어와 제3외국어(예: 한국어-인도네시아어 등) 병렬 데이터는 구글만큼 얻기 어렵다(글로벌 이용자가 적기 때문). Papago 초기 Flitto와 언어 데이터 제휴를 맺어 말뭉치를 보완하여 번역 정확도를 더욱 높였다. Papago 관계자는 고유명사, 전문용어 등 범용 번역엔진의 한계를 보완하는 특화 데이터 공급능력 때문에 Flitto의 데이터를 채택했다고 하며, Flitto도 국내 빅테크에 데이터 납품 실적을 확보한 사례다.
네이버는 정부 공개 데이터(예: AI 허브의 평행코퍼스)나 자사 콘텐츠(웹툰/웹소설 번역본 등), Papago 사용자들이 번역 결과를 평가하면 학습하는 등 데이터를 축적했다. Papago 웹/앱에도 “입력된 문장은 서비스 개선을 위해 활용될 수 있다”는 안내가 있다.
즉, Papago는 Flitto의 데이터를 활용하면서, 네이버 자체의 빅데이터(검색 색인, 이용자 피드백 등)로 번역 엔진을 발전시켜 왔다.
Microsoft Translator (빙 번역)
마이크로소프트의 번역기도 구글처럼 다년간 자체 연구로 성장해왔으나, 주로 기업 대상 Translator Text API로 제공되기에 대중 인지도는 낮다. MS는 ’17년 중국어-영어에서 인간에 근접한 번역 품질을 달성했다고 발표하는 등 NMT 개발에 앞서 있었고, 자사 제품 (Office, Bing 등)에서 수집한 양질의 문장쌍을 활용했다.
MS는 AI 학습을 위해 외부 데이터도 적극 도입했는데, 2017년 Flitto가 MS에 다량의 한국어 등 번역 데이터를 판매한 것이 알려져 있다.
특히 한국어, 일본어 등 아시아 언어에서 Flitto 데이터를 수혈한 것으로 보인다. 현재 MS는 OpenAI와의 협업 등으로 번역 품질을 높이고 있지만, Flitto 같은 전문업체 데이터에 대한 수요는 지속될 수 있다.
Baidu Translate (바이두 번역)
중국 바이두의 번역 서비스로, 중국어 기반 다언어를 지원한다. ‘17년 Flitto로부터 중국어 번역 말뭉치를 구매한 사례가 있으며, 중국어 슬랭/신조어 등이 포함된 Flitto 데이터로 엔진을 향상시켰다. 자체적으로도 사용자 번역 참여 커뮤니티를 운영하고, 웹상의 중국어-영어 콘텐트를 수집하여 엔진을 고도화했다.
Meta (페이스북)
페이스북은 자체 번역 기능을 뉴스피드 등에 제공하고, ’22년에는 200개 언어 이상을 아우르는 NLLB 대형번역모델을 공개했다. Meta가 Flitto 데이터를 썼다는 소식은 없으며, 번역모델 학습을 위해 위키백과, 성경 번역본, 웹 크롤링 데이터 등 공개 코퍼스를 활용했고, 아프리카 현지 연구자 그룹(Masakhane 등) 등 오픈소스 커뮤니티와 자체 인력으로 저자원 언어 데이터를 확보했다.
Flitto의 매출 성장성
Flitto의 TAM
플리토의 TAM(Total Addressable Market)은 전 세계 모든 AI 언어 데이터 수요 및 실시간 번역 수요를 총망라한 시장이라 할 수 있다. 구체적으로는 AI 학습용 데이터 레이블링/수집 시장 중 자연어 부문, 글로벌 번역·통역 서비스 시장 중 AI 기반 자동통역 분야를 합친 범위다.
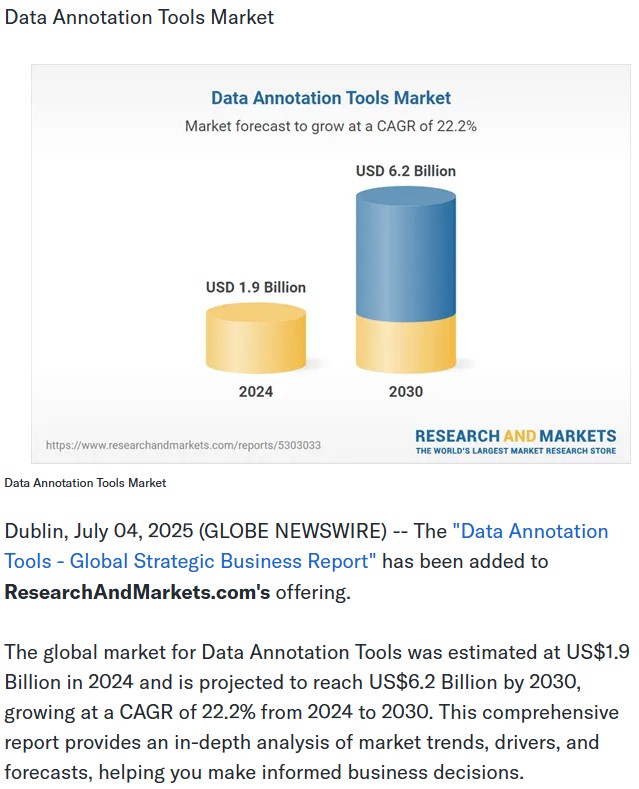
규모 면에서 추산해보면, 전세계 AI 데이터 어노테이션 시장은 ’24년 약 19억 달러(2조 5천억원) 규모로 추정되고 2030년경 62억 달러 이상으로 성장할 것으로 전망된다(CAGR 22.2%).
이 가운데 언어 데이터 비중이 상당 부분을 차지하며, 플리토의 데이터 TAM에 해당한다. 또한 글로벌 통·번역 서비스 시장은 (전통적 인력 포함 시) ’20년대 중반 약 50조원에 달하는 거대 시장으로 추산되며, 이중 자동통번역 솔루션 분야도 빠르게 성장하고 있다. 생성형 AI와 멀티모달 AI의 부상으로, 언어 AI 솔루션 수요는 산업 전반(인터넷, 교육, 광고, 콘텐츠, 빅테크 등)에서 지속 증가하는 추세다. 요컨대 플리토의 TAM은 언어 장벽 해소를 필요로 하는 모든 영역으로서, 잠재 시장규모가 매우 크고 꾸준히 확대되고 있다.
AI 학습에 따른 시장 축소 가능성 : AI 기술은 Flitto BM과 경합적인가 보완적인가
언어 자체는 비교적 정적인 체계이고 어휘 변화도 제한적이다 보니, 한번 데이터 우위를 가진다고 해서 영구적인 것은 아닐 수 있다. 이러한 위험에 대해 플리토가 독점적으로 보유한 언어 데이터 자산이 머신러닝의 발전이나 경쟁자의 AI 학습 가속화에 의해 빠르게 따라잡힐 위험은 없는지 살펴본다.
언어 데이터 독점의 범위
플리토가 보유한 데이터의 강점은 희귀 언어 및 일상 표현 등 웹에 충분히 존재하지 않는 부분에 집중돼 있다. 일반적인 정형 문장이나 흔한 문서는 구글 등도 크롤링으로 많이 확보했고, 공개 말뭉치도 많다. 그러나 플리토는 사람들이 실제 쓰는 구어체, 신조어, 지역 특유 표현 등의 디테일하고 실용적인 번역쌍을 쌓아왔다.
언어는 정태적이라도 그 활용 맥락과 표현은 무궁무진하기 때문에, 이러한 디테일에서 오는 데이터 우위는 쉽게 없어지지 않는다. 경쟁자가 기계학습으로 따라잡으려 해도, 이미 플리토가 수집한 맥락 풍부한 병렬 데이터를 단순 모노링구얼 학습으로 복제하기는 어렵다. 예컨대 “밈(meme)”에 해당하는 신조어 표현을 각 언어에서 어떻게 번역하는지는 문화적 맥락이 필요한데, 이런 부분은 데이터를 독점한 쪽이 유리하다.
머신러닝의 데이터 효율 향상
확실히 최신 딥러닝 기법은 데이터 효율을 개선하고 있다. 소수 샘플로 학습하는 소타 기법, Active Learning 등으로 적은 데이터로도 높은 성능을 내는 연구가 많다. 또한 경쟁사들이 오픈소스 말뭉치 + 자체 조금의 데이터로 빠르게 모델 성능을 끌어올리는 경우도 생기고 있다.
그러나 이런 효율 향상에도 한계가 존재한다. 특정 영역의 번역 품질은 여전히 해당 분야의 정제된 병렬데이터 축적량에 비례한다. 대용량 데이터를 가진 쪽이 결국 미묘한 뉘앙스까지 잘 맞추는 고성능을 내기 마련이다. 가속화 학습으로 격차를 줄일 수는 있어도, 동일 수준으로 따라잡으려면 결국 상당량의 유사한 데이터가 필요하다는 뜻이다. 플리토는 특히 범용 번역기가 틀리기 쉬운 부분(고유명사, 전문용어, 문맥묘사)에서 강점이 있는데, 이런 부분은 경쟁사가 일반 딥러닝만으로 메우기 어려운 빈틈이다.
데이터 증분의 한계
언어 외연이 빠르게 확장하지 않는다는 점은 맞지만, AI 학습용 데이터로 유의미한 것은 단순 사전적 어휘가 아니라 실제 사용 문장들이다.
현실 세계에선 매일 새로운 시사용어, 유행어, 전문지식이 등장한다. 예컨대 COVID-19 이후 방역 용어들의 다국어 번역 데이터는 ’19년 이전에는 없던 것들이다. 플리토는 이런 새로운 콘텐츠를 실시간으로 축적하지만, 경쟁사가 나중에 따라잡으려면 이미 시의성을 잃은 후발 수집이 될 수 있다.
언어 데이터 독점의 유지는 단순히 언어체계 그 자체가 아니라 시시각각 변하는 언어 사용 데이터의 선점에 달려 있다. 이 면에서 플리토가 실시간 크라우드를 활용하여 낮은 비용으로 데이터를 업데이트하는 한, 경쟁자가 격차 없는 수준에 이르기 어렵다.
AI 자동생성 데이터의 한계
경쟁자가 모델을 활용해 인위적으로 병렬 데이터를 생성하는 방식도 생각해볼 수 있다. 예컨데 영어 문장을 모델로 번역하여 pseudo-parallel 데이터셋을 대량 확보하는 것이다. 이런 방법은 어느 정도 효과가 있지만, 오류를 내포한 데이터가 누적될 위험이 있다.
실제로 자기가 만든 번역으로 스스로 훈련하는 자기학습은 품질 상한이 존재하며, 결국 사람이 만든 골드-스탠다드 데이터를 완전히 대체할 순 없다. 플리토의 독점 데이터는 사람들이 참여해 검수한 정답 데이터라는 점에서, AI가 생성한 은닉 오류 데이터와 본질적 차별화가 있다.
따라서 경쟁사가 AI로 빠르게 번역문을 양산하더라도, 그것으로 플리토와 대등한 품질을 담보하긴 어렵다.
Flitto의 내러티브와 경쟁사 내러티브 충돌 가능성
현재 플리토와 경쟁사들이 내세우는 성장 스토리는 일부 교집합이 있으나 충돌하지는 않는다.
플리토의 내러티브는 “저자원 언어 데이터라는 틈새에서 독보적 품질을 확보하고, 이를 기반으로 AI 통번역 솔루션까지 확장”하는 것으로 요약된다. 즉 데이터 중심(Data-centric) 시대에 희소하고 정밀한 언어 데이터를 무기로 삼아 성장하겠다는 이야기다.
주요 경쟁사인 Appen의 최근 내러티브를 보면, 급성장하는 AI 데이터 시장에서 선두주자 내러티브가 있었으나 ’21년 이후로는 실적 부진을 타개하기 위한 비용 절감과 중국 시장 공략, 생성 AI 관련 프로젝트 수행 등사업 개편 쪽에 초점이 맞춰져 있다.
이는 플리토처럼 공격적 확장 스토리라기보다 방어적 대응 전략으로 플리토의 내러티브와 정면으로 충돌한다고 보긴 어렵다. 오히려 서로 처한 상황이 달라 플리토는 고성장 서사, 경쟁사는 재정비 서사를 가지고 병존하는 모습이다.
다만 장기적으로는 내러티브 충돌의 가능성을 배제할 수 없다. 가령 Appen이 구조조정을 마치고 멀티모달 저자원 데이터 쪽으로 전략을 전환해 플리토가 강점을 지닌 분야에 진입한다면, 플리토의 “희소언어 데이터 독점” 내러티브와 충돌이 발생할 수 있다. 혹은 빅테크 기업들이 자체 언어 데이터 구축을 강화하여 외부 데이터 업체 의존도를 낮추는 방향으로 나아간다면, “플리토를 통한 데이터 조달” 내러티브와 배치될 여지가 있다. 또한 DeepL과 같은 기업은 “최고 품질 기계번역 서비스”를 내세워 성장하고 있는데, 이 경우 플리토의 AI 통번역 솔루션과 경쟁·대체 관계가 형성될 수 있다.
결국 TAM이 겹치는 부분에서 각자의 성장스토리가 충돌할 가능성은 존재한다. 그러나 현 시점에서는 플리토가 집중하는 저자원 언어 데이터 시장에 뚜렷한 경쟁자가 드물고, 주요 경쟁사의 전략 방향도 분산되어 있어 직접적인 내러티브 충돌 가능성은 낮다.
플리토 또한 시장 변화를 주시하면서 음성·이미지 등 데이터 종류 다변화, 솔루션 고도화 등으로 자신만의 성장 내러티브를 강화하고 있어, 경쟁사가 비슷한 이야기를 내세워도 중기적으로는 BM을 유지할 개연성이 높다고 볼 수 있다.
Flitto의 경제적 해자
플리토의 데이터 자산 축적 방식을 신규 진입자가 모방하기 어려운 이유는 다음과 같다.
네트워크 효과 – 글로벌 대규모 사용자 풀 확보의 어려움
플리토는 현재 1400만명 규모의 글로벌 사용자 커뮤니티를 보유하고 있다. 이들은 173개국의 다언어 사용자로, 텍스트·음성·이미지 등 다양한 언어 데이터를 생성한다. 신규 업체가 동일한 규모와 다양성의 커뮤니티를 구축하려면 막대한 시간과 자원이 필요하다. 언어 플랫폼은 네트워크 효과가 강해, 초기에 사용자가 적으면 참여 동기가 낮아진다. 플리토는 ’12년 창업 이후 혁신적인 서비스(1분 내 수십 개 번역 제안 등)로 유저를 모았고, 그 커뮤니티가 지금의 데이터 생산 엔진이 되었다.
네트워크 효과는 시간이 지날수록 오히려 강화된다. 플리토의 1400만 유저는 계속 데이터를 생산해내고 있어 데이터 자산이 실시간으로 늘어나며, 참여자들은 보상체계에 익숙해 이탈률도 크지 않다. 신규 경쟁자가 미래에 인공신경망으로 빠르게 데이터를 생성한다 해도, 플리토 커뮤니티가 만들어내는 최신 트렌드 반영 인간 번역 데이터를 완전히 대체하기 어렵다.
모방하기 어려운 생산 프로세스 – 보상 및 검수 시스템 수직통합
플리토의 시스템은 게임적 요소(포인트 보상, 랭킹 등)와 다단계 검수 알고리즘이 적용돼 있다. 이용자들은 번역하고 포인트나 금전적 보상을 받고, 이를 통해 언어 학습 동기도 얻는다. 또한 다수가 참여할 경우 품질을 상호 평가하거나 별도 검수팀이 정제하여 고품질 데이터로 완성하는 시스템이 구축돼 있다. 이는 10여년간 시행착오를 겪으며 다듬어진 것으로, 경쟁사가 단순히 사람을 모은다고 해서 같은 품질의 데이터를 뽑아낼 수 있는 게 아니다.
이러한 낮은 단가 고품질 생산 프로세스(외주비·포인트비 절감)를 바탕으로 플리토가 40%대 영업이익률을 목표로 할 만큼 비용효율성이 높은데, 후발주자는 이를 모방하기 어렵다.
브랜드 가치, 데이터 자산 – 대규모, 다양한 데이터 소유권
플리토는 이미 다년간 축적해온 방대한 병렬 말뭉치와 음성 데이터 등을 보유한다. 특히 한국어·몽골어·아프리카계 언어 등 희소 언어 데이터에 있어서 경쟁사 대비 압도적인 량과 질을 갖췄다. 신규 경쟁자가 이제 와서 해당 언어 자원을 모으려 해도, 플리토가 확보한 데이터를 따라잡기 위해선 동일한 양질의 번역을 수백만 건 생산해야 한다. 이를 위해선 상당수의 전문 번역 인력을 동원하거나 플리토 규모의 크라우드를 형성해야 하는데 현실적으로 쉽지 않다. 데이터 축적의 초기 격차가 시간이 흐를수록 더 벌어질 가능성이 높다. 플리토는 최근 음성 데이터 등 단가 높고 희소성이 큰 데이터까지 수집 범위를 넓혀가고 있어, 시간이 지날수록 경쟁사가 커버해야 할 격차가 오히려 커지는 중이다.
해자의 침식 가능성
알고리즘이 데이터를 대체할 수 있을까?
장기적으로는 기술 변화에 따라 상황이 바뀔 수 있다. 예를 들어 AI 자동 데이터 생성 기술이 획기적으로 발전해 사람 없이도 희소언어 병렬 데이터를 대량 생성할 수 있게 된다면, 플리토의 크라우드 방식 우위는 줄어들 수 있다. 그러나 현재로선 완전한 대체는 요원하며, 플리토의 집단지성 모델이 지닌 인간 품질 데이터의 가치는 지속적으로 유지될 전망이다. 따라서 경쟁자들이 이 메커니즘을 모방하기는 현실적으로 어렵고, 플리토가 쌓아온 데이터 격차도 단기간에 좁혀지기 힘들다고 평가된다.
빅테크들의 자체 데이터 축적 노력은 Flitto의 시장을 잠식할 수 있는 요소다. 구글, 메타 등은 거대한 자본과 인력을 투입해 오픈소스 데이터셋 생성(예: NLLB, SMOL)이나 커뮤니티 주도 번역으로 저자원 언어 격차를 줄여가고 있다. 장기적으로 이들이 거의 모든 언어에 대해 충분한 데이터를 확보하면, Flitto 같은 외부 공급자에 대한 수요가 줄어들 수 있다. 다만 전 세계 수천 개 언어/신조어/방언에 대한 현지화된 구어체 데이터는 여전히 부족하여 Flitto의 역할이 쉽게 대체되지는 않을 것으로 보인다.
또한 신기술의 등장도 변수다. 최근 발전하는 거대 언어모델(LLM)들은 병렬 말뭉치 없이 자연어 추론만으로도 번역 품질을 향상시키고 있다. GPT-4는 한 언어로 학습해도, 병렬 말뭉치를 직접 학습하지 않았더라도 다중언어 코퍼스를 통해 언어 사이 추론 능력을 획득하여 꽤 정확한 번역을 해낸다. Meta의 NLLB(No Language Left Behind) 같은 프로젝트는 저자원 언어라도 모노링구얼 데이터와 언어 간 추론 기법으로 번역 모델을 만드는 등, 병렬 데이터 의존도를 낮추는 방향의 연구도 진행되었다.
Flitto처럼 정제된 레이블드 데이터 공급자의 중요성은 당분간 유지되겠지만, 장기적으로 모델의 데이터 의존도 감소가 이루어지면 Flitto의 시장규모 성장에 한계가 올 가능성이 있다. AI 기술 발전으로 데이터 효율성이 높아지면, 예전보다 적은 데이터로도 모델 성능을 낼 수 있게 되어 데이터 양의 격차가 줄어들 수 있으며, 일부 공개 말뭉치의 증가로 희소 언어 데이터도 공공에서 확보하는 움직임이 있어, 플리토의 독점 데이터 우위가 예전만 못해질 가능성도 고려할 수 있어서, 장기적으로 AI가 스스로 언어 구조를 추론하여 번역하는 시대가 올 수도 있어 보인다.
유지되는 데이터의 중요성
다만 업계 전문가들은 여전히 AI 시대에 ‘모델보다 데이터가 중요하다’고 평가하며, 특화된 고품질 데이터 없이는 번역 AI의 한계를 넘기 어렵다고 지적한다. 또한, 특정 도메인(의료, 법률 등)이나 특수 언어 쌍에서는 Flitto 같은 전문 데이터셋이 범용 AI 번역기의 빈틈을 메워줄 수 있다.
현재까지의 기술 추이를 보면 병렬 말뭉치의 중요성이 완전히 사라지지는 않고 있다. 자연어 추론 기반 번역은 대규모 파라미터와 연산 자원을 필요로 하고, 특히 희귀한 표현이나 맥락에서는 여전히 병렬 예문 학습이 있었던 모델보다 오류율이 높다. 병렬 말뭉치로 직접 학습된 번역 모델은 소규모나 특정 분야에서 여전히 추론 기반 LLM보다 정확하고 효율적인 결과를 낸다.
즉, 모델의 규모를 키우는 것 못지않게, 특정 작업에 맞는 양질의 데이터를 확보하는 것이 성능 향상의 지름길로 인식되고 있다. 실제로 빅테크들도 범용 LLM만으로 모든 번역 문제를 풀 수 없음을 깨닫고, 특화 데이터 확보에 눈을 돌리고 있다. 자연어 추론 기술이 발전해도 제대로 훈련하기 위해 여전히 병렬 말뭉치 등의 레이블된 데이터가 필요하며, 추론 모델 + 전문 말뭉치를 결합하여 학습하는 방향으로 발전하고 있다. 의학 논문 번역처럼 전문성이 필요한 작업의 경우, 해당 도메인 병렬 말뭉치를 학습한 모델이 맥락 추론으로 번역하는 모델보다 용어 선택과 정확도 면에서 우수하다. 거대 언어모델도 최종 품질을 높이기 위해 고품질 병렬 데이터로 파인튜닝을 거치는 경우가 많아 추론 AI와 병렬 말뭉치는 상호 보완적으로 활용되는 추세로, 결국 두 기술간 경쟁 구도는 완전한 대체보다는 접점이 생기는 방향으로 진화되고 있는 것이다.
그리고 Flitto도 경쟁환경을 인식하여 솔루션 사업 다각화로 대응하고 있다. 최근 Flitto AI+ (Chat Translation, Live Translation) 등 실시간 통역 솔루션을 출시하여 B2C/B2B 제품화에 나섰고, 메뉴 번역 서비스처럼 데이터와 솔루션을 결합한 새로운 수익원을 개발하고 있다. 이는 단순 데이터 판매를 넘어 완제품 번역 서비스를 제공함으로써, 빅테크와 차별화된 영역을 공략하려는 전략으로 해석된다. Flitto의 실시간 대화 통역 앱은 사용자 개인의 말투에 맞춰 번역을 개선하는 초개인화 기술을 선보여 호평받았고, 이 기술은 Flitto만의 다국어 데이터와 10년 이상의 전문 번역 노하우가 결합되어 가능한 것이었다.
또한 자연어 추론 기술이 영상/음성 등으로 확대되는 흐름 속에서 영상/음성 멀티모달 데이터 수요 증가에 맞춰, 음성인식(STT), 음성합성(TTS), OCR 등 기술을 확보하고, 단순 텍스트 병렬 말뭉치 제공을 넘어 음성∙영상 기반 통번역 데이터/솔루션까지 영역을 넓혀 통합적 언어 AI 경쟁력을 확보하려 하고 있다. 집단지성으로 모은 데이터를 활용해 자체 번역 AI 엔진을 고도화하고, 이를 다시 크라우드 플랫폼에 접목하는 식으로 선순환을 만들고 있다. 특히 다양한 연령 이용자의 음성 녹음 미션 등을 통해 음성 데이터를 대량 확보함으로써 새로운 고부가가치 데이터를 축적하고 있다. 또한 정부의 AI 프로젝트 참여 등 외부 파트너십을 통해 데이터 경쟁력을 유지·강화하고 있다.
이러한 선제적 조치들은 Flitto가 데이터 시장의 변화에 대응하면서 자신의 해자를 지키고 확장하려는 노력의 일환이다.
결론적으로, Flitto는 크라우드소싱 기반 저자원 언어 데이터 구축이라는 독특한 비즈니스 모델을 통해 글로벌 경쟁자 대비 뚜렷한 강점을 확보했다. 플랫폼에서 생산되는 데이터의 독점적 소유를 바탕으로, One Source Multi-Use 라이선스 전략으로 수익을 극대화하고 있다. Papago 등 주요 번역 앱들도 의존할 만큼 Flitto의 데이터는 가치를 지닌다.
빅테크의 행보와 AI기술 발전이 변수이긴 하나, 데이터 중심의 AI 패러다임에서는 Flitto의 역할이 계속 중요할 것으로 보인다. Flitto는 자신만의 데이터 품질과 영역을 유지하면서, 동시에 솔루션 사업을 확장하여 데이터+알파의 가치를 창출하는 방향으로 경쟁우위를 공고히 할 것이며, 투자자로서는 이러한 경쟁우위가 유지되는지를 꾸준히 지켜봐야 할 것이다.
가치투자 커뮤니티를 성장시켜나가고 있습니다. 운영 계획과 방향성을 한 번 읽어보시고, 텔레그램과 유튜브 채널을 통해 소통하고 있으니 공감이 가신다면 참여해주세요! 쌍방향 소통을 원하는 분들은 카카오톡 채널로 와 주시면 좋을 거 같습니다. 자료실을 통해 리포트, 뉴스도 공유하고 있으니 참고하시면 도움이 될 거 같습니다.
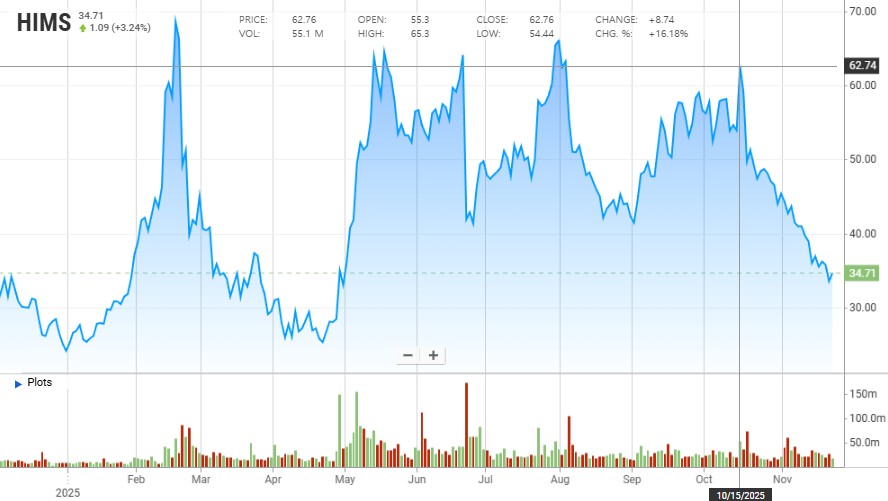
낮은 가이던스와 성장률 저하로 인해 MDB에 대해 부정적인 시선이 팽배하던 시기가 있었다. 경쟁 DBaaS의 성장이 부각되고, 앞으로 점점 점유율을 잠식당할 거라는 리스크가 강조되고, 경영진이 발표한 낮은 매출 성장 가이던스는 시장에게 패닉을 안겨줬다.
그럴 때에도, 심지어 경영진이 성장률 전망을 낮춰잡더라도, 회사의 구조적 강점을 파악하고 AI 시대에 대세가 될 기업이라는 데 대한 확신을 가져야 하는 것이 가치투자자이다. 그 굳건한 믿음의 대가는 엄청난 수익이다.
리오넬 메시는 위대한 선수다.(잘은 모르지만.. 그렇다고 한다) 발롱도르와 FIFA 올해의 선수를 몇 차례 석권하고 MVP를 수상했다. 하지만 그도 월드컵 우승을 한 번도 하지 못하고 있었는데, ’22년 월드컵에서 35세의 고령으로 기용하는 데 있어 감독의 고민이 있었지만, 결과적으로는 7경기 7골 3어시스트, 토너먼트 전경기 골을 기록하면서 역대급 퍼포먼스로 아르헨티나 대표팀의 우승을 견인했다.
MDB도 그렇다. 잘 모르는 사람들이 보면 이제 더 이상 성장이 멈춘 기업이라고 생각할 수 있었겠지만, AI 학습에 대한 NoSQL의 우월성, 그리고 통합 데이터 서비스를 제공할 수 있는 플랫폼으로서 개발자들에게 제공되는 편의성 측면에서 앞으로 성장 여력이 무궁무진한 기업이라는 것을 이제 사람들이 깨닫고 있다. 그렇게 봤을 때 지금까지의 성장은 시작에 불과하며, 메시의 ’22년이 그랬듯이 더욱 더 영광스런 날들이 기다리고 있다는 것을 이번 실적발표를 통해 다시 한 번 확인해보도록 하자.
3분기 MDB 실적
견고한 실적 달성
MongoDB는 2026년 회계연도 3분기에 매출 $6.28억 달러로 전년 대비 19% 증가하며 가이던스 상단을 상회하였다.
Atlas(클라우드 데이터베이스 서비스) 매출이 전년 대비 30% 성장하여 성장세를 견인했는데, 이는 전분기 29%, 전전분기 26%였던 성장률이 더욱 가속화된 것이다. Atlas는 전체 매출의 75%를 차지했으며, 엔터프라이즈 대형 고객들의 사용량 증가와 Self-Serve 신규 고객 유입 확대 모두에서 고르게 성장했다. 그 결과 순ARR 확장율(Net ARR Expansion Rate)은 119%에서 120%로 상승하여, 기존 고객들이 지속적으로 MongoDB 이용을 확대하고 있음을 증명했다.
온프레미스 제품(Non-Atlas) 사업
클라우드 Atlas 이외의 Enterprise Advanced(EA) 온프레미스(설치형) 라이선스 매출도 예상보다 양호했다. 연간 반복매출(ARR) 기준으로 Non-Atlas 부문은 8% 성장하였다. 예상을 넘어서는 멀티연도 계약 몇 건이 체결되어 Non-Atlas 매출이 가이던스를 웃돌았다.
수익성 및 비용 관리
3분기 비용 효율성도 개선되었다. Non-GAAP 영업이익은 $123.1M로 영업이익률 20%를 기록했다.(전년 동기 19%) 이는 매출 호조와 일부 계획된 투자 집행의 지연으로 비용 증가가 완만했던 영향이다. Non-GAAP 순이익은 $115M(EPS $1.32)로 전년 동기 $98M(EPS $1.16)보다 증가했다. FCF는 $1.40억 달러로 전년 동기 대비 4배 이상 급증했다. 이는 수익성 향상과 함께 고객 대금 현금 회수 개선 등 자본 효율이 높아진 덕분이다.
고객 증가 및 사용 사례
분기 동안 신규 고객 2,600여 곳을 추가하며 총 62,500여 고객을 확보했다. 전년 동기(52,600여 곳) 대비 10,000곳 가까이 증가했으며, 특히 Self-Serve로 MongoDB Atlas를 도입하는 중소 규모 고객 유입이 크게 늘어났다. 연간 $10만 달러 이상 사용하는 대형 고객 수도 2,694곳으로 전년 대비 16% 증가해, 엔터프라이즈 고객 기반도 탄탄히 확대되고 있다.
기존 고객들의 사용량 확대 사례로, 한 글로벌 보험사는 차세대 보험증권 플랫폼, 요율엔진, 비정형 데이터 저장소 등을 Atlas로 표준화하여 운영 지역을 소수 지역에서 전국 규모로 확장했다. 그 결과 신규 상품 출시와 채널 확대 속도가 빨라지고, 대용량 데이터 처리와 AI 활용 측면에서 확장성과 신뢰성을 확보했다.
이러한 사례에서 보듯, 대형 금융·의료·제조 기업들 상당수가 미션크리티컬 업무(기업 목표 달성에 핵심적인 업무)에 MongoDB를 채택하고 있으며, 앞으로도 기존 조직 내 MongoDB 활용 범위를 넓힐 여지가 매우 크다고 경영진은 강조했다.
AI 시대를 향한 플랫폼 비전
신임 CEO로 첫 실적발표에 나선 Chirantan “CJ” Desai는 MongoDB가 클라우드, 데이터, AI로의 기술 전환의 중심에서 “차세대 모던 데이터 플랫폼”이 될 잠재력을 지녔다고 밝혔다.
현재도 MongoDB는 많은 기업의 핵심 운영 데이터베이스로 자리잡았지만, 앞으로 생성형 AI 시대에 요구되는 새로운 어플리케이션에도 최적화되어 있다. LLM과 같은 AI 모델의 지식과 기업 고유의 실제 데이터(프라이빗 데이터, 실시간 문맥)를 연결하는 것이 AI 애플리케이션의 본질인데, 이는 곧 정보 검색 및 통합 문제로서 기존의 관계형 데이터베이스로는 실시간 고정확도 성능을 내기 어렵다. 반면 MongoDB의 문서지향(JSON) 데이터 모델은 다양한 형태의 변동성 있는 데이터를 유연하게 담을 수 있고, 통합된 검색(Search)과 벡터 검색(Vector Search), 그리고 올초 인수한 Voyage AI의 임베딩(Embeddings) 모델까지 한 플랫폼에 갖추고 있어 별도 솔루션을 붙였을 때 발생하는 복잡성과 비효율을 제거해준다. 실제로 MongoDB의 자체 AI 기능은 Hugging Face의 임베딩 벤치마크 1위, DB-Engines 랭킹에서 벡터 데이터베이스 분야 1위를 기록할 만큼 업계 선도적 성능을 보이고 있다. 최신 임베딩 및 재랭킹 모델을 통해 AI 애플리케이션의 응답 정확도를 높여 환각(hallucination)을 줄이는 한편, 더 작고 효율적인 임베딩으로 스토리지와 쿼리 비용 절감 효과도 제공한다.
CEO는 이러한 운영 데이터와 AI 워크로드의 통합 플랫폼이 MongoDB의 차별화된 강점이며, AI 도입이 가속화될수록 MongoDB가 수혜를 입는 것 뿐 아니라 그 방향을 정하는 핵심 플랫폼이 될 것이라고 자신했다.
AI 활용 고객 사례
컨콜에서 MongoDB를 AI에 활용한 두 가지 사례가 소개되었다.
Mercor라는 AI 스타트업은 AI로 구직자와 채용 기회를 연결하는 완전 자동화 플랫폼을 구축했는데, MongoDB Atlas에 이 플랫폼의 핵심 데이터를 저장하고 있다. Mercor는 Self-Serve로 Atlas를 시작한 후 Voyage 임베딩 모델과 Atlas 벡터 검색 기능까지 활용하여, 매달 50%에 달하는 폭발적 사용자 증가를 MongoDB로 무리 없이 처리하고 있다. 이를 통해 소프트웨어 엔지니어 팀을 소수 정예로 유지한 채 기업가치 100억 달러 이상 규모로 성장할 수 있었다.
한 글로벌 미디어 기업은 70여 개 웹사이트의 방대한 멀티미디어 자산에 대해 개인화 콘텐츠 추천을 강화하기 위해 Atlas를 도입했다. 기존에는 Elasticsearch로 검색/추천 시스템을 구현했지만, 새로운 임베딩 모델 도입 후 성능 한계에 부딪혀 혁신이 가로막힌 상황이었다. 이 회사는 MongoDB 전문가들과 함께 단 몇 주 만에 Atlas 및 Atlas Vector Search 기반으로 아키텍처를 재구축했고, Voyage AI 모델을 데이터와 직접 통합했다. 그 결과 시스템이 손쉽게 확장되면서도 응답 지연을 90% 감소시키고 운영비용을 65% 절감했으며, 추천 클릭률은 35% 향상되어 전 세계 수백만 독자들에게 한층 매끄럽고 개인화된 콘텐츠 경험을 제공할 수 있었다.
가이던스 상향
경영진은 핵심 사업의 탄탄한 성장세와 더불어 AI 관련 수요의 초기 조짐까지 더해지고 있다고 판단하여 향후 실적 전망을 상향했다. 4분기 매출 가이던스를 $665~670M(YoY +21~22%)로 제시하며 컨센서스 $636M 대비 5% 수준으로 가이던스를 상향했으며, , 조정 영업이익률 약 21% 수준을 기대한다고 밝혔다.
연간으로는 매출 $2.43~2.44B(전년비 +21~22%)로 컨센 대비 1% 수준으로 가이던스를 상향, 조정 영업이익도 $436~440M으로 무려 $109M 상향 조정했다.
이처럼 매출 성장과 수익성 개선이 동시에 이루어짐에 따라, 9월 IR에서 제시한 장기 모델(매출 성장률 20%대, 영업이익률 +20%, FCF 마진 25% 이상) 달성에 한층 가까워졌다. CFO는 내년에도 제품 개발, 마케팅, 영업인력 확충 등 성장을 위한 투자는 이어가겠지만, 규모의 경제로 매년 1~2%p 영업마진 확대와 FCF 마진 80~100% 수준 유지라는 장기 목표를 지속 추구한다고 밝혔다. (MDB의 경영진은 그 보수성으로 악명이 높다) 또한 올해 Non-Atlas 부문의 예기치 않은 대형계약 증가로 내년에는 EA(설치형) 매출이 특별한 역풍이나 순풍 없이 안정적(중저 한자릿수 % 성장)일 것으로 전망했다.
주주환원 및 자본배치
MongoDB는 강화된 현금창출력을 주주가치 제고와 미래 대비에 활용하고 있다. 지난 분기 발표했던 자사주 매입 프로그램($10억 규모)을 통해 3분기에 $1.45억을 집행(주식 51만4천주 취득)하여 주식수 희석을 일부 상쇄했다. 또한 직원 지급 RSU의 세금납부를 주식이 아닌 현금으로 정산하기 시작했고, 2026년 만기 전환사채에 대해 헷지 거래로 확보한 백만주 이상의 주식을 곧 수령할 예정이라 언급했다. 이러한 노력으로 향후 주식수 증가를 억제하고 주주가치를 지키겠다는 의지를 표명했다.
3분기 MDB 컨퍼런스콜 주요 Q&A
AI 전략과 초기 성과
CJ는 취임 첫 달여 동안 30여 고객사를 만나본 결과, 핵심 업계 고객들은 여전히 레거시 애플리케이션을 현대화하고 클라우드로 옮기는 작업에 주력하고 있다고 밝혔다. 이 과정에서 MongoDB에 대한 수요가 꾸준하며, 향후 5~7년간 이러한 현대화 수요가 지속될 것으로 전망했다.
다만, 여러 기업들이 사내 생산성 향상을 위한 AI 파일럿 프로젝트들을 다수 진행 중이나 대외적으로 고객에게 제공되는 대규모 AI 에이전트는 아직 초기 단계라고 평가했다. 한편 AI 네이티브 스타트업들의 동향을 보면, 기존 관계형 DB로는 대용량 AI 워크로드를 감당하지 못해 MongoDB로 갈아타는 사례가 나오고 있다고 소개했다. (예: 한 성장형 AI 기업이 Postgres 한계를 느껴 MongoDB로 전환)
CEO는 MongoDB의 문서지향 DB가 스키마 유연성 덕분에 변화무쌍한 AI 데이터에 적합하고, 벡터 검색 등 AI 기능을 통합 제공하기에 AI 시대의 필수 ‘데이터 플랫폼‘이 될 것으로 확신했다.
당장 고객들이 Voyage AI의 임베딩 및 재랭킹 기능을 시도했을 때 높은 효용을 느낄 수 있다고 자신하면서, 실제 일부 대기업은 MongoDB의 임베딩 모델을 이미 내부 AI 프로젝트에 도입했다고 덧붙였다.
대형 고객들의 사용량 증대
CFO는 이번 분기 Atlas 사용량 증가는 전년 동기와 유사한 패턴으로 견조하게 나타났으며, 특히 미국과 EMEA 지역의 대형 고객들이 새로운 워크로드를 올리고 기존 워크로드를 확장한 것이 핵심 동력이라고 설명했다.
대형 고객들은 규모가 커질수록 사용 기간도 길어지고 지속적으로 성장하는 추세를 보이고 있다. 이는 MongoDB Atlas가 대형 고객에게 점차 전략적 플랫폼으로 자리매김하고 있음을 시사한다. 상대적으로 거시경제 영향이 있었던 작년 대비, 올해 들어 고객들의 워크로드 품질이 개선되고 성장 모멘텀도 양호하다고 평가하였다.
개발자 생태계 및 벤치마크
질문에서 지적된 서부 해안(미국 실리콘밸리) 스타트업들의 PostgreSQL 선호 분위기와 MongoDB의 개발자 인지도에 대해, 경영진은 이를 잘 인지하고 있다고 답했다.
전 CEO는 “Reclaim the Bay”라는 구호 아래 코로나 기간 다소 소홀했던 샌프란시스코/실리콘밸리 지역 스타트업 커뮤니티 지원을 재강화했다고 밝혔다. 전담 세일즈 인력과 마케팅 이벤트, 해커톤 등을 늘려 AI 신생기업들이 MongoDB의 강점을 직접 체험하도록 하는 노력을 기울였고, 점차 성과가 나타나고 있다고 전했다.
CEO 역시 실리콘밸리 VC 및 테크 인맥을 적극 활용하여 유망 AI 스타트업들과 교류하고 피드백을 얻고 있으며, 1.15일 샌프란시스코에서 개발자 대상 대형 행사(.local 컨퍼런스)를 개최해 MongoDB 플랫폼의 가치 제안을 확산시킬 계획을 발표했다.
지속적인 투자와 수익성 균형
Non-GAAP 영업이익률(20%)은 회사가 장기목표로 제시한 중장기 마진 수준(20%대)에 근접해 있다.
CFO는 내년도 성장 기회를 놓치지 않기 위해 엔지니어링, 영업, 마케팅에 투자할 것이지만, 영업 레버리지로 연 1~2% 마진 개선 여력이 있어 성장 속 수익성 개선 기조를 유지할 계획을 밝혔다. 3분기에 일부 계획된 채용과 마케팅 지출이 4분기 이후로 늦춰져 마진이 일시적으로 높아졌으나, 투자가 정상화되어도 매출 증가분이 그 이상으로 마진을 창출할 것이라고 설명했다.
가이던스 및 가시성 향상
CFO는 이번 분기부터 Atlas 부문의 다음 분기 성장률 전망치를 구체적으로 제시하기 시작한 배경에 대해, Atlas 매출 규모가 커지면서 예측 정확도가 높아졌기 때문이라고 밝혔다.
Atlas는 연 $2B 규모로 성장했고, 소비 패턴도 안정되어 분기 가이던스를 세울 만한 데이터가 축적되었다. 4Q Atlas 성장률을 약 27%로 전망한 것은 연말 소비 둔화 계절성을 감안한 보수적인 수치이며, 기본적으로 현재의 견조한 수요 흐름이 이어질 것을 기대하고 있다고 설명했다.
비 Atlas (설치형 온프레미스) 부문의 경우 올해 특수한 선행 매출 인식 효과(멀티연도 계약 증가)로 4분기 및 내년 초에 일시적 역풍 가능성이 있으나, 내년 Non-Atlas 매출은 한 자릿수 중후반 정도 성장을 무난히 달성할 것으로 내다봤다.
신규 고객 활용 속도
신규 고객들이 Atlas에 온보딩하여 사용량을 늘리는 속도가 과거보다 빨라졌는지에 대한 질문에, CEO는 Atlas 8.0 및 8.2 버전에서 성능과 사용 편의성이 개선된 덕분에 마이그레이션이나 시작이 한층 수월해졌다고 답했다.
전 CEO도 Self-Serve 채널에서의 초기 진입 마찰을 줄이는 노력이 주효하여, 새로 유입된 고객들이 MongoDB의 높은 가성비와 확장성을 빨리 체감하고 사용량을 키워가는 사례가 많아졌다고 설명했습니다.
CFO는 신규 고객의 초기 매출 기여도는 여전히 소규모이므로 당장 전체 실적에 큰 영향을 주지는 않으며, 이러한 코호트 패턴은 과거 몇 년과 비슷한 수준이라고 덧붙였다.
M&A
CEO는 MongoDB가 이미 세계적 수준의 기술과 인재 풀을 갖추고 있어 유기적 성장에 집중할 방침이라고 밝혔다. 다만 Voyage AI 인수 사례처럼 제품 로드맵을 앞당길 특정 핵심 기술이나 인재 확보의 기회가 있을 경우 전략적 인수도 고려할 수 있다고 밝혔다.
전반적인 플랫폼 역량을 자체 혁신으로도 충분히 강화할 수 있다는 자신감을 내비쳐, 개인적으로는 유기적 성장만으로 20%대 성장을 지속할 수 있다는 비전을 보여준 것 같아 아주 긍정적으로 보고 있다. (확률이 매우 높은 투자 아이디어. M&A에 성공하지 않아도, 딱히 대형 고객이 선택해주지 않아도, 자연스럽게 20%대 성장을 지속할 수 있는 투자대안)
CEO의 향후 중점 추진 분야
CEO는 자신의 경험과 강점을 살려 매출 성장의 두 축에 공헌하겠다고 밝혔다.
하나는 기존 Fortune 500 등 글로벌 대기업 고객과의 관계 심화다. CEO는 오랜 기간 쌓아온 CIO/CTO 네트워크를 통해 MongoDB를 더 많은 대형 엔터프라이즈에 침투시키고, 기존 대형 고객의 사용량 증대 및 업셀을 직접 지원하겠다고 발표했다.
다른 한 축은 실리콘밸리 등지의 유망 AI 스타트업 커뮤니티다. 그는 투자자 및 창업자들과 교류하며 성장 잠재력이 큰 AI 신생기업들이 초기부터 MongoDB 플랫폼을 선택하도록 독려하고, 그들이 대형 고객으로 성장했을 때 MongoDB 생태계의 일원이 되도록 씨를 뿌리겠다고 밝혔다.
엔터프라이즈 애플리케이션 개발 속도
생성형 AI 시대의 자동 코딩으로 앱 개발 생산성이 올라가는 추세에 대해, 전 CEO는 “소프트웨어의 양이 늘어날수록 데이터베이스 수요도 증가하기 때문에 MongoDB에 긍정적”이라고 분석했다.
엔터프라이즈급 서비스로 실사용되기 위해서는 보안, 성능, 거버넌스 요건이 충족되어야 하므로, 단순 시연용 프로토타입에서 실제 대규모 프로덕션 배포로 이어지기까지는 상당한 추가 노력이 필요하다고 지적했다.
현 CEO도 금융/헬스케어 등 규제산업의 고객들과 대화한 바, 현재 수십 개 시범 AI 프로젝트를 진행중이나 법적 감사와 통제 요건을 충족하는 단계까지 나아간 사례는 드물다고 언급했다. 그러나 기업들이 AI 혁신의 필요성을 크게 느끼고 있기 때문에, MongoDB가 제공하는 완성도 높은 데이터 플랫폼을 통해 이러한 실제 운영환경에 맞는 AI 솔루션 개발을 지원할 수 있다.
2분기 대비 3분기 주요 변화점
BM의 이해
신임 CEO 체제가 출범하면서, 회사는 기존 “어플리케이션 데이터 플랫폼” 전략을 한층 강화하여 AI 시대의 범용 데이터 플랫폼으로 발전하겠다는 비전을 분명히 했다. 단순 DBMS 공급사를 넘어 개발 플랫폼 전반으로 워크로드를 확장하려는 기조는 지속되었다. 3분기에는 통합검색, 벡터DB, 임베딩 AI 모델 등 플랫폼에 새롭게 추가된 기능들의 활용 사례가 소개되면서 ‘단순 데이터 제공을 넘어선 플랫폼 전략’이 실제 수요와 맞물리고 있음을 확인했다.
전반적으로 비즈니스 모델의 방향성에는 변화가 없고, 제품 포트폴리오가 AI 등 신기술을 포괄하며 진화하여 유기적 성장으로도 성장 기울기가 더 가팔라지고 있다는 점이 두드러진다.
매출 성장성
2분기까지 견조했던 매출 성장세는 3분기에 더욱 탄력을 받았다. Atlas의 전년 대비 성장률이 26% → 29% → 30%로 분기마다 가속되었고, 총매출 역시 20% 내외의 성장률을 유지하며 ‘고성장 모멘텀’을 재확인시켰다.
특히 3분기에는 소비 침체 우려를 딛고도 예상치를 상회하는 “깜짝 실적”을 달성하여 시장의 높은 성장을 입증했다. 이에 힘입어 연간 가이던스가 큰 폭 상향되었고, 내년 전망에 대해서도 긍정적인 코멘트가 나와 성장 가시성이 한층 개선되었다.
한편 고객 수 증대와 대형 고객들의 지속적 업셀링으로 미래의 성장 기반도 확대되고 있다.
경제적 해자
2분기에도 언급되었던 높은 전환비용과 생태계 확장성에 기반한 해자는 3분기에도 유효했다.
MongoDB를 이미 도입한 기업들이 더 많은 워크로드를 이관하거나 신규 프로젝트에 추가 적용하는 사례가 속출하며 고객 락인(lock-in) 효과가 나타나고 있다. Net ARR 확장률이 120%로 상승한 점은 기존 고객이 이탈하기보다는 오히려 지출을 늘리고 있음을 보여주는 지표다.
또한 3분기 컨콜에서는 경쟁 솔루션 대비 MongoDB의 우위가 구체적 사례로 강조되었는데, 예를 들어 관계형 DB(PostgreSQL)나 Elasticsearch 등 개별 솔루션으로는 감당 못할 성능과 확장 문제를 MongoDB 플랫폼이 해결해준 사례들이 소개되었다.
이는 MongoDB의 기술적 우월성과 광범위한 활용성이 사실상의 진입장벽으로 작용하고 있음을 시사한다.
한편 파트너 생태계 측면에서는, 고객들이 Atlas 상에서 다양한 기능(Search, Vector Search, Embeddings 등)을 원스톱으로 활용하게 함으로써 MongoDB 생태계 내에서 모든 것을 해결하도록하여 잠김효과를 강화했다.
협상력
MongoDB의 가격협상력과 시장에서의 교섭 위치는 3분기에도 강화되었다.
대형 고객일수록 장기계약과 사용량 확대로 MongoDB를 깊이 활용하고 있고, 고객들이 그만큼 MongoDB에 높은 가치를 느껴 가격보다 성능과 효용을 중시함을 보여준다.
회사 측은 여전히 직접 판매와 셀프서비스 채널 모두에서 광범위한 신규 수요를 확보하고 있으며, 특별히 가격 압박으로 인한 매출 차질을 언급하지 않았습니다. 오히려 큰 Atlas 소비 단가 변동 없이 안정적 소비 성장이 이어지고 있음을 시사했다.
공급 측면에서는, MongoDB가 클라우드 인프라 비용 최적화를 통해 Atlas 마진을 개선했으며, 운영 효율 제고로 비용을 통제하고 있어 공급업체나 비용에서도 협상력을 발휘하고 있다. 3분기에 영업이익률 개선과 현금흐름 증가를 달성한 점은 회사가 고객가치 제공과 원가관리 사이에서 균형을 잘 맞추며, 가격 책정과 비용 통제에 주도권을 쥐고 있음을 시사한다.
자본배치
3분기 MongoDB 경영진은 수익성 개선과 함께 주주가치 제고를 위한 자본배치에도 적극 나서고 있음을 보여주었다.
우선 잉여현금흐름이 크게 증가하면서 약속했던 자사주 매입을 실행에 옮겨, 분기 중 1.45억 달러 규모 자사주를 매입했다. 이는 주식수 증가율을 억제하여 주당가치 희석을 줄이고 주주에게 이익을 환원하는 조치다. 또한 전환사채 콜옵션과 RSU 세금현금납부 등을 통해 향후 발생할 잠재적 주식 발행을 최소화하겠다고 밝혔다.
이는 고성장 기업임에도 주주친화적인 자본배치에 신경 쓰고 있음을 보여준다. 동시에 회사는 필요 투자도 지연 없이 수행하여 미래 성장 동력을 키우고 있다(엔지니어 채용, 마케팅 등).
밸류에이션
3분기 실적 발표 이후 MongoDB 주가는 약 20% 이상 급등하며 시장의 기대감을 반영했다.
현재 주가는 실적 서프라이즈를 반영해 상당히 높은 수준에 형성되었으나, 실적으로 매출 성장 가속과 수익성 개선을 동시에 보여주며 투자자들에게 고성장주로서의 정당성을 재확인시켜주었다.
25.12.11일 종가 기준으로 ORCL, SNOW, MDB의 밸류에이션을 PSR, PER, PEG 관점에서 비교해 보면 다음과 같다(PER은 조정 EPS(non-GAAP EPS) 기준, PEG의 성장률은 각 사 최신 분기 매출 YoY 성장률로 계산)
Oracle (ORCL) – 주당 $199, 시가총액 약 $550B, PSR(주가매출비율)은 약 9배 수준이며(최근 4분기 매출 합계 약 $600억), 조정 EPS 기준 PER(주가수익비율)은 FY2025 전체 Non-GAAP EPS가 $6.03였으므로 이를 기준으로 약 33배, FY2026 실적을 반영하면 30배 안팎이다. 최신 분기 매출 성장률은 +14% YoY 수준이므로 PEG( PER÷매출성장률 )은 대략 2~2.5배 수준으로, 세 기업 중에서는 가장 낮은 PEG를 보인다.
Snowflake (SNOW) – 주당 $220, 시가총액 약 $74B 수준이며, PSR은 약 16~17배로 매우 높다. 최근 12개월 매출 약 $43억 달러, 주당 매출은 약 $13 수준이다. Snowflake는 막 조정 순이익이 플러스가 되기 시작한 단계로, FY2026 3분기 Non-GAAP EPS가 겨우 $0.35 (약 450원)이고 연환산해도 $1 남짓에 불과하다. 한편 최근 분기 매출 성장률은 약 +29% YoY로 세 기업 중 가장 높다. 이를 반영한 PEG는 6 이상으로, 성장률을 고려해도 여전히 밸류에이션이 무거운 편이다.
MongoDB (MDB) – 주당 $420, 시가총액 약 $33B, PSR은 대략 14~15배 수준이다. TTM 매출은 약 $23억 달러(연간 주당매출 약 $28.8)이다. PER는 약 90배 수준으로 매우 높다. MongoDB는 최근 흑자전환에 성공하여 FY2026 3분기 조정 EPS $1.32를 달성하는 등 수익성이 개선되고 있으나, 12개월 조정 EPS 합산이 약 $4.5 내외에 불과해 멀티플은 큰 편이다. 최근 분기 매출 성장률은 +19% YoY로 양호한 편이며, 이를 반영한 PEG는 약 4.5~5배 수준입니다. 즉 성장률을 감안해도 여전히 상당히 높은 밸류에이션인 셈입니다.
위 수치를 종합하면, Oracle은 가장 낮은 PSR과 PER를 보이며 PEG도 2배대, MongoDB와 Snowflake는 매우 높은 PSR/PER를 기록하지만, MongoDB는 수익성 개선으로 PER ~90배, PEG ~5배 수준인 반면 Snowflake는 아직 이익이 미미하여 사실상 “PER 수백배”의 높은 멀티플을 받고 있다. 결국 Oracle은 비교적 합리적 밸류, MongoDB는 성장주 중간 정도 밸류, Snowflake는 성장률 대비로도 가장 비싼 수준으로 평가된다고 볼 수 있다.
다만, 핵심 부문인 Atlas의 30% 성장률과 영업이익 흑자를 달성했다는 점을 조합한다면, 그리고 성장 기울기가 오히려 가팔라지고 있다는 점을 고려한다면 MDB가 갈 길은 아직도 멀다고 생각한다.
가치투자 커뮤니티를 성장시켜나가고 있습니다. 운영 계획과 방향성을 한 번 읽어보시고, 텔레그램과 유튜브 채널을 통해 소통하고 있으니 공감이 가신다면 참여해주세요! 쌍방향 소통을 원하는 분들은 카카오톡 채널로 와 주시면 좋을 거 같습니다. 자료실을 통해 리포트, 뉴스도 공유하고 있으니 참고하시면 도움이 될 거 같습니다.
커버기업들이 힘을 내줘서 초과수익률이 플러스로 돌아왔다. 힘들 때 따뜻한 말 나눠준 멤버들에게 다시 한 번 감사드린다.
인카금융서비스
인카금융서비스가 4%에 달하는 자사주를 소각하는 발표를 했다. 사실 인카금융서비스와 같이 CEO가 자본배치를 잘 하고 주주가치 제고를 위해 노력하는 기업이라면 자사주 매입으로 증명을 해야 하나 싶긴 하지만, 그럼에도 불구하고 자기 주머니에 현금이 들어와야, 실제 행동으로 나타나야 믿는 사람들이 많은 곳이 시장이 아닌가 싶다.
내가 생각하는 인카금융서비스의 내재가치는 그대로이며, 나의 이해와 시장의 이해가 조금 좁혀진 것이라고 평가한다.
토모큐브
토모큐브는 12.2일 미국 트럼프 행정부에서 동물실험을 축소할 계획을 발표한 것이 큰 호재로 받아들여졌다.
토모큐브 분석 글에서 언급했던 바와 같이, 임상에서 동물 실험을 NAM이라 불리는 대안적 실험방법으로 대체해나가고 있으며, FDA가 이를 앞장서 진행하고 있는 상황이고, NAM 중 가장 앞서나가는 대안적 방법이 ‘오가노이드’이다. 그리고 토모큐브의 홀로토모그래피 현미경은 ‘오가노이드’를 염색, 파괴하지 않고 분석하는데 필수적이면서도 거의 유일한 도구이다.
그래서 NAM을 장려하기 위해 美 NIH(국립보건원)은 신규 오가노이드 개발 센터에 $87M의 예산을 배정했다. 이 센터는 당연하게도 토모큐브의 홀로토모그래피 현미경을 구매할 수밖에 없을 것이다.
만약 투자자가 차세대 조직관찰 도구로서 홀로토모그래피 현미경이 어떤 의미를 갖는지 알았다면 뉴스를 쫓기보다 뉴스가 저절로 찾아드는 토모큐브 주식을 사고 기다릴 수 있었을 것이다. 그리고 개인적으로는 이런 것들이 앞으로 토모큐브를 찾아들 수많은 좋은 뉴스의 극히 일부라고 생각한다.
MongoDB
12.2일 MDB는 예상치를 초과하는 Atlas 성장률을 실적으로 발표한 데 따라 크게 상승했다. (실적 발표 내용은 최대한 빨리 정리해서 분석 글로 올리겠다)
MDB도 마찬가지다. AI에 필수적으로 사용하는 NoSQL DBaaS 선도 기업이다 보니 주가는 계속 좋을 수밖에 없다. 실적 발표는 그러한 내재가치를 따라오는 그림자 같은 존재다.
DoorDash
도어대시는 수익성 악화로 주가가 폭락한 이후 다시 점진적으로 회복하는 추세를 보였다. 나는 도어대시에 수익성을 요구하는 시장/주주들을 이해할 수 없다. 플랫폼 기업은 MAU가 협상력과 수익성, 성장성의 원천이다. 게다가 DASH는 전 세계 시장을 하나로 묶는 플랫폼이 아니라, 지역별 로컬 커머스 생태계를 조성해나가는 보다 작은 단위의 플랫폼 비즈니스를 BM으로 한다.
따라서 지리적 확장이 무엇보다 중요하며, 인수합병, 신규 진출 시장에서의 광고는 필수적이다. 그것이 미래의 더 큰 성장으로 돌아온다는 것을 세계 최대 외식시장인 미국에서 증명했다.
Freightos Ltd.
프레이토스는 아픈 손가락이 되었다. (주가만)
하지만 마찬가지로 전혀 걱정스럽지 않은 손가락이다. 성장은 여전히 순조로우며, 일회적 매출의 미인식으로 주가는 내렸지만 그것이 내재가치의 하락을 의미하지 않는다. 무엇보다 경영진이 26년말 BEP 달성에 자신감을 보이고 있다.
끝까지 가면 결국 큰 수익이 기다리고 있을 것이다. 마치 ‘어차피 남편은 류준열’이었던 것처럼.
까페 리뷰
오랜만의 까페 리뷰다. 11월에 기업을 추천하고 이에 대해 공부하는 프로세스를 처음 하다 보니 후보 추천 기업 수가 3개로 많지 않다.
3D 프린터 기계(76.7%), 3D 프린팅 서비스(22.9%)를 제공하는 회사로, 사실 3D 프린팅 기술이 각광받던 시절이 지나가고 어떻게 보면 철지난 회사로 볼 수 있다. 하지만 3D 프린팅이 더 경제적이거나, 다른 방법으로 구현이 힘든 부품 등 필요한 분야는 분명히 존재하기 때문에 기술이 개발되었던 것이고, 현재는 산업이 많이 재편되고 시장의 관심으로부터도 멀어져 멀티플도 정상화되어 투자하기 적절한 시점이 아닐까 생각되었다.
특히 링크솔루션은 8년 연속 흑자를 내다가 증설로 인해 일시적으로 적자전환했다고 하니, 더욱더 투자하기 좋은 시점이 아닐까?
개인적으로 소비자로 사용을 해봤던 앱이어서 관심이 더 갔었다. 내가 사용했던 시점은 2022년이었는데, 번역 퀄리티가 상당히 좋았던 기억이 있다. 언어 데이터 제공을 주된 BM으로 한다고 하는데, AI 시대에 해자가 깊어질지, 아니면 AI를 활용한 빅테크의 업역 침범으로 인해 해자가 얕아질지 좀 고민을 해봐야 할 흥미로운 주식이라 생각했다.
우선 실적 지표는 급격한 성장세를 바탕으로 막 흑자전환을 하면서 PER이 정상화되고 있는 상황으로, LTO에서 커버하고 있는 다수 기업들과 유사한 추이를 보이고 있다.
그래피
임플란트, 치과영상 등 장비는 많이 공부해봤었는데, 치과 교정 장비는 생소하여 관심이 갔다. 피부미용/성형 장비 회사들이 동반상승하던 시절이 있었는데, 비슷한 카테고리로 한국 기업 그래피가 비교우위를 갖고 있다고 볼 수 있지 않을까?
어렸을 때 교정을 하던 친구들이 상당히 불편해하는 것을 옆에서 지켜봤었는데, 이러한 불편함을 의미있게 개선할 수 있다면 상당히 좋은 BM이라고 생각된다. 이를 다른 기업이 모방하는 것이 불가능한지, 실제로 다른 치료 방법과 성능, 편의성이 얼마나 더 나은지 등에 대한 스터디가 필요할 것이다.
원전 스터디
모든 스터디 작성 글을 살펴보고, 내가 궁금한 점들을 GPT에 물어봐서 답글로 검토 결과를 남기고 있다.
다들 충실히 분석을 해주셔서 내가 혼자 공부해서는 파악하기 어려웠던 내용, 그리고 새로운 관점에서 투자 가능성 같은 것들을 검토해볼 수 있었다.
다음 주까지 피드백-수정을 거쳐 공부해보고, 나 나름대로도 원전 분야에 대한 공부-정리를 거쳐 1차적인 결론을 내려보려고 한다.
다음 스터디 주제
공부해보고 싶은 주제가 있으신 분들은 언제든지 제안해준다면 내가 가장 먼저 스터디원이 되어 같이 공부할 방법을 찾아보려 한다. 만약 제안할 사람이 없다면 중국 AI 밸류체인을 두 번째 주제로 스터디를 해보고 싶다.
가치투자 커뮤니티를 성장시켜나가고 있습니다. 운영 계획과 방향성을 한 번 읽어보시고, 텔레그램과 유튜브 채널을 통해 소통하고 있으니 공감이 가신다면 참여해주세요! 쌍방향 소통을 원하는 분들은 카카오톡 채널로 와 주시면 좋을 거 같습니다. 자료실을 통해 리포트, 뉴스도 공유하고 있으니 참고하시면 도움이 될 거 같습니다.
원전 산업과 관련된 주식이 상당히 가파르게 주가가 올랐다. 하지만 지금의 주가 상승이 유망성을 일부만 반영하고 있으며, 앞으로 상당히 장기간 지속될 메가트렌드라고 한다면 지금도 투자할만한 가치가 있다.
이에 대해 좀 더 구체적으로 공부해보기 위해 스터디를 시작하게 되었으며, 나 또한 스스로 원전 밸류체인에 대해 공부하기 위해 열심히 리포트도 읽고 필요한 정보를 정리해봤다.
글로벌 원전 발전 용량 증가
1) 화석연료 에너지 가격 급등(현재는 낮은 수준을 유지중이나 추가하락 가능성 낮음) 2) 전기차, 자율주행, 클라우드/플랫폼, AI 데이터센터, 제조업 자동화 등 고전력 인프라 수요 3) 탄소 중립에 대한 요구 부응을 위해 재생에너지, ESS만으로 부족 이라는 메가트렌드로 인해 원전은 장기 초과수요 국면으로 진입하고 있다.
세계적으로 신규원전 건설, 원전 재가동, 수명연장 트렌드가 확산되고 있다. 미/EU는 수명연장, 신규 건설 동시 추진, 중/인도/중동은 신규 원전 상업 가동 개시 단계에 있다.
앞서 설명한 대체공급 요인, 수요 요인, 탄소중립 요인에 따라 글로벌 원전 발전용량은 보수적 시나리오의 경우 56%, 적극적 시나리오의 경우 152% 성장할 것으로 예상된다. 이는 CAGR로 계산할 경우 각각 1.66%, 3.36%로 저성장 시장이라 인식할 수 있다.
하지만, 현재의 원전 발전용량은 대체로 오래전 건설되었던 원자로의 운영에 따른 것이다.
지난 20년간 세계 원전 발전량은 정체 상태를 보여왔으며, 2024년에도 전 세계 전력 중 원자력 비중은 약 9.0%로 1996년의 17.5%에서 절반 수준으로 떨어졌다.
하지만 최근 들어 한동안 정체되었던 신규 원전 건설이 다시 증가세로 돌아서려 하고 있다. 지난 10여 년간 신규 원전 착공은 주로 아시아 지역에 집중되었는데, 2014~2024년에 전 세계에서 가동된 신규 원전 68기 중 56기가 아시아 국가에서 건설되었다.
2024년에는 전 세계 9기의 신규 원자로 건설이 시작되었는데, 이 중 6기는 중국에서, 나머지는 러시아, 파키스탄(중국 주도), 이집트(러시아 주도)에서 시작되었다. 이러한 수치는 이전 수년간과 비교해 약간 늘어난 것으로 볼 수 있다. 실제로 2025년 중반 기준 전 세계 건설 중인 원자로는 63기로, 전년 대비 4기 늘어났다.
국제에너지기구(IEA)는 현재 각국 정부의 원자력에 대한 관심이 1970년대 오일쇼크 이후 최고 수준이며, 40여 개국이 신규 원전 도입이나 확대를 계획하고 있다고 밝혔다.
핀란드는 2023년에 서유럽에서는 15년 만에 처음으로 신규 원자로(올킬루오토 3호기) 상업운전을 시작했고, 프랑스는 2022년에 향후 6기의 신규 원전을 건설하기로 결정하는 등 오랜 공백 후 건설 재개 움직임을 보이고 있다. 미국도 2023년에 조지아주 보글(Vogtle) 3호기를 가동하여 수십 년 만에 첫 신규 원전을 상업운전에 돌입시켰다. 이렇듯 주요국들이 오랜 기간 중단되었던 원전 건설을 재개하거나 검토함에 따라, 한동안 정체되었던 원전 산업이 다시 성장 국면에 진입하는 것으로 해석될 수 있다.
원전 투자 수요 회복
미국의 경우 60~80년대에는 전력 산업이 ‘수익률 규제 제도’하에 운영되면서 예상치 못하게 공사비용이 증가하더라도 전력회사는 전기요금 인상을 통해 보상받을 수 있었다. 제도가 불확실성을 완화해주면서 원전으로 자본이 쉽게 유입된 것이다. 하지만 90년대 이후 전력산업 자유화가 추진되어 수익이 규제요금이 아닌 시장가격에 의해 결정되게 되면서 비용 초과 리스크를 요금으로 전가할 수 없게 되었다. 금융기관들은 높은 초기투자, 장기 회수기간, 정책 불확실성을 반영하여 美 원전을 리스크가 큰 자산으로 분류했으며 신규 원전 프로젝트는 급격히 위축되었다.
하지만 각국에서는 자금조달 측면에서의 지원제도를 보완하여 원전 기술 및 리스크를 분산시키는 금융 공학 발전으로 인해 금융 접근성이 개선됐다. 또한 인프라 투자 시장 성장 속에 대기자본이 ’24년말 $360B 규모로 증가하였다.
글로벌 친원전 정책 트렌드
발전 산업은 건설이 결정되면 장기간이 소요되며, 원전은 특히 그 기간이 10년 이상이다. 또한, 안전 규제, 에너지 가격 및 보조금때문에 정부 정책 의존도가 높다. 따라서 이를 결정하는 에너지 안보/수급 환경 변화로 장기간의 기업 내재가치가 변화하게 되며, 이러한 변화와 주가 변화의 괴리를 잘 찾는다면 좋은 장기 가치투자 대안을 찾을 수 있다.
쓰리마일, 체르노빌, 후쿠시마 사고로 촉발된 부정적 여론으로 주요국은 탈원전을 결정했으나, 최근 전동화 트렌드, 클라우드/AI/데이터센터로 촉발된 전력 수요 급증과 러우전쟁, 탄소중립, 재생에너지 간헐성 등 공급측면의 불안정성은 주요국 정책 방향을 친원전으로 되돌리기 충분하다.
에너지 정책의 3대 축으로 환경-안보-경제성을 강조하는데, 과거 환경이 강조되었다가, 현재는 안보가 강조되는 상황으로 전환된 것으로 보인다.
이에 따라 세계적으로 중러를 제외하고 감소하던 신규 원전 건설은 반등될 것으로 기대된다.
또한 학습효과를 노릴 수 있는 연속 발주+표준화 프로젝트가 일반화되면서, 산업 턴어라운드가 단기 모멘텀에 그치지 않고 추세적 성장을 이끄는 트렌드로 변화하고 있다.
한국의 원전 정책
11차 전력수급기본계획(‘25.2월, 전기사업법에 따라 2년 주기로 수립하는 중장기 전력 계획)에서 원전은 ’38년까지 발전량 비중 35.2%로 비중이 증가했다(10차, ’36년 34.6%).
정책목표 달성을 위해 1. 신한울 3, 4호기 건설(+2.8GW) 2. SMR 건설(+0.7GW) 3. 원전 설계수명(40년) 이후에도 안전성 평가 이후 연장(10년 단위) 등 방안을 추진하기로 하였다.
12차 전기본에서는 석탄발전 조기종료, 신재생에너지 확대 등이 구체화될 예정이며, 신규 원전 추가 등 정책방향이 전력정책심의회에서 논의되는 동향은 모니터링이 필요하다.
한국 원자력 발전 밸류체인은 국내 원전한수원을 중심으로 구축된 밸류체인을 기반으로 폴란드, 사우디, UAE 등 국가로의 원전수출을 추진중이다.
미국의 원전 정책
세계 최대 시장인 미국은 AI와 제조업 리쇼어링으로 인해 전력 수요가 급증하고 있다.
이에 따라 트럼프는 ‘25.5월 행정명령을 통해 1) 美 NRC(원자력규제위원회)를 개혁하여 원전 인허가 소요 기간을 단축하고 원전 용량을 현재 100GW에서 ’50년까지 400GW까지 확대하는 한편, 2) ‘26.7월까지 3개의 실험용 원자로 실증 추진, 3) ’30년까지 대형원전 10기 건설을 통한 공급망을 강화하는 등 종합적인 정책를 발표했다.
더 나아가 ‘25.6월 트럼프는 독립 규제기관인 NRC에 위원장 인사 개입을 통해 압력을 행사한다.
한국 밸류체인은 웨스팅하우스와 ‘지역별 구분’에 합의하여 유럽은 웨스팅하우스, 아시아(중동, 터키, 카작, 동남아, 한/중, 인도 등)에서는 한수원이 사업을 추진하는 것으로 합의한 바 있다. 하지만 트럼프의 공격적 원전 증설 목표에 따라 동맹국 밸류체인에 미국내 사업 참여를 요청할 가능성이 높아지고 있다.
’50년 400GW로 용량이 확대되는 가운데, 현재 용량 100GW중 퇴역 용량을 30GW로 최소화하면 신규용량으로 330GW가 필요하며, SMR이 200GW 설치된다면(DOE 시나리오), 신규 대형원전은 130GW가 필요한 상황이며, 건설기간 10년을 가정했을 때 ’26~’40년간 매년 8.7GW, 약 8기가 착공되어야 하는 상황이다. 이에 따라 쇼티지가 심화되며, 자본조달의 문제도 발생한다.
미국은 시장이 크지만 타국들과 달리 수직 계열화된 밸류체인이 구성되어 있지 않고, 민간 기업들에 공급망이 분산돼 있어, 다른 국가 기업들의 진출 여력이 높다.
미국은 이러한 공급 능력상의 취약점을 인식하고 공백이 존재하는 프로젝트 관리(PM), 시공, 일부 제작 공정 등에서 한국 기업 파트너를 모색할 가능성이 높다. 또한, 중국조차도 리스크 완화를 위해 러시아 노형을 설치하고 있음을 고려하면 모든 원전 생산을 웨스팅하우스에 의존하는 것은 리스크가 큰 선택이다. 그리고 동맹국의 미국 원전 지분투자를 허용하는 ADVANCE Act의 입법 취지를 고려할 때 자본조달 여력 관점에서도 동맹국의 원전 건설 가능성이 높아졌다.
참고. 원자력 발전 원리(문과 관점에서 이해한)
우라늄 235(U238은 분열이 덜 일어나는 동위원소로, U235를 몇 %로 농축시키는지가 중요)를 연쇄 분열시킬 때 양성자-중성자 결합을 유지시키는 강한 결합에너지가 열에너지로 방출된다.
열에너지로 물을 끓여 수증기로 터빈을 돌려 전기를 생산한다. 이 때 핵분열로 열에너지를 만드는 원자로를 1차 계통, 수증기로 터빈을 돌리는 부분을 2차 계통, 터빈을 돌리고 나온 수증기를 해수로 식혀 다시 물로 액화시키는 부분을 3차 계통이라 한다.
가치투자 커뮤니티를 성장시켜나가고 있습니다. 운영 계획과 방향성을 한 번 읽어보시고, 텔레그램과 유튜브 채널을 통해 소통하고 있으니 공감이 가신다면 참여해주세요! 쌍방향 소통을 원하는 분들은 카카오톡 채널로 와 주시면 좋을 거 같습니다. 자료실을 통해 리포트, 뉴스도 공유하고 있으니 참고하시면 도움이 될 거 같습니다.
HIMS가 다른 기업과 어떤 점이 차별화되는지 잘 모르겠다는 문제제기가 있었다. (절대 이 글이 필요한 문제제기를 막는 방향으로 작용하지 않기를 바란다. 아무런 문제제기도 없는 것은 절대적으로 지양되어야 할 스터디 방향성이라 생각하며, 피드백을 해주신 카톡방 ‘DLO MELI GRAB SEA 신흥국’님께 감사드린다.)
사실, 그런 문제제기에 충분히 설득력있는 답을 내놓지 못한다면 애초에 투자 아이디어가 잘못돼 있는 것이라 생각하며, 시장은 이를 합리적으로 가격에 반영할 것이다. 이에 대해 내 의견을 제시해보고, 그에 대한 피드백을 받아보고 싶다.
Hims & Hers Health (HIMS), LifeMD (LFMD), Teladoc Health (TDOC)은 미국 텔레헬스 시장에서 각기 다른 모델로 성장해온 대표 기업들이다.
아래에서는 1) 수익성과 플랫폼 확장성, 2) 브랜드 가치, 3) 규모의 경제 4) AI 활용 5) 약가협상과 가격경쟁력 6) 규제대응 측면에서 이들 회사를 비교 분석해보려고 한다.
수익성 달성 여부 및 플랫폼 확장성
수익성과 성장성
세 회사 모두 2020년 이후 매출이 크게 성장했지만, 수익성 면에서는 차이가 뚜렷하다.
Hims & Hers는 2020년 매출 약 $1.49억에서 2023년 $8.72억으로 폭증했고(+65% YoY), 2025년 3분기 누적 매출은 $17.30억에 달한다. 초기에는 적자를 지속했으나, 순손실 규모를 2022년 $6,570만에서 2023년 $2,350만으로 축소했고, 2023년 4분기엔 $120만의 순이익을 내며 첫 분기 흑자를 달성했으며, TTM 기준 $134M의 순이익을 내고 있어 $9.11B에 비해 TTM PER이 68배로 다소 높긴 하지만 산정 가능한 멀티플을 보유하고 있다. 성장성 측면에서도 기울기가 여전히 가파르게 나타나고 있다.(’23년 65.5%, ’24년 69.3%)
Teladoc은 팬데믹 수혜로 2020년 ~$10.9억에서 2021년 ~$20.3억으로 매출이 급등한 뒤 2022년 $24.1억, 2023년 $26.0억으로 성장세가 둔화되었다. 대규모 인수로 인한 손상차손으로 2022년에 역사적인 $137억 순손실을 기록했고, 2023년에는 순손실 $2.20억으로 적자폭을 줄였지만 여전히 적자 상태다. 2024년에도 $1.0B의 GAAP 순손실을 내서 흑자 전환이 요원하다.
LifeMD의 매출은 2020년 $3,729만에서 2024년 $2.12억으로 성장(+39% YoY)했으나, 2025년 3분기 누적 약 $1.47억 수준으로 마찬가지로 성장이 정체되어 있다. LifeMD 역시 매년 적자를 내왔으며, 개선폭도 2023년 순손실 $2,370만에서 2024년 $2,199만으로 미미하다.
즉 Hims & Hers만 2025년 현재 GAAP 기준 사실상 흑자 전환을 이룬 반면, Teladoc과 LifeMD는 아직 순손실 상태에 머물러 있고, 개선의 가능성도 요원한 상황이다.
지금까지의 설명이 현실이었다면, 왜 이런 일이 일어났는지에 대한 설득력 있는 설명이 있다면 HIMS가 미국 텔레헬스 산업에 투자하려 할 때 유일한 투자 대안이며, 절대적으로도 설득력 있는 투자대안인지 납득이 가는 설명을 제시할 수 있을 것이다.
플랫폼 비즈니스 모델 및 확장성
이런 극명하게 갈리는 재무성과의 이면에는 차이가 나는 세 기업의 플랫폼 전략이 있다.
Hims & Hers와 LifeMD는 직접-to-소비자(DTC) 모델로 온라인 플랫폼에서 의료 상담부터 처방약 판매까지 수직 통합했다. 구독형 서비스를 통해 재방문을 유도하며, 빠른 전문분야 확장으로 플랫폼을 키우고 있다. 예컨대 Hims & Hers는 남성 성 건강·탈모 치료로 시작해 심리상담, 피부과, 체중관리(GLP-1 비만 치료) 등으로 영역을 넓혀 2025년 가입자 250만 명을 돌파했다.
LifeMD도 RexMD(남성 건강), ShapiroMD(탈모) 등의 브랜드로 전문 분야를 확장 중이다. 이러한 DTC 플랫폼은 이용자 수가 늘수록 의료진 네트워크와 약품 공급망을 효율화하여 규모 효과를 얻을 수 있다는 장점이 있다.
반면 Teladoc은 B2B2C 모델에 가깝게 보험사·고용주의 복지에 연계된 종합 원격의료 플랫폼으로 출발했다. 일반 진료부터 만성질환 관리(Livongo 인수), 정신건강(BetterHelp), 전문의 세컨드 오피니언 등 포괄적인 서비스를 제공하며, 전세계 80백만 명 이상에게 서비스를 제공할 정도로 규모가 크다. Teladoc 플랫폼의 확장성은 주로 기업 제휴와 보험 커버리지 확대로 나타났으며, 국제 진출도 활발하여 2025년 3분기 국제 매출이 전년 대비 15% 증가하는 등 글로벌 성장 여지를 보였다.
즉, Hims와 LifeMD는 민첩한 DTC 구독 플랫폼으로 빠른 카테고리 확장이 가능하고, Teladoc은 대규모 인프라형 플랫폼으로 폭넓은 서비스 제공과 글로벌 확장이 강점이다. 다만 Teladoc은 통합 플랫폼 구축 비용과 보험 청구 구조로 인해 수익화 속도가 더딘 반면, Hims는 비교적 가벼운 모델로 고성장과 동시에 흑자 전환에 근접했다는 차이가 있다.
이러한 전략의 차이는 앞으로 사업에서 세 기업간 성과 차이를 가져올 수밖에 없다. LifeMD는 규모의 경제를 달성하지 못했기 때문에 동일한 BM을 구성하고도 협상력이 낮으며, 가격 경쟁력이 떨어지고, 보다 신속하게 신규 질병 카테고리로 진입하는 것도 어렵다. Teladoc은 보험 청구 구조로 인해 DTC 구독 플랫폼들에 비해서도 더 확장 속도가 더디며, 고객 획득 경쟁에서 뒤처질 수밖에 없다.
이것이 현재까지의 성장성 차이로 나타났으며, 플랫폼 비즈니스에서 성장의 차이는 결국 수익성의 차이로 귀결된다.
브랜드 가치
브랜드 인지도 및 호감도 (정량 지표)
Hims & Hers는 소비자 대상 브랜드 파워를 직접 소비자 시장에서 가장 두드러지게 구축했다.
Google 트렌드 분석에 따르면, 2017~2020년 거의 존재감이 없던 “Hims”에 대한 검색량(RSV)이 2020~2023년에 *“0에서 62”*로 급등할 만큼 대중적 관심이 커졌다.
이는 코로나 시기 텔레헬스 수요 급증과 맞물려 Hims 브랜드가 남성 건강 분야에서 인지도 급상승을 이뤘음을 보여준다. 구독자 수도 Hims는 2023년 말 153만에서 2025년 3분기 247만 명으로 증가해 플랫폼 이용자가 빠르게 확산 중이다. 앱 다운로드 및 SNS 팔로워 면에서도 Hims는 인스타그램, TikTok 등을 통해 젊은 층 공략에 성공하며 높은 팔로워 수를 확보하고 있다.
Teladoc은 2021년 J.D. Power 원격의료 만족도 조사에서 소비자 만족도 1위를 차지(1,000점 만점에 874점)하고, 90% 이상이 서비스에 만족한다는 결과가 나오는 등, Teladoc 브랜드에 대한 신뢰도와 만족도는 업계 상위권으로 평가된다. 또한 B2B 경로로 가입한 가입자수가 8천만명 이상으로 수치상으로는 가장 크다. 하지만, 소비자가 직접 브랜드를 선택하기보다는 보험 혜택으로 이용하는 경우가 많아 직접 체감되는 브랜드 인지도는 제한적이다.
LifeMD는 대중적 인지도는 낮지만, TIME 지 “America’s Growth Leaders 2026”에 선정되고 Deloitte Fast 500에 들 정도로 업계에서는 성장성을 인정받고 있으며, 내부 지표로 환자 만족도 98%를 발표하는 등 이용자 평가는 양호하다. 다만 LifeMD 자체 브랜드보다는 RexMD 등 하위 브랜드로 인지도가 분산돼 있고, 앱 다운로드 수도 선두 업체 대비 적어 전반적 브랜드 파워는 약하다.
이러한 기업들이 갑자기 영업 방식을 바꿔서 HIMS와 시장을 두고 치열하게 경쟁한다는 것은 상상하기 어렵다고 생각된다. 또한 이미 HIMS가 수익성을 확보하고 나서 시장을 빠르게 확장해나가고 있는 단계에서 비용을 감수하면서 출혈경쟁을 하는 것은 후발업체들에게 가능한 선택지가 아니다.
브랜드 질적 평가(평판)
Hims & Hers는 파격적이고 친근한 마케팅으로 디지털에 익숙한 젊은층에 호감도를 높인 사례로 자주 언급된다. 부끄럽기 쉬운 탈모나 성기능 문제를 선인장 이미지 등 유머러스한 광고로 풀어내고, 유명인 제니퍼 로페즈와의 협업으로 여성 탈모 제품을 알리는 등 적극적인 인플루언서 마케팅을 전개했다.
또한 패션 플랫폼 REVOLVE와 파트너십을 맺어 뉴욕 패션위크에서 단독 웰니스 파트너로 참가하는 등 MZ세대와 소통하는 브랜드 전략을 펼쳤다. 이런 노력으로 Hims는 NPS(순추천지수) 75점을 달성해 업계 평균(50점)을 크게 상회했고, 사용자들이 “개인 맞춤 의료의 만족감”을 느끼고 있다.
반면, 소비자 리뷰 사이트에는 Hims에 대해 “비싼 가격에 비해 효과가 크지 않다”, *“취소가 어렵고 고객응대가 미흡하다”*는 불만도 일부 있으며, FDA 경고에서 지적됐듯 과장된 광고 (예: 슈퍼볼 광고에서 부작용 언급 누락)로 신뢰도 저하 우려가 지적되기도 했다.
Teladoc의 브랜드는 전반적으로 “원격의료의 대명사”로 인식되며, 기업·병원 관계자들에게 신뢰도가 높다. 2022년 대규모 손상차손 이후 주가 폭락으로 투자자 평판은 타격을 입었지만, 의료 서비스 품질 측면에서는 Teladoc 소속 의사들의 전문성과 24/7 접근성에 대해 긍정적 평가가 많다.
Teladoc의 정신건강 자회사 BetterHelp의 경우 젊은 층을 중심으로 빠르게 성장해 2022년 매출 10억 달러를 돌파했으나, 최근 성장둔화와 일각의 상담 품질 논란이 있어 평판 관리 과제가 되고 있다.
LifeMD는 리뷰나 평판 자료가 제한적이지만, “글로벌 제약사와 협력하여 저렴하게 약을 공급한다”는 최근 홍보나 BBB에 접수된 환불 문제 해결 노력 등을 내세워 신뢰 구축을 도모하고 있다.
규모의 경제
고객당 비용(CAC) 및 운영 효율 비교
세 회사 모두 규모 확대에 따라 고객 획득 및 운영 비용 효율을 개선해 왔다.
Hims & Hers는 마케팅 효율 향상으로 CAC를 약 $45 수준으로 유지하며 매출 대비 판관비 비율을 낮추고 있다.
적극적인 입소문 전략과 제품 다각화 덕분에 신규 고객 모집 비용이 안정화되고, 구독 모델로 LTV(고객생애가치)를 극대화하는 구조다.
LifeMD 역시 2022년 이후 마케팅 비용 비중을 75%에서 50%로 축소시키며 효율을 높였다. 또한 보험 커버리지 확대를 통해 CAC를 추가로 절감할 계획으로, 기존에 전액 현금결제로 모객하던 부담을 줄이고자 한다. (수익성 확보도 좋지만 광고비를 절감한다는 것은 결국 고객 확보 경쟁에서 뒤쳐지는 것을 의미한다고 생각된다)
Teladoc은 개별 소비자 대상 CAC 개념이 모호하다. 보험자/기업 계약을 통한 회원 확보가 주이기 때문에, 전통적인 디지털 광고비 대신 영업인력·파트너십 비용이 든다.(이는 수익성 확보 측면에서 그만큼 ‘천장이 낮은’ 구조라고 보여진다) Teladoc의 BetterHelp 부문은 예외적으로 DTC 광고를 많이 했는데, 2022년 후반 광고비를 절감하여 수익성 개선에 나선 바 있다.
결과적으로 Teladoc의 조정 EBITDA 마진은 2023년 기준 12.6%로, 매출 대비 마케팅비가 적은 B2B 모델 특성상 Hims(2023년 12%)와 유사한 수준까지 올라왔으나, 그만큼 성장은 제한적이다.
운영 효율성과 영업 레버리지
Hims & Hers의 경우 매출 급증에도 운영비용 증가율을 억제하며 규모의 경제를 실현 중이다. 2025년 3분기 Hims의 조정 EBITDA가 매출보다 빠르게 증가하고(+53% YoY), 영업현금흐름이 크게 개선된 것은 운영 레버리지 확보를 의미한다.
LifeMD도 85% 이상의 높은 총마진율을 꾸준히 유지하고 있고, 2025년 3분기 기준 “Telehealth 부문 조정 EBITDA +30% 증가” 등 소규모이지만 수익성 개선 조짐을 보인다.
Teladoc은 대규모 매출에도 불구하고 아직 GAAP 적자지만, 조정 EBITDA 기준으로는 $3억+ 흑자를 내고 있어 규모 확대에 따른 기본 영업효율은 확보한 편이다. 다만 Teladoc은 인수자산의 상각과 거액의 고정비(본사인력, R&D)로 인해 GAAP 이익 전환이 지연되고 있다.
✔ 평가: Hims & Hers가 동일 매출 대비 이익창출 효율을 높여가는 추세인 것은 분명하며, 이는 규모의 경제 작용을 보여준다dcfmodeling.com. 특히 반복구매 구독모델 덕에 가입자가 늘수록 추가매출이 곧장 이익으로 연결되는 측면이 있다. 다만 완벽한 규모의 경제 달성 여부를 판단하려면 한두 해 더 추이를 지켜볼 필요가 있다. 신규 사업의 마진 영향, 경쟁구도의 변화 등이 변수이기 때문이다. 현 단계에서는 *“Hims가 동종사 대비 한 발 앞서 규모의 경제 효과를 실현 중”*이라고 평가할 수 있으며, 실제 조정 EBITDA 마진 개선과 흑자 전환으로 이를 입증해 보였다dcfmodeling.com. 그러나 장기적 안정성 측면에서는 투자 확대에 따른 비용 부담도 존재하므로, 향후 지속적으로 영업이익률과 순이익률이 상승한다면 비로소 완전한 규모의 경제 달성이라고 볼 수 있을 것이다.
AI 전략 및 활용 성과
AI는 세 기업 모두 미래 경쟁력의 핵심으로 삼고 있으나 접근 방식에 차이가 있다.
Hims & Hers는 방대한 DTC 데이터를 바탕으로 맞춤 의료를 위한 AI 솔루션을 개발 중이다.
2024년 베타 출시한 “MedMatch”는 수백만 건의 익명 환자 데이터에서 학습한 알고리즘으로 불안·우울 환자에 최적치료를 매칭해주는 시스템으로, 향후 전 진료영역으로 확대할 계획이다.
또한 자체 EMR에 AI 챗봇을 접목해 문진 시간을 단축하고, “개인별 추천 치료”를 제안함으로써 사용자 경험 개선과 NPS 상승(75점)에 기여하고 있다.
Teladoc은 주로 병원·의료진 대상 AI 솔루션을 내놓고 있다. 2024년 입원환자 낙상 위험 예측 AI를 상용화한 데 이어, 2025년에는 병원 내 폭력징후 감지 AI를 발표하여 현장 의료진의 안전을 돕는 등 의료현장에 특화된 AI 서비스를 개발 중이다. 경영진은 “우리는 이미 방대한 고객 기반을 보유해 AI 솔루션 스케일링에 유리하다”고 밝혔으며, 수백만 명의 모니터링 데이터를 활용한 만성질환 관리 AI, 화상문의 자동 triage AI 등도 연구하고 있다.
LifeMD는 AI 관련 대외 발표는 적지만, 플랫폼 자동화와 챗봇 상담 초안 작성 등 기본적 활용은 도입한 것으로 보인다.
전반적으로 소비자 경험의 개선을 위해 AI를 적극적으로 활용하는 기민한 움직임을 보이는 것은 HIMS라 생각된다.
약가 협상력 및 파트너십 네트워크
제약 및 파트너 네트워크 구축 면에서도 차이가 나타난다.
Hims & Hers는 자체 약국 인수를 통해 복제약 조달망을 확보하고, 특정 치료제의 독점 제휴를 추진해왔다. Hims는 Wegovy(semaglutide)와 유사한 자체 조제 주사제를 공급하여, 비보험 환자들에게 브랜드 약 대비 저렴한 가격으로 제공하고 82%의 높은 마진을 유지했다. 또한 오리지널 발기부전 치료제인 Stendra를 온라인 독점 판매하는 등 제약사와 전략적 제휴를 맺어 차별화된 제품 라인업을 구축하기도 했다.
LifeMD는 대형 제약사와의 협업을 전면에 내세우고 있다. 2025년 11월 Novo Nordisk(위고비 제조사)와 Eli Lilly(마운자로 제조사)와의 파트너십을 발표하며, 업계 최저 현금가격으로 GLP-1 비만약 제공을 약속했다. 이를 통해 LifeMD는 환자 유치력을 높이고 공급사와의 관계도 강화하고 있다.
Teladoc은 보험사·의료공급자 네트워크와의 파트너십이 핵심이다. 미국의 주요 보험사(예: Aetna, Blue Cross 등)들과 계약하여 그들의 가입자들에게 Teladoc 서비스를 기본 옵션으로 제공하고 있고, 대형 고용주(PepsiCo 등)와도 직업복지 차원의 원격의료 제공을 협력하고 있다. 또한 병원망(예: HCA, Mayo Clinic)과 제휴하여 전문의 가상 협진 서비스를 연계하는 등 B2B 파트너십 네트워크가 탄탄하다. 약가 협상력 측면에서 Teladoc은 직접 약을 판매하진 않지만, 만성질환 관리 프로그램(Livongo 인수부문)에서 의료소모품·약품 구매시 대량구매 파워를 발휘할 수 있다.
규제 대응 및 DTC 모델 강점
규제 환경에 대한 대응과 사업 모델의 강약점도 살펴볼 수 있다.
DTC 모델의 장점은 환자와 직접 관계를 맺기 때문에 브랜드 충성도 형성과 데이터 수집이 용이하고, 전통적 의료 규제를 일부 회피하여 신속한 시장 출시가 가능하다.
Hims와 LifeMD는 이러한 DTC 이점을 활용해 팬데믹 기간 원격의료 규제 완화에 발맞춰 폭발적으로 성장했다. 그러나 DTC의 단점은 규제 리스크를 기업이 직접 떠안는다는 점이다. 최근 FDA가 GLP-1 비만약 컴파운드 제제의 오남용과 광고 관행을 문제 삼아, Hims & Hers를 포함한 수십 개 업체에 경고 서한을 발송했다. 특히 Hims의 슈퍼볼 광고가 부작용 고지 없이 약효만 과장했다는 지적은, 직접소비자 광고(DDC)를 핵심 마케팅으로 삼는 DTC 모델의 규제 취약성을 드러낸다.
이에 반해 Teladoc은 의료서비스 제공자로서 HIPAA 등 의료정보보호를 준수하고, 광고보다는 전통 채널을 통해 성장해 상대적으로 규제 리스크가 낮다. Teladoc이 직면했던 규제 이슈는 주로 주(州)별 원격진료 면허 문제 등이었는데, 이는 2010년대에 상당 부분 해결되어 현재는 안정적인 운영이 가능하다.
하지만 신시장 개척 측면에서는 DTC 모델이 강점을 보인다.
Hims는 전통적으로 낮은 의료 접근성을 보인 지역(미국 내 농촌 등)에서 온라인 플랫폼으로 고객을 확보했고, 이는 “디지털 플랫폼이 의료 공백을 메웠다”는 평가를 받는다. LifeMD 역시 원격 1차진료 LifeMD+를 내세워 주치의가 부족한 지역을 공략 중이다.
반대로 Teladoc은 보험이 적용되는 대도시 중심으로 이용자가 분포하여, 의료 취약지 개척 측면에서는 DTC보다 느린 경향이 있다. 그럼에도 Teladoc 모델은 보험급여로 가격 장벽을 낮추고, 대규모 기업체 직원들에게 접근한다는 강점이 있다.
결론
전체적으로 회사의 상황변화에 대한 대처, 소비자에게 더 신속히, 더 나은 경험을 제공하려는 DNA 측면에서 HIMS는 모든 분야에서 다른 텔레헬스 기업과 분명히 다른 전략을 취하고 있다. 플랫폼 구축, 브랜드 이미지, 규모의 경제와 광고, AI 활용, 약가협상, 규제 대응, 모든 면에서 HIMS의 전략은 성장과 소비자 가치에 초점이 집중되어 있다.
그것이 현재까지의 차별화된 성장률과 수익성으로 나타났다. 이러한 차이점은 앞으로 직면할 수많은, 서로 다른 상황에도 불구하고 지속적으로 경쟁사와 차별화된 성장성과 수익성을 시현하게 하는 장기적 요인이 될 것으로 판단되었다.
가치투자 커뮤니티를 성장시켜나가고 있습니다. 운영 계획과 방향성을 한 번 읽어보시고, 텔레그램과 유튜브 채널을 통해 소통하고 있으니 공감이 가신다면 참여해주세요! 쌍방향 소통을 원하는 분들은 카카오톡 채널로 와 주시면 좋을 거 같습니다. 자료실을 통해 리포트, 뉴스도 공유하고 있으니 참고하시면 도움이 될 거 같습니다.
’25년 들어 주식 성과 측면에서 최악의 한 주를 보냈다. 하지만 그럼에도 불구하고 변한 게 없다면 나아가야 한다. 이번 주에 가장 내게 큰 위안을 주었던 노래는 ‘위대한 쇼맨’의 ‘This is me’였다.
When the sharpest words wanna cut me down I’m gonna send a flood, gonna drown them out I am brave, I am bruised I am who I’m meant to be, this is me Look out ’cause here I come
And I’m marching on to the beat I drum I’m not scared to be seen I make no apologies, this is me
어떤 어려움이 있더라도 나는 나로 살아갈 것이며, 변명하지 않고 나아가겠다는 담대한 가사다. (I make no apologies를 영상에서는 ‘사과따윈 하지 않아’로 번역했는데 오역에 가깝다. 그보다는 ‘변명하지 않아’가 맥락상 더 적절한 번역이 아닐까 싶다.)
실제 주가 추이가, 실적이 내 생각과 다르게 나오면 변명을 하고 싶기도 하다. 그리고 모두가 지켜보고 있는 초과수익률이 -10% 아래로 떨어지면 민망하고 부끄럽다.
하지만 이것이 내 투자의 현 주소이며, 약점을 인정하는 것으로, 그리고 앞으로 더 치열하게 개선을 고민하면서 나아가겠다는 다짐으로 이번 주 LTO 커버를 시작해보려고 한다.
LTO 커버기업 성과
시드가 커지면 하락했을 때 손실도 커진다. 이번 주에는 하루 기준, 그리고 한 주 기준으로 가장 큰 평가손실을 경험했다. 마치 예방주사를 맞듯이 아픔을 겪으면서 내성이 생긴다. 아픈만큼 성숙해져야 할텐데..
CRGO(Freightos Ltd.)
가장 비중이 높았던 프레이토스 실적발표가 있었다. 매출은 나쁘지 않았지만 EPS 미스와 가이던스 역성장으로 주가가 급락했다.
약 30% 정도의 아픈 하락이었지만, 최종적으로 CRGO가 추구하는 디지털 물류 플랫폼으로서 지향점을 알고 있기 때문에 버티면서 더 지분을 늘려나갔다. 그리고 투자 아이디어를 재점검하는 시간을 가졌는데, 좀 더 내용을 다듬어서 조만간 공유하고 발표하려고 한다.
결론은 독립적인 항공 물류 플랫폼 선도기업으로서 시장지배력을 바탕으로 1. 해운 물류 분야로의 크로스셀링, 2. 부가서비스 수익화, 3. 네트워크 효과 등을 통한 성장 여력이 충분하다는 것이다.
부정적 요인들은 일시적인 것들이었다. EPS 미스는 실제 수익성과 무관한 워런트(아마도 전환사채 같이 주가에 연동되는 채권인 거 같다) 평가손실에 의한 것이고, 4분기 매출 역성장 가이던스는 설치형/일회성 솔루션 매출 감소에 따른 것이다.
그럼에도 ‘26.4Q BEP 달성 약속을 지키려는 경영진의 확고한 의지를 확인할 수 있었고, 관세 전쟁으로 인해 업황이 부정적이었음에도 유지된 매출 성장률과 개선된 GPM로 의지가 공허한 말에 그치지 않았다는, 장기적인 관점에서 긍정적 논리의 근거를 확인할 수 있었다.
DASH(DoorDash)
프레이토스 실적발표로 인한 상처에 DASH의 하락이 재를 뿌렸다.
매출 성장률이 이번 분기에도 YoY 27.35%를 기록한 회사를 어떻게 하면 성숙단계의 주식으로 볼 수 있는지 솔직히 궁금하다.
아직 Deliveroo 매출이 인식된 것이 아님을 Foreign Sales 수치에서 확인할 수 있다. 순수한 유기적 성장의 결과가 27.35%이다. 그리고 성장의 기울기가 가팔라지고 있다.
경쟁이 심화된다면 매출 성장이 둔화되어야 맞을 것이다. DoorDash에 해당되지 않는다. 아직 미국 배달 시장의 침투율은 낮고, 갈 길이 멀다. GPT를 활용하여 아래와 같이 거래액 기준 국가별 음식시장 대비 온라인 음식 배달 서비스의 침투율을 비교해본 결과 미국은 5%, 중국은 28%, 한국은 35% 정도로 나타났다. (국토가 넓고 인구 집중도가 낮아 한국 정도 침투율은 무리일 수도 있지만 5%는 아직 너무 낮다)
2024~2025년 온라인 음식배달 침투율: 미국·한국·일본·중국 비교
온라인 음식배달 침투율은 **전체 외식 시장 규모 대비 온라인 음식배달 시장 규모의 비중(%)**을 의미합니다. 아래에서는 미국, 한국, 일본, 중국의 2024년 기준(또는 가장 최근치) 외식산업 규모와 온라인 음식배달 시장 규모를 정리하고, 해당 비중(침투율)을 비교합니다. 자료는 각국 정부·공공기관 통계와 신뢰성 높은 시장조사 보고서를 우선적으로 사용했습니다.
미국 (United States)
전체 외식시장 규모: 2024년 미국 레스토랑 산업 매출은 사상 처음으로 약 1조 달러를 돌파했습니다nrn.com. 미국국립레스토랑협회(NRA)에 따르면 2024년 미국 음식서비스 업계(레스토랑, 바 등) 매출은 약 1.06~1.1조 달러 수준으로 추산됩니다nrn.com.
온라인 음식배달 시장 규모: 시장조사에 따르면 2024년 미국 온라인 음식배달 시장 규모는 약 500~530억 달러 수준으로 추정됩니다grandviewresearch.com. (추정치 간 차이가 있지만, Grand View Research 등은 2024년 미국 온라인 음식배달 매출을 526억7천만 달러로 보고했습니다grandviewresearch.com.)
침투율: 상기 수치를 종합하면, 온라인 음식배달의 침투율은 약 5% 수준으로 계산됩니다. 다만 주문 건수 기준으로 보면 배달이 차지하는 비중은 다소 높아, 2023년 기준 **미국 레스토랑 전체 거래의 약 8~9%**가 배달 주문으로 집계되었습니다user-35215390377.cld.bz. (2019년에 약 3~4% 수준이던 배달 비중이 팬데믹 이후 약 5%p 증가한 수치입니다user-35215390377.cld.bz.)
중국 (China)
전체 외식시장 규모: 중국 국가통계국에 따르면 2024년 중국 요식업(餐饮) 매출은 5조5,718억 위안으로 전년 대비 5.3% 성장하여 사상 최고치를 기록했습니다m.21jingji.com. (約 5.57兆 위안, 한화 약 1,150조 원 규모)
침투율: 2024년 기준 **온라인 음식배달 침투율은 약 28.0%**로, 중국 요식업 전체 매출의 약 4분의 1 이상을 배달 플랫폼이 차지하고 있습니다t.cj.sina.com.cn. 이 비중은 2019년에 약 13% 수준이었던 것이 팬데믹을 거치며 두 배 이상으로 상승한 것입니다foodtalks.cn.
대한민국 (South Korea)
전체 외식시장 규모: 글로벌 조사기관 Euromonitor에 따르면 2024년 한국 외식산업 시장 규모는 약 110조8천억 원으로 추산됩니다euromonitor.com. 코로나19 이전인 2019년 약 90조 원대에서 큰 폭으로 성장하여, 엔데믹 이후에도 높은 수준을 유지하고 있습니다.
온라인 음식배달 시장 규모: 2024년 한국의 음식배달 시장 규모는 약 38~39조 원으로 추정됩니다 (전체 외식의 35%가 배달인 점을 적용한 산출치). 실제로 한국의 음식 배달 거래액은 2022년에 약 26조6천억 원으로 정점을 찍은 후 2023년에 27~28조 원을 기록하며 지속 성장 중입니다hankyung.com. Euromonitor는 **2024년 배달 매출 비중이 35%**에 이르렀다고 보고하고 있습니다euromonitor.comeuromonitor.com.
침투율: **약 35%**로, 조사대상 국가 중 가장 높은 수준의 침투율을 보입니다euromonitor.com. 한국은 2019년 배달 비중이 18%에 불과했으나, 2020~2021년 팬데믹을 거치며 한때 40%까지 치솟은 후euromonitor.com, 현재는 30%대 중반의 안정적 비중을 유지하고 있습니다euromonitor.com. 이는 외식 지출의 1/3 이상이 배달앱 등을 통한 주문으로 이뤄진다는 의미입니다.
일본 (Japan)
전체 외식시장 규모: 일본은 2023년 시점에 외식산업 규모가 약 31조2천억 엔이었고yano.co.jp, 2024년에는 약 34조3,916억 엔으로 전년대비 4.7% 성장할 전망입니다note.com. (엔화 약세를 감안하면 한화 약 320조 원, 달러 약 2,300억 달러 수준)
온라인 음식배달 시장 규모: 2024년 일본의 음식배달 시장 매출은 7967억 엔(약 5.1억 달러)으로 집계되었습니다blackboxjp.com. 이는 전년 대비 7.6% 감소한 수치이나, 팬데믹 이전인 2019년에 비해서는 약 90% 증가한 규모입니다blackboxjp.com.
침투율:약 2.3% 수준으로, 조사 대상 국가 중 가장 낮습니다. 즉 일본 외식업 매출의 2% 남짓만이 배달 플랫폼을 통해 발생하고 있습니다. 일본은 전통적으로 배달 문화(出前)가 있었지만, 2020년대 들어서도 배달앱 침투율은 비교적 제한적이어서 한국·중국 대비 낮은 비중을 보입니다blackboxjp.com. (2020년 팬데믹 기간 크게 성장했으나, 2023~2024년에는 배달 수요가 일부 감소하는 추세blackboxjp.com.)
국가별 비교 요약
아래 표는 2024년 기준 각국의 전체 외식시장 규모와 온라인 음식배달 시장 규모, 및 **침투율(%)**을 한눈에 비교한 것입니다:
자료 출처: 각국 통계청 및 공신력 있는 시장조사 보고서(상기 각주 참조). 한국과 중국의 경우 정부 및 Euromonitor 등의 발표치를 사용하였으며, 미국과 일본은 업계 보고서 및 협회 통계를 인용했습니다. 모든 수치는 최신 연도의 값이며, 일부 침투율은 제공된 시장 규모를 바탕으로 직접 계산한 값임을 밝혀 둡니다.
마찬가지로 투자 아이디어 업데이트를 계획중이다.
MDB(MongoDB)
AI 거품론으로 인해 주가가 많이 내렸다. 솔직히 Kimi K2를 결제해서 사용해보고 있는 상황에서, 나도 미국 빅테크들이 AI에 들이고 있는 CAPEX가 과도하다는 생각을 하고 있다.
중국 AI 기업들의 전략은 오픈소스에 기반한 소프트웨어적 접근이다. 반면 미국 AI 기업들은 폐쇄적 모델이라는 차이가 있다. 그리고 누구보다도 미국 생태계의 성공을 바랄 젠슨황이 결국 승자는 중국이 될 거라고 한 데에는 이유가 있을 것이다.
이런 논란으로 AI 학습에 필요한 데이터를 관리하는 소프트웨어 기업들의 주가는 동반 하락했다. 그래도 그 중에서 가장 선방한 기업은 MDB였던 거 같다. 이번 주 기준 MDB $352.61 → $322.16(-8.6%), ORCL $222.85 → $198.76(-10.8%), SNOW $257.02 → 234.03(-8.9%)의 하락률을 보였다.
AI가 돌이킬 수 없는 추세라는 것은 무엇을 보아도 확실하지만, 그 승자가 미국 생태계가 아닐 가능성이 충분히 높으며, CAPEX 때려박기가 유일한 성공 방정식이 아니라는 것은 충격이다. (이와 별개로 이재명이 100조를 투자해서 만들려고 하는 소버린 AI 전략은 더더욱 지양해야 할 길이라는 것이 명확해졌다)
AI로 무엇을 할 수 있는가에 더 집중해야 한다. (중국 AI 모델을 사용하는 기업이라면 더 좋을 거 같다) 그리고 하드웨어, 인프라 기업들에 대해서는 조금 더 엄격한 잣대가 필요한 것 같다.
HIMS(Hims & Hers)
TrumpRx에서 비만치료제를 최저가로 소비할 수 있게 한다는 소식으로 주가가 많이 내렸다.
하지만, HIMS의 경쟁력은 다양한 질병을 하나의 플랫폼에서 통합하여 원스톱으로 관리할 수 있는 편의성과 미국 젊은 세대에 친숙한 브랜드 이미지를 구축한 데에 있다.
TrumpRx에서 비만치료제를 조금 더 싸게 공급한다고 하더라도, 지금까지 구매 데이터가 축적되어 있고, 다른 질병에 대해서 상담한 데이터가 저장되어 있는 HIMS 플랫폼에서 소비자들이 쉽게 이탈할 것이라고 생각되지 않는다. 그리고 다른 어느 텔레헬스 기업들보다도 발빠르게 서비스 카테고리를 확장하고 있다. 3분기에는 에스트로겐/테스토스테론 치료, 26년초에는 수명연장 카테고리로 확장이 예정돼 있다. 그리고 적극적인 크로스셀링의 결과로 ARPU가 $80대로 급증했다.
이런 논리는 비만치료제 이슈로 잠시 매출이나 수익성이 주춤하더라도 HIMS를 성장 궤도로 돌려놓을 근거가 된다고 생각된다. 그리고 이는 경쟁 텔레헬스 기업들과는 명백히 차별화되는 지점이다.
HIMS도 마찬가지로 투자 아이디어를 다시 한 번 업데이트할 계획이다.
토모큐브
토모큐브가 그나마 몇일간 긍정적인 주가 흐름을 보여주어 위안이 되어주었다.
토모큐브는 다수의 공동연구를 통해 염색이 불필요한 연구 레퍼런스를 쌓아가고 있다. 이는 오가노이드, 인공수정, 동물실험 대체 등 분야에서 토모큐브의 독점성을 빠르게 확장시켜줄 것이다. ‘25.3Q 실적보고서를 최대한 빨리 읽어보고 On track인지, 처음 분석할 때 발견하지 못한 리스크가 없는지 검토하여 결과를 공유하겠다.
무엇을 배웠으며, 어떻게 개선할 것인가
높은 변동성, 원인은? 유전적 다양성이 종족의 생존을 보장한다
투자하고 있는 기업들의 성격이 너무 비슷하다.
현재는 BEP 전후의 수익성을 보이며, 높은 확률이긴 하지만 아직은 증명되지 않은 미래 매출을 보고 투자하는 기업들로, 멀티플이 산정되지 않거나 너무 비싸다. (DASH, MDB, HIMS 최근 흑자전환, CRGO, 토모큐브 ’26년 흑자전환 예상)
또한 네트워크 효과가 해자의 근거인 기업들이 많기 때문에, 인터넷 기업 비중이 높다(DASH, MDB, HIMS, CRGO)
이런 기업들이 성장 포텐셜이 높은 것은 사실이지만, Unsung Hero가 너무 적다. 마치 모든 플레이어가 스타플레이어인 팀이 우승하기 어렵듯이, 누군가는 포트폴리오를 지키는 역할을 해줘야 하지 않을까 생각이 들었다.
분야별 스터디
물론 어려운 시기에 내 투자관에 공감해주는 몇백명의 동료 투자자가 있다는 것만으로도 심리적 지지가 된다. 하지만 거기서 조금 더 나아가야 스터디에 참여해주시는 분들께도, 플랫폼, 채팅창, 텔레그램에 들어와 있는 분들께도 도움이 되지 않을까?
그리고 나에게도 더 도움이 되는 방향이다.
지금은 너무 정보전달과 소통이 일방향적이다. 소통이 현재 이뤄지는 방향의 반대방향으로도 원활히 이뤄져야 하며, 스터디원간에도 소통이 강화되어야 한다.
시장에는 투자할 가치 있는 기업들이 너무 많다. 다만, 그런 기업을 혼자서 모두 공부할 수는 없다. 그래서 공부해볼 가치 있다고 생각되는 기업, 또는 산업을 정해서 가능한 스터디원들과 공부해보는 시간을 가져야겠다는 생각이 들었다. 처음에는 같이 리서치하는데 오히려 시간이 오래 걸릴 수 있다. 하지만 경험이 누적되면 점점 더 분업 효과가 나오지 않을까?
그리고 내가 아니더라도 같이 공부해볼 주제가 있다면 제안해서 결과물을 도출했으면 좋겠다. 그랬을 때 한 스터디원이 보유한 노하우와 역량이 확산되는 효과도 기대할 수 있을 것이다.
투자 아이디어 발굴 게시판 아래 ‘스터디 제안’ 메뉴를 신설하였다.
원전 밸류체인 스터디
첫 번째 주제로 원전 밸류체인을 제안한다.
조금 더 구체적인 내용들을 담아 까페에 올릴 예정이다.
에너지 수요는 경제성장에 따라 추세적으로 늘어날 수밖에 없으며, AI, 전기차, 오염원 집중 필요성을 고려해보면 전기 수요가 늘어날 거라고 쉽게 예측할 수 있다. 또한 미국, 한국 등 주요 국가 전력망 확충으로 전력 수요 확대 여건이 마련되고 있다.
그럼에도 불구하고 탄소중립의 목표는 포기할 수 없으며, 전력 계통의 안정적 운영을 위한 재생에너지의 간헐성 보완도 포기할 수 없다. 아무리 생각해봐도 답은 원전밖에 없는 상황이다.
하지만 산업 특성상 이해에 높은 전문성과 기술성이 필요하여 쉽게 공부하기 어렵다. 전에 혼자 공부해본 적 있지만 끝까지 하기 어려웠는데, 여러 명이 같이 한다면 필요한 수준의 이해에 도달할 때까지 완주할 동기를 제공해주지 않을까?
많은 참여를 부탁드린다.
피드백, 특히 커버기업
나는 내 자신의 한계를 알고 있다. 그렇기 때문에 두려움도 있고, 성과로 증명하기 위해 스트레스도 받는다. 만약 내 투자 방법이 최선이라는 완전한 확신이 있다면 스트레스 받을 이유가 없을 것이다.
더 나은 것을 위해 노력하는 같은 입장의 투자자라고, 실수를 하는, 많이, 크게 틀릴 수 있는 사람이라고 봐주시고 틀렸다고 생각된다면 집요하게 끝까지 납득이 갈 때까지 물어봐주시면 좋겠다.
분야별로 나보다 훨씬 잘 아는 분들이 많다. 오늘 보험에 대해서도 채팅창에서 이야기가 오갔는데, 그런 대화가 더 많아졌으면 좋겠다. 커버기업이라도, 모르는 부분을 없애려 하지만 정말 디테일한 부분까지 파고든다면 모르고 이해가 부족한 측면이 없을 수 없다. 가르치는 마음으로 인내심을 갖고 설명해주신다면 열심히 배울 마음을 갖고 있다.
투자 아이디어 발굴 게시판 아래 ‘커버기업 피드백’ 메뉴를 신설하였다.
가치투자 커뮤니티를 성장시켜나가고 있습니다. 운영 계획과 방향성을 한 번 읽어보시고, 텔레그램과 유튜브 채널을 통해 소통하고 있으니 공감이 가신다면 참여해주세요! 쌍방향 소통을 원하는 분들은 카카오톡 채널로 와 주시면 좋을 거 같습니다. 자료실을 통해 리포트, 뉴스도 공유하고 있으니 참고하시면 도움이 될 거 같습니다.
인카금융서비스는 진짜 잘 해나가고 있다. 다만 억울하게도 많은 시장 참여자들이 오해하고 있을 뿐이다.
기존 인카금융서비스의 성장 내러티브는 1. 국내 최대 독립 GA로서 다양한 보험상품을 판매할 수 있고, 보험판매전문회사 제도가 도입되면 종합 자산관리 서비스를 제공할 수 있어 양적, 질적으로 좋은 설계사가 자발적으로 모인다. 2. 좋은 설계사가 자발적으로 모이면 보험 시장에서 더 높은 비중의 매출이 인카금융서비스 채널을 통해 발생하여 협상력이 더 강해지고, 더 높은 수수료율을 요구할 수 있게 된다. 3. 수수료율이 높아지고, 전속 GA 대비 투명한 인센티브 구조를 운영함으로써 설계사가 더 열심히 할 유인이 크며, 이는 설계사들의 자발적 선택 경향을 더 강화한다.
일시적 충격으로 성장 경로에서 이탈하더라도 자연적으로 원래 성장 추세로 돌아가는 내재적 힘을 가진 기업에 투자한다면 흔들리지 않고 지속성 있는 투자를 할 수 있을 것이다. 앞서 말한 선순환 구조의 지속이 인카금융서비스가 가진 회복탄력성의 근거다.
인카금융서비스는 아래와 같은 이유로 인해 국내 주식에 대한 비중을 줄이는 가운데 포트폴리오에서 차지하는 비중을 줄였지만, 정말 비중축소가 아쉬운 Unsung Hero라고 할 수밖에 없다. 1. 현정권의 무분별한 재정정책으로 인한 원화가치 하락 2. 경제활동인구 감소라는 전체 경제의 축소 가운데 내수 시장에 국한되어 있는 사업 구조
현명한 투자자라면 다소 비중을 줄이더라도 이런 기업과 끝까지 동행해야 한다고 생각하며, 3분기 실적발표 및 그간의 뉴스들을 참고하여 투자 아이디어를 업데이트해보려고 한다.
BM의 이해
기존 투자 아이디어 : 협상력의 선순환과 보험판매 전문회사
인카금융서비스는 국내 최대 독립 GA로서 막강한 영업조직을 바탕으로 설계사 수가 꾸준히 늘어날 것으로 기대되었다.
독립 GA이기 때문에 1. 다양한 보험사의 상품을 취급하며, 2. 보험판매 전문회사 도입으로 종합 자산관리로 판매 상품이 더욱 확대되고, 3. 최고 수준의 수수료 협상력을 보유한 만큼 더 적극적으로 영업하려는 설계사들이 몰리는 선순환이 나타날 것이라는 전망이었다.
이에 따라 ’24년에도 설계사 수가 크게 증가하여 독립 GA 분야 선도기업으로 도약했다.
또한, 인카금융서비스에 대한 장기적 기대 요인으로 ‘보험판매전문회사’ 제도 도입이 있다. 기존 투자 아이디어에서 설명했던대로, 보험판매전문회사란 GA를 단순 보험모집 업체가 아닌 금융중개기관으로 격상시키는 제도로, 1) 도입되면 GA는 원수보험사에 대해 사업비(수수료) 협상 권한을 공식적으로 부여받고 2) 판매과정에 대한 책임 및 규제를 부담하게 된다. 3) 동시에 보험뿐 아니라 여타 금융상품(여신, 펀드 등)까지 판매할 수 있어 사실상 종합 금융회사에 준하는 업무 범위를 갖게 된다.
인카금융서비스는 일찍부터 이러한 제도 변화를 대비하여 보험을 넘어 금융, 보험, 자산 관리를 아우르는 종합 금융서비스 회사로의 진화를 목표로 제시해왔다. 이에 따라 업계 최대의 대면 영업조직을 기반으로 토탈 라이프 금융솔루션을 제공하는 자산관리회사로 변모할 수 있다는 투자 아이디어가 부각되었다.
3분기 업데이트
보험판매 전문회사
아쉽게도 보험판매전문회사 제도와 관련한 새로운 소식은 없었다. ‘25.3Q까지 보험판매 전문회사 법제화는 아직 진행중이다. 그럼에도 인카금융서비스는 종합금융 기업으로의 체질 개선을 착실히 추진하고 있다.
’24년 투자자문사 ‘헥사곤파트너스’, 대출중개법인 ‘모기지리더스’를 자회사로 편입했다. 이번 분기에는 저축은행 등 금융사 인수 검토뉴스가 나와 금융 영역으로 확장 계획을 시사했다. 이는 보험판매 전문회사 제도가 도입될 경우 곧바로 보험·대출·투자 등을 아우르는 종합자산관리 서비스를 제공하겠다는 전략의 일환이다.
회사는 내부 통제 강화, 디지털 보안체계 구축 등 제도권 편입을 위한 선제적 준비도 병행하여 차질 없이 추진하고 있다.
성장성
기존 투자 아이디어
IFRS17 도입 이후 보험사들이 신계약 판매를 강화하면서 GA 채널의 수익성도 긍정적 흐름을 보였고, 이에 따라 인카금융서비스의 가파른 매출 증가세가 지속될 것이라는 전망이 나왔다.
그 결과 인카금융서비스는 높은 매출 성장률을 시현하고 있다. 전년도와 올해 상반기 모두 두 자릿수의 견조한 성장세를 보이며 외형 성장을 이어왔고, 이는 GA업계의 구조적 성장과 맞물려 당분간 유지될 것으로 기대된다.
’25.상반기 매출은 4,689억원으로 전년 대비 18.3% 늘었고 영업이익도 13.7% 증가했다. ‘24.3Q부터 매출이 이연되었음을 감안하면 외형과 수익이 고르게 성장한 것으로 보인다.
3분기 업데이트
성장 추세의 확인
3분기 들어서도 매출 성장 기조는 유지되었다. ‘25.3Q 누적 매출은 약 7,400억원으로, 전년 동기 대비 약 17% 성장했다. 지난해 매출이 60% 이상 급증했던 기저효과, 매출 인식 기준 변화, 업황 둔화 우려를 감안하면, 이번 분기의 YoY 성장 및 QoQ 13%를 상회하는 성장은 충분히 높은 성장 잠재력을 증명한다.
설계사수 증가
이번 분기를 통해 이러한 설계사 수 증가 내러티브는 한층 강화되었다. 이는 ‘24.9월말 16,000명, ‘25.6월말 18,500명에서 ‘25.10월말 소속 설계사가 2만명을 돌파해 독립 GA 최초 기록을 세웠다(‘24.9월 대비 +25%, ‘25.6월 대비 +8.1%)
당초 투자 아이디어대로 설계사가 빠르게 늘어나 업계 최대 규모를 확고히 했다. 특히 대형 GA로 설계사 쏠림이 지속되어 앞으로도 우수 설계사의 합류는 계속될 전망이다.
설계사 1인당 생산성 확대
영업 인력의 양적 성장과 더불어 디지털 영업 인프라 강화로 1인당 생산성도 높아져 질적 성장으로 연결되고 있다.
보험 산업에 대한 이 저성장 우려 속에서도, 인카금융서비스는 GA 채널 확대와 신상품 수요에 힘입어 두 자릿수의 안정적인 매출 성장률을 이어가는 모습으로, 앞으로도 설계사 조직 확충과 디지털 인프라 강화로 지속적인 매출 성장이 기대된다.
결국 보다 안정지향적인 설계사들이 전속 GA에 남는 반면, 보다 공격적이고 더 높은 성과를 추구하는 설계사들이 독립 GA를 찾아오기 때문에, 설계사 구성이 질적, 양적으로 개선되며, 이것이 실제 지표로 증명되고 있다.
이와 함께 인카금융서비스는 불완전판매율 개선 등 영업 지표의 질적 향상도 이뤄져, 양적 성장과 질적 성장이 모두 뒷받침되는 긍정적 추세가 이번 분기에도 이어졌다.
계약부채 규모
3분기에도 이러한 잠재 매출 요인에는 큰 변화가 없다. 인카금융서비스는 지속적인 신계약 성장으로 향후 수익 인식이 예상되는 계약부채를 상당 규모 보유하고 있을 것으로 추정된다. 상반기 매출 성장률은 18%를 기록했지만 영업이익은 13.7% 증가에 그쳤는데, 인카금융서비스, 상반기 순익 330억원…전년 대비 20%↑ 이는 ‘24.4Q 부터 금융당국 행정지도로 보다 보수적으로 이익을 이연했기 때문이다.
이번 분기에도 신계약이 순증함에 따라 계약부채로 잡혀 미래 매출로 반영될 매출은 증가했다. 계약부채에는 인식상 왜곡이 없기 때문에 계약부채를 독립변수(X)로 하여 인식 기준이 변경된 매출(Y)이 얼마나 되어야 하는지 회귀분석을 사용하여 추정을 해보면, 매출=계약부채 규모*0.67+318.47억원임을 알 수 있다.
이를 바탕으로 과거 기준 매출을 추정해보면 위와 같은 추정치를 도출할 수 있다.
이러한 누적된 계약부채(미인식 수익)는 시차를 두고 결국 수익으로 인식되기 때문에 보다 확실하게 매출 성장을 예측할 수 있는 지표가 된다. 따라서 3분기 실적만 보면 수익성 증가 폭이 다소 완만해 보이지만, 장기적으로는 이연인식된 매출도 언젠가는 인식되기 때문에 성장의 기울기는 예전과 같이 유지될 수밖에 없다.
경제적 해자
기존 투자 아이디어
인카금융서비스는 전속 GA들이 모방할 수 없는 업무 프로세스로 사업을 운영하고 있다. 전속 GA들은 보험사들이 판매 채널 확보를 위해 소유한 설계사 조직이기 때문에, 다른 보험사들의 상품을 판매하기 어렵다. 또한, 다른 보험사들도 경쟁 보험사가 소유한 GA 채널에 의존도를 높이길 꺼려한다. 경쟁 독립 GA가 존재하긴 하지만 상장사로서 투명성과 독립성, 규모의 경제를 갖췄다는 점에서 경쟁사가 모방하거나 대체할 수 없는 업무 프로세스를 갖췄다고 할 수 있다.
두 번째는 규모의 경제이다. 일반적인 사업과 마찬가지로 GA 사업도 관리, 시스템 운영 측면에서 규모의 경제가 존재하나, 차이가 나는 지점은 규모가 커질수록 협상력 자체가 달라진다는 점이다. 규모가 커질수록 보험사 입장에서 매출의 큰 부분을 차지하기 때문에 단기 실적을 추구해야 하는 보험사 경영진 입장에서 무시할 수 없는 판매채널이 된다. 그리고 규모가 커질수록 협상력은 강화된다. 따라서 선순환이 더 강해진다.
세 번째는 전환비용이다. 소비자라고 할 수 있는 보험사는 인카금융서비스가 판매해주는 보험상품 매출을 포기하면, 그 정도의 매출을 다른 GA로부터 메꿀 수 없다. 그리고 그 매출은 다른 경쟁 보험사가 가져가게 된다. 따라서 보험사가 다른 GA로 보험 매출 채널을 전환하는 것이 사실상 불가능하며, 이는 강력한 전환비용의 근거가 된다.
네 번째는 브랜드가치이다. 인카금융서비스는 불완전판매율 통제, 수수료 투명성 확보 측면에서 회사를 신뢰할 수 있도록 운영해왔다. 이에 따라 보험상품 소비자들이 믿고 보험 계약을 체결할 수 있는 브랜드가치를 형성해왔으며, 보험사들도 대체할 수 없는 판매채널로 인카금융서비스를 인식하고 있다.
3분기 업데이트
설계사수 2만명 돌파
경제적 해자 측면에서는 결국 독립 GA 카테고리에서 얼마나 선도기업으로서 입지를 다졌는지가 중요하다.
설계사수 2만명 돌파는 어쩌면 실적보다도 더 중요한 소식이다. 3분기를 지난 10월 뉴스이긴 하지만 설계사수가 2만명을 돌파했다는 것은 그만큼 규모의 경제, 전환비용 측면에서 더 해자가 깊고 강력해짐을 의미한다. 또한, 향후 보험판매 전문회사 제도가 도입되었을 때 강력한 대면조직을 바탕으로 사업의 멀티플을 보다 더 높일 포텐셜이 강해졌음을 의미하기도 한다.
협상력
기존 투자 아이디어
앞서 설명한 이유로 국내 최대 GA인 인카금융서비스는 보험사에 대한 수수료 협상력이 높다. 다양한 보험사와 제휴해 상품을 판매하는 만큼, 원수사로부터 유리한 수수료 조건과 지원을 이끌어낼 수 있었고 이는 곧 동사의 수익성 및 비용 효율성으로 연결된다. 또한, 규모의 경제를 통해 타 GA 대비 효율적인 비용 관리가 가능했다.
3분기 변화
이번 분기 GPM은 18.47%로, 이연 매출이 급증하는 가운데서도 상당히 높은 이익률을 시현했음을 확인할 수 있다. ‘24.3Q 이후 매출 이연+비용 당기 인식으로 이익률이 낮아졌지만 ‘25.2Q GPM이 갑자기 높아진 것을 제외하면 GPM이 점진적으로 회복되며 정상화되고 있다는 것을 증명했다.
이번 분기 실적은 동사의 비용 통제력이 여전히 탄탄함을 보여준다. 급속한 외형 성장에도 불구하고 수수료 지급 등 영업비용을 효과적으로 관리하여, 매출 대비 이익 증가 속도가 빠르게 유지되고 있다.
순이익률이 ‘24.4Q 6.82%, ‘25.1Q 6.81%, ‘25.2Q 7.26%, ‘25.3Q 7.84%로 회복되고 있는데, 이는 매출이연에도 인카금융서비스가 여전히 높은 수수료 협상력을 바탕으로 성장하는 매출 대비 사업비 지출은 효율적으로 집행하고 있음을 시사한다. 판매관리비 비율이 안정적으로 유지되어, 매출 이연에도 이익 성장의 기울기가 유지되고 있다. 결론적으로 3분기에도 비용 효율성 측면에서 규모의 경제 효과와 수수료 협상력의 이점이 확인되었으며, 투자 아이디어의 전제였던 비용 통제력은 여전하다.
자본배치
기존 투자 아이디어
인카금융서비스가 ‘23년 초 메리츠금융그룹으로부터 조달한 500억원의 자금은 인카금융서비스의 성장을 가속화하는 데 활용되었지만, 높은 이자율로 인해 주주들에게 비판을 받았다.
’25년 주총에서 인카금융서비스는 3분기까지 해당 자금 상환을 완료할 계획으로 밝혔었다.
3분기 변화
차입금과 회사의 유보현금
전기 300억 가량 되었던 17% 메리츠 대출이 모두 상환되었는데,
전기 대출
다시 6% 이자율로 단기 차입금이 생겼다.
주주들은 더 이상 배당을 요구하지 말고 이 대출 먼저 상환할 것으로 요구하면 좋을 거 같다. 유동성 확보, 성장을 위한 투자 측면에서 이 회사는 갈 길이 먼 회사이다.
회사 측은 조달한 자금을 인공지능 플랫폼 투자, 자회사 설립 및 운영 등에 사용하고 있다.
이는 미래 성장성을 유지하기 위해 필요한 투자로 보여지며, 그 과정에서 이자율을 낮출 수 있었기 때문에 바람직한 자본배치가 이뤄진 것이라고 판단된다.
그리고 단기적 관점에서 투자하는 주주들이 더 이상 회사의 현금을 배당같은 무의미한 용처에 사용하길 종용하는 일이 없었으면 좋겠다. (물론 6% 정도면 합리적인 수준이긴 하지만, 그렇더라도 개인적으로 돈을 빌릴 수 있는 이자율에 비해 훨씬 높은 수준이며, 배당을 하는 과정에서 부과되는 세금도 고려해야 한다)
이는 단기적으로는 비용을 발생시키지만, 장기적으로 봤을 때 설계사들이 보다 주주가치에 부합하는 방식으로 더 열심히 일할 유인을 제공하는 훌륭한 자본배치이다.
나는 이렇게 주주에게도 이득이 되고 설계사에게도 유익한 좋은 사용처에 회사가 보유한 현금이 활용될 수 있도록 동료 주주들이 보다 장기적 안목을 갖추고 차분히 인내해주길 바랄 뿐이다.
밸류에이션
지난 실적발표, 또는 3분기 말 대비 밸류에이션은 크게 변하지 않았지만, 매출은 ‘24.4Q 이후 QoQ 증가 추세를 이어가고 있으며, 계약부채 규모로부터 추정되는 실제 매출을 생각해보면 성장세가 단 한번도 꺾인 적 없다. 이를 간접적으로 입증하는 부분이 바로 꾸준한 설계사수 성장세이다.
나는 개인적으로 다음과 같은 이유로 행동주의 펀드, 특히 얼라인의 ‘전략’을 좋아하지 않는다. 1. 시간을 정하고 투자하며, 적극적으로 언론 플레이를 한다는 점 2. 다른 경쟁 기업을 비교대상으로 놓고 엄연히 밸류에이션이 다른 이유가 있음에도 이를 무시하고 자기 유리한대로 해석한다는 점 3. 전문성도 없는 분야임에도 경영에 적극적으로 간섭한다는 점 심지어 버핏님도 스트라이크존에 들어오지 않는 기업에는 스윙을 하지 않는다고 하셨는데, 경영권만 쥐면 짠 하고 스트라이크존에 들어오지 않는 기업이 경쟁력 있는 기업으로 탈바꿈할 것이라고 생각하는 것은 과도한 오만이다. (왜 얼라인은 항상 내가 투자하는 기업의 경쟁사에 투자하는 걸까?)
얼라인은 인카금융서비스가 고평가라고 주장하겠지만, 이는 규모의 경제에서 오는 협상력의 차이를 무시한 결과이다. 인카금융서비스의 TTM OPM은 9.49%로 10%에 근접하고 있는 반면 에이플러스에셋은 4.2%에 불과하다.
그리고 이는 산업내의 구조적 차이에서 기인한다. 즉, 행동주의 펀드가 아무리 경영을 개선하더라도 브랜드가치나 선도적 지위, 수수료 협상에 있어서 협상력을 역전시킬 수 없다. 오히려 손을 대면 댈수록 역효과만 날 것이다.
어찌됐든 인카금융서비스로서는 에이플러스에셋의 주가가 올라가면 비교 대상 기업의 멀티플이 올라가는 것이기 때문에 주가에 긍정적 영향이 있을 거라고 생각한다. 에이플러스에셋의 경우 ‘24.3Q에 대규모 순익 적자를 시현한 적 있기 때문에 순익 기준으로 비교하는 것은 부적절하다고 생각되어 POR 기준으로 양사를 비교해본다면, 인카금융서비스는 TTM POR 7.65, 에이플러스에셋은 6.71이다.
절대적 기준으로 본다면 충분히 낮은 수준이며, 인카금융서비스의 규모의 경제, 협상력 및 보험사 매출에서 차지하는 비용, 계약부채로 인해 과소인식되고 있는 상황 등을 감안하면 결코 고평가가 아닌 주가라고 생각된다.
가치투자 커뮤니티를 성장시켜나가고 있습니다. 운영 계획과 방향성을 한 번 읽어보시고, 텔레그램과 유튜브 채널을 통해 소통하고 있으니 공감이 가신다면 참여해주세요! 쌍방향 소통을 원하는 분들은 카카오톡 채널로 와 주시면 좋을 거 같습니다. 자료실을 통해 리포트, 뉴스도 공유하고 있으니 참고하시면 도움이 될 거 같습니다.