
25.11월 한중엔시에스를 검토하고 3분기 투자 아이디어 대회에서 시상했었다.
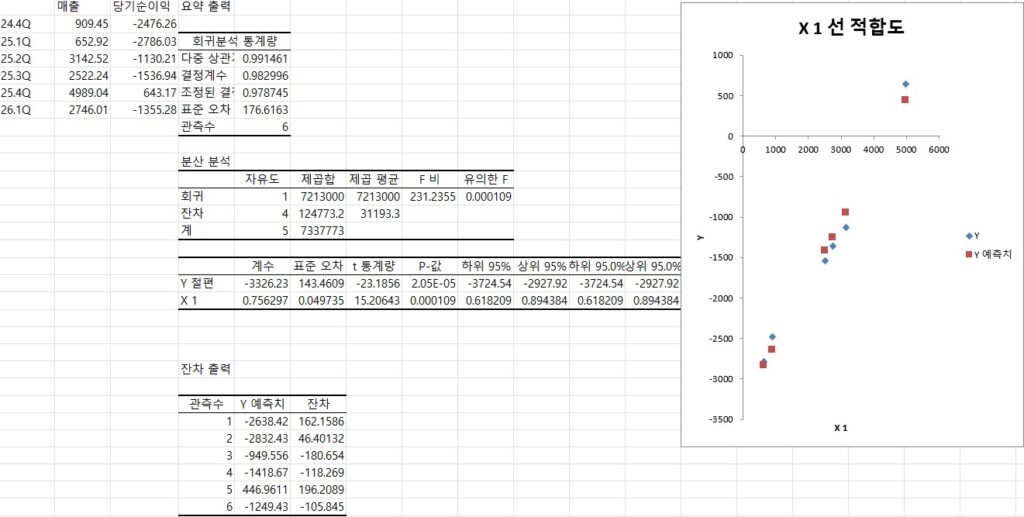
당시 25년 예상 순이익은 88억, 26년 예상 순이익은 196억원으로 fPER 47.5였는데,
25년 실제 순이익이 40억원이 나오고, 26.1Q 순이익은 14억원으로, 26년 예상 순이익이 60억원으로 조정되어 예상 대비 저조했다.
다만, 이제 27년 미국 공장 준공과 매출 급증이라는 확률높은 미래가 정말 코앞으로 다가왔다.
그리고 미국의 수입통계는 ESS 산업 지평이 현지 생산 위주로 재편되고 있음을 시사하고 있다.
얼마나 성장할지 감도 안 오는 미래에도 비합리적인 수준까지 하락해서 안전마진이 충분하다.
이에 대해 나누고, LTO 멤버들의 검증을 받아보고 싶다.
한중엔시에스 매출 성장 내러티브
BM의 이해
한중엔시에스는 저수익 자동차 산업에서 ESS 산업으로 BM 구조를 성공적으로 전환했다.
21년 사업보고서는 주업종을 기존 자동차 부품 제조업에서 ESS 제조업으로 변경했다.
이후 22년 삼성SDI SSP Partner(전략적 우선협력사) 선정 → 23년 삼성SDI E5S 수냉식 초도 양산공급 개시 → 25년 미국 신규 ESS 생산법인 설립이 이어졌다.
ESS는 “배터리 온도를 유지하고, 누수·결로를 막고, 열을 빨리 식혀야” 오래가고 사고가 적다.
한중엔시에스는 단순 부품이 아니라 배터리 모듈 열관리와 안전을 위한 ‘솔루션’을 제공한다.
Cooling Plate는 셀 바로 아래에서 열을 빼내고,
Manifold와 Main Pipe는 냉각수 흐름을 균일하게 분배하며,
Chiller와 HVAC는 냉각·가열·제습을 통해 결로를 막고,
Spray Pipe는 화재에 대응한다.
그리고 한중엔시에스는 세계에서 가장 앞서 수냉식 ESS 냉각 솔루션을 개발하였다.
물은 비열이 더 높아 배터리 온도를 더 정밀하게 제어하여 화재 위험을 줄일 수 있다.
특히 수냉식 냉각을 위한 일부 부품을 개발한 것이 아니라 ‘더 높은 냉각 성능을 구현할 수 있는 부품들과 구조의 조합인 수냉식 ESS 시스템’을 구현했다는 것이 강점이다.
(아래 기사에서도 셀을 제외한 SBB 부품의 70%를 한중엔시에스가 담당한다고 명시)

수냉식에서는 공냉식 대비 냉각수를 순환시킬 수 있는 Cooling Plate 구조와 배터리를 담는 셀 및 냉각을 담당하는 Chiller가 바뀌고,
직접 냉각을 담당했던 HVAC가 수냉식에서는 결로 방지 역할로 변경되었다.
또한, 냉각수를 배분하는 Manifold 구조가 추가되고, 냉각수 흐름을 관리하는 배관, 커플러, 누수감지 부품이 중요해졌다.
이렇게 하나의 부품이 아닌 전체 시스템을 변경해야 하기 때문에 구조가 단순했던 공냉식 대비 기술적 난이도가 높고, 검증에 시간과 비용이 많이 소요된다는 점에서 해자가 깊어졌다.
주요 글로벌 ESS 업체들은 내재화, 부품별 별도 외주 생산 등을 통해 수냉식 냉각 시스템을 구현하고 있으나, 통합성, 신뢰성, 투명성 측면에서 한중엔시에스의 시스템적 통합 접근을 통한 SDI 의 수냉식 ESS가 최종수요자에 대한 하나의 셀링포인트가 될 수 있다.

독립 열 관리 업체 중 가장 명확한 원스톱 업체는 Envicool이 있다.
Envicool은 공식적으로 자사 제품을 “에너지저장 원스톱 액체냉각 솔루션”(“Energy storage one-stop liquid cooling solution”)이라고 명시하고,
열해석·솔루션 설계·시스템 통합·냉각원 선정뿐 아니라 냉각플레이트, 배관, 커넥터·실링, 냉각원, 냉각수, 1차·2차·3차 루프와 퀵디스커넥트까지 “범용 열관리 플랫폼”으로서 한중엔시에스보다 넓은 제품군을 확보했다.
다만 고객사별 공급관계는 별도의 NDA로 공개하지 않는다.
물론 Envicool이 CATL 계열 ESS에 냉각시스템을 공급한다는 설명은 기사에서 자주 등장하나, CATL EnerOne·EnerC·TENER의 공식 BOM이나 Envicool 공시에서 제품별 공급 관계는 명시적으로 발표된 바 없다.
여기에 비하면 한중엔시에스는 배터리팩 모듈, Cooling Plate, Manifold, Chiller, HVAC, Main Pipe와 화재 대응용 Spray Pipe까지 포함하여 ESS 배터리 모듈과 열관리·소화 영역을 함께 공급하는 점이 차별화된다.
즉, 한중엔시에스는 범용 열관리 플랫폼보다 삼성SDI SBB에 최적화된 원스톱 모듈 공급사로, 삼성SDI 플랫폼에서 공동개발·승인·양산하여 잠김효과가 강하나 고객 다변화가 제한된다.
반면 Envicool은 특정 배터리사에 대한 잠김효과는 낮지만 제품군과 고객 확장성은 더 넓다.
자동차 부품 BM은 배터리가 안정적으로 작동하게 만드는 EV Battery Module과
차가 덜 뜨겁고, 공조 효율이 좋아지게 하는 EV 공조장치 모듈로 구성되어 있다.
EV Battery Module은 충격 보호, 절연, 전류 흐름 제어, 셀 적층 구조를 담당한다.
EV 공조장치 쪽의 Cooling Fan Module은 열교환기 냉각을, Active Air Flap은 차량 내부 유입 공기 제어를 통해 공조 효율과 배터리 열관리에 기여한다.
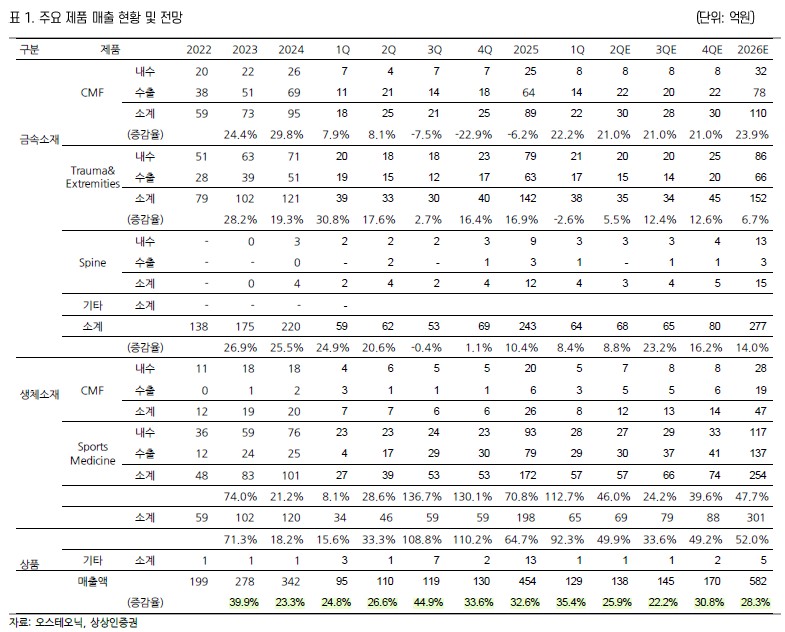
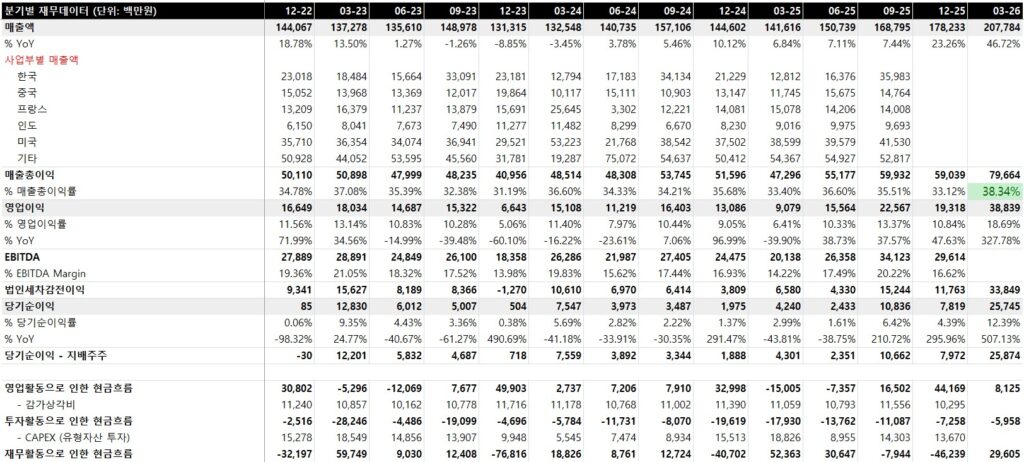
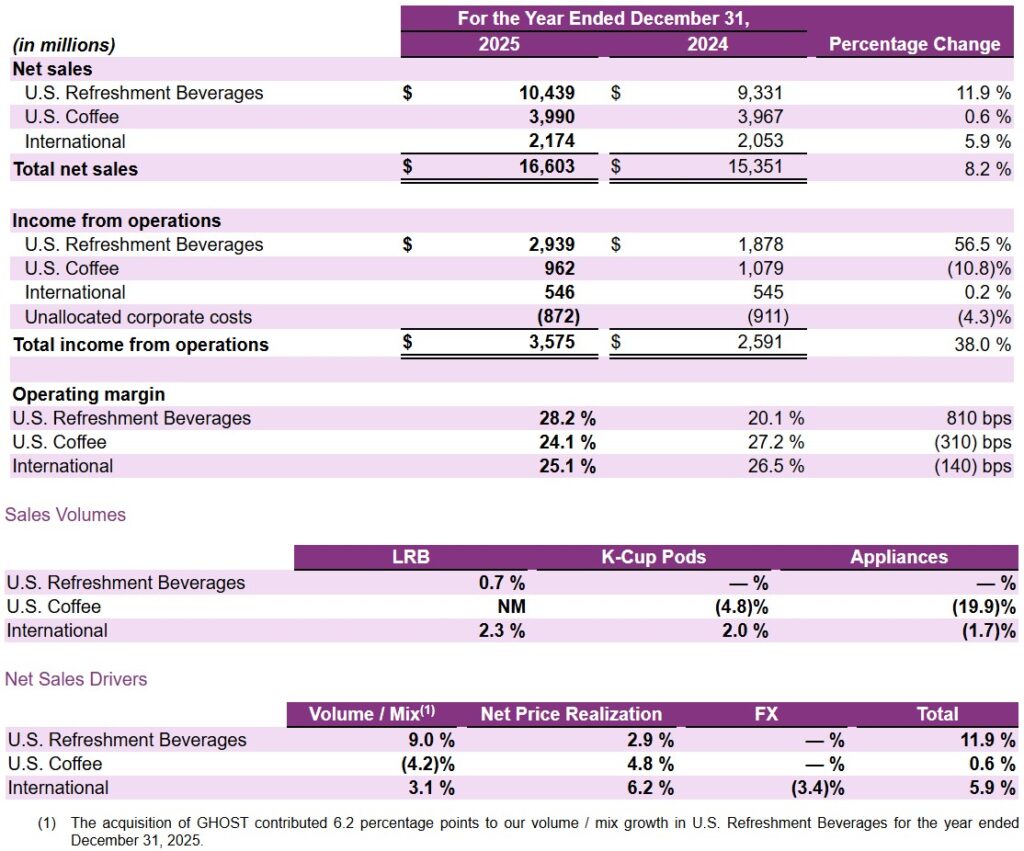
부문별 매출
연결기준 제품별 매출에서 ESS 산업으로의 구조전환은 숫자로 드러난다.
ESS 매출 비중은 23년 40.8% → 24년 60.5% → 25년 81.6% → 26.1Q 97.0%로 증가했다.
반대로 자동차부품과 기타 매출은 빠르게 축소됐다.
매출 비중, 성장률에서 볼 수 있듯이 회사는 ESS 중심으로 자원을 재배치하고 있다.

사업보고서는 고객사명을 공개하지는 않으나, 매출 비중을 볼 때 삼성SDI가 ESS 고객1이다.

SDI향 매출은 25년 기준 1,012.2억원으로 총매출의 57.8%, ESS 매출의 70.8%를 차지하여,
대기업향 매출의 안정성과 단일 고객 의존 리스크가 병존한다.
다만 26.1Q에는 SDI향 매출이 207.73억원으로 총매출의 38.0%, ESS 매출의 39.1%인데,
고객2향 매출은 189.75로 총매출의 34.7%, ESS 매출의 35.7%이며,
기타 매출도 133.32억원으로 총매출의 24.4%, ESS 매출의 25.1%였다.
(아래 기사에 따르면 같은 최종수요자를 향하는 다른 거래 구조일 가능성도 있어 확인 필요)
고객 분산이 이뤄질 수 있다면 SDI 의존도가 완화되고 협상력이 강화될 수 있다.

성장 내러티브 확인을 위해 매출을 지리적으로 구분할 필요가 있다.
수출 비중은 최종 수요자가 아닌 통관 여부를 기준으로 구분되기 때문에 큰 의미는 없다.
다만, 26.1Q 수출 463.24억원, 내수 84.08억원으로 수출 비중이 급격히 확대되었으며,
ESS 모듈 수출이 459.68억원으로 분기 매출의 80% 이상을 차지했다.
| 구분 | 2023 | 2024 | 2025 | 2026 1Q |
|---|---|---|---|---|
| 수출 | 532.17 | 897.12 | 1,060.50 | 463.24 |
| 내수 | 681.44 | 874.31 | 692.15 | 84.08 |
| 총매출 | 1,213.61 | 1,771.43 | 1,752.65 | 547.32 |
지리적으로 매출을 세분하지는 않지만 주요 고객사 삼성 SDI의 주요 ESS 프로젝트는
미국의 경우 NextEra Energy향 약 4,374억원 규모 프로젝트, Fluence향 공급, 미국 에너지 인프라 기업향 2조원 이상 계약, 미국 에너지 기업향 1.5조원 계약이 체결되었다.
반면 유럽에서 구체적으로 확인된 최근 신규 고객은 독일 Tesvolt(계약금액 미공개),
국내에서는 1·2차 ESS 중앙계약시장 관련 계약이 각각 약 7,600억원과 3,600억원 규모였다.
최근 IBK 리포트는 삼성SDI의 26년말 ESS CAPA를 울산 10GWh, 중국 3GWh, 북미 29GWh, 총 42GWh로 추정하고, 한중엔시에스가 중국외에서 100% 공급할 것으로 예상했다.

한편 한중엔시에스는 중국 자동차 부품 공장도 ESS 공장으로 전환하였는데, 다만 매출은 26.1Q 기준 Jiangsu Han Jung 18.6억원, Changshu Hanjung 5.6억원으로 아직 미미하다.

따라서 삼성SDI향 매출은 주로 미국 시장 성장 내러티브를 따라갈 것으로 추정된다.
그리고 이러한 추세는 미국 생산공장 완공에 따라 더 심화될 것으로 보인다.
성장 내러티브
메가트렌드 : 미국 ESS 시장 성장과 삼성SDI 점유율
BNEF(Bloomberg New Energy Finance)는 최근 ESS 시장 전망을 급격히 상향조정하였다.
글로벌 시장은 성장전망을 20%에서 50%로, 미·중 시장은 기존 대비 전망치를 35% 상향했다.미국 시장은 AI 데이터센터 성장에 따른 전력망 부하 흡수 수요 증가와 세액공제 수혜,
중국 시장은 재생에너지 간헐성 보완 필요성이 근거였다.

다만, ESS 시장 전체가 한중엔시에스의 TAM이 되지는 못하며, 현재 매출 구조상 삼성SDI의 ESS 성과에 의존성이 강하므로, 삼성 SDI의 매출이 얼마나 성장할 수 있을지를 평가해야 한다.
현재 중국 ESS 기업들의 가격경쟁력이 높아 중국에서는 중국 기업들의 점유율이 절대적이며,
중국산 의존도를 축소시키려는 미국 정책이 존재하는 미국 시장이 SDI의 타겟 시장이 된다.
미국 정부는 시장접근 금지보다 비중국산 가격경쟁력을 높여 유인을 제공하는 시장 메커니즘을 활용하여 ESS 공급망에서 중국산을 축소하려 한다.
USTR의 301조 관세로 비차량용 리튬이온 배터리에 26년부터 25% 관세가 적용된다.

IRA상 세액공제(Investment Tax Credit)와 국내 생산 보너스(Domestic Content Bonus)를 받기 위해 기업들은 중국산 비중을 낮추고 미국 현지 생산을 늘려야 한다.
기준 비율은 26년 45%에서 30년에는 25%까지 낮아진다.
이는 최근 ESS 디벨로퍼들이 한국 배터리 업체와 계약을 체결한 배경이 되었으며,
앞으로는 계약이 더 늘어날 것으로 전망된다.

다만, 중국산이 세액공제, 국내 생산 보너스에서 제외되고도 경제성을 확보할 수 있으며,
IRA로 인해 점유율을 모두 국내 사업자들이 가져갈 것이라고 보는 추정은 과도한 낙관이다.
그래도 26년 55% 비중이 적용되며 ESS 배터리(HS Code 8507-60-0020) 중국산 수입 비중이 25년 63.5%에서 26.5월 누적 34.1%까지 축소된 것은 한국 ESS 밸류체인에 매우 긍정적이다.
또한 수입 증감률이 전년 동기대비 25년 -11%, 26.5월 누적 -86.2%인 것은 미국내 생산 비중이 확대되고 있는 것으로 볼 수 있겠다.
여기에 SDI가 현지생산요건까지 갖추게 되면 더 가격경쟁력이 높아지고, 점유율을 확대할 수 있는 근거가 된다.

따라서 중국산이 배제되고 침투율이 높아지며, 미국 현지 생산이 확대되는 SDI의 핵심 파트너사로서 한중엔시에스의 성장은 가능성이 높은 미래다.
또한, 현재 신재생에너지에 비판적인 트럼프 행정부가 지지를 잃고 있음을 기억해야 한다.
IRA는 민주당 정부에서 입법되었으며, 28년 정권이 교체된다면 더 적극적으로 신재생, ESS 드라이브가 걸릴 수밖에 없다.
이 또한 높은 확률의 옵션가치로 생각된다.
회사의 성장 전략
회사는 사업보고서를 통해 다음과 같은 내러티브를 제시한다.
1) 큐브젠(중소형 ESS) 레퍼런스를 통해 라디에이터, 배관, 펌프, 냉각수 흐름, 온도센서, 화재 대응, 제어 소프트웨어 등을 시스템 단위로 다뤄 커플러, 누수 감지, 매니폴드, 칠러 운영시스템, 결로 방지 로직을 검증, 유체를 어떻게 막고, 감지하고, 제어하는지에 대한 경험을 축적했다.
검증·축적한 ESS 안정성·냉각·제어·화재대응 노하우를 대용량 ESS(ex. 테슬라 Megapack)와 건물용 ESS 부품으로 확장하고 있다.
대용량 ESS는 열밀도와 모듈 수가 커지기 때문에 냉각 균일성, 유량 분배의 편차 관리, 한 지점 누수의 전체 시스템 리스크 차단, 장시간 운전 신뢰성, 현장 유지보수성이 더 중요해지며,
건물용 ESS는 규모는 상대적으로 작아도 설치 공간 제약, 저소음, 결로 관리, 화재 안전성, 건물 설비와의 연동이 더 예민하다.
2) 회사는 ESS 쿨링플레이트 기술을 기반으로 EV 배터리용 쿨링플레이트를 개발 중이다.
EV 쿨링 플레이트는 단순 금속판처럼 보여도 냉각수 유로 설계, 누설 방지, 접합 품질, 압력 손실, 온도 균일도, 내식성, 장기 신뢰성이 필요하여 단순 프레스부품보다는 진입장벽이 높다.
배터리 팩 양산용이면 품질요건과 장기 보증 부담으로 아무 업체나 쉽게 들어가기 어렵다.
다만, 자동차 부품 시장은 양산시 고객의 원가 인하 압박과 장기 공급 단가 하락이 강하다.
게다가 최근 배터리 업계는 EV 수요 둔화 때문에 EV 라인을 ESS로 전환하는 흐름이 뚜렷하다.
삼성 SDI는 EV 수요 부진이 26년 상반기까지 이어질 수 있다고 언급했고,
미국 공장 내 일부 라인을 ESS용으로 전환하고 있다.
LG에너지솔루션도 미국 내 EV 라인의 일부를 ESS로 돌리는 방향을 제시했다.
따라서 한중엔시에스가 EV 쿨링 플레이트를 새로운 성장 내러티브로 제시한다면,
그 이유는 사업이 고수익 메인축이라기보다 회사가 이미 갖고 있는 유체·열관리 기술을 재활용할 수 있는 옵션 가치가 있는 인접 사업이기 떄문일 가능성이 크다.
실제로도 EV 매출 비중은 24년 39.5%, 25년 18.5% 대비 26.1Q 3.1%로 급감하는 추이이다.
3) 2025년 미국 신규 ESS 생산법인을 설립했고, 중국 법인도 ESS 생산라인 전환을 진행했다.
이는 전체적으로 제품 믹스 변경을 통해 수익성을 개선하려는 노력의 일환이다.
미국 공장은 삼성 SDI 미국 공장 30Gwh에 대응하기 위해 설립되고 있어 현재 대응중인 국내 생산능력 8Gwh에서 2,000억원 가량의 매출이 나오고 있는 것을 감안하면 매출 전망치는 이르면 27년, 늦으면 28년 온기 반영시 9,500억원에 달하는 것으로 보인다.

현재 비중국 비율 기준 적용으로도 중국 수입 비중이 급감하고 있는데.
현지 생산 보조금까지 수령하게 되면 SDI 현지 생산 물량이 ‘완판’될 가능성은 매우 높으며,
제품 개발단계에서 맞춤형으로 기술을 공동개발한 한중엔시에스 외의 다른 기업이 시스템을 제공할 가능성은 극히 낮다는 점에서 27년, 늦으면 28년 9,500억원의 매출이 나올 것이란 점은 매우 높은 확률의 추정이다.
4) 회사는 지속적인 R&D와 특허·원가경쟁력 확보를 통한 업종 선도 지위를 목표로 제시한다.
ESS 냉각시스템 관련 특허는 이중 차단 커플러, 누수 감지 방법·장치, 수냉식 냉각수 연결 장치, 양방향 차단 구조 냉각 매니폴드, ESS 배터리용 칠러 운영시스템, COOLSPIN, 칠러 등이 있다.
이중 차단 커플러는 냉각수 호스를 연결하거나 분리할 때 양쪽에서 동시에 밸브가 닫혀 냉각수가 새지 않게 만드는 연결부품이다.
누수 감지 방법·장치는 냉각 시스템에서 물이 새면 초기에 알아채는 센서/진단 기술이다.
수냉식 냉각수 연결 장치는 배터리 팩과 냉각 배관을 쉽고 안전하게 연결하는 기술이다.
양방향 차단 구조 냉각 매니폴드는 냉각수를 여러 갈래로 나누어 보내는 배관 본체인데, 이상이 생기면 특정 구간을 양쪽에서 차단할 수 있게 만든 구조다.
ESS 배터리용 칠러 운영시스템은 냉각기 자체를 단순히 켜고 끄는 것이 아니라, 배터리 상태와 주변 환경에 따라 어떻게 운전할지 결정하는 제어 로직이다.
COOLSPIN은 냉각 제어 알고리즘, 운영 플랫폼, 혹은 열관리 시스템이다.
칠러는 배터리용 차가운 냉각수를 만들어 배터리를 식히는 장치다.
냉각판(배터리에서 열을 빼내는 판)만 만드는 회사라면 특허 제목이 주로 “판 내부 유로 구조”, “열전달 효율”, “접합 방식”에 집중된다.
그런데 한중엔시에스는 실제 ESS에서 필요한 더 넓은 범위의 기술을 개발하고 있다.
냉각수를 어디서 연결할지, 여러 모듈에 어떻게 나눌지, 새면 어떻게 감지할지, 문제가 생기면 어느 구간을 차단할지, 외기 온도와 습도에 따라 결로를 어떻게 막을지, 칠러를 얼마나 돌릴지, 이상이 생기면 어떻게 정지하고 알람을 띄울지가 다 필요하다.
회사 특허 포트폴리오에는 커플러, 매니폴드, 누수 감지, 칠러 운영시스템이 함께 들어 있다.
이는 배터리 열관리를 부품 단품이 아니라 유체 시스템의 전체 흐름으로 보고 있다는 의미다.
특히 누수 감지와 냉각 매니폴드 양방향 차단 구조는 대형 ESS에서 매우 중요하다.
미국 ESS 시장은 화재와 안전에 대한 지역사회 민감도가 높아 프로젝트 반대 이슈가 반복된다.
이런 시장에서는 “잘 식히는 것”만큼이나 “샌 적이 없고, 샜을 때 빨리 찾고, 국소 고장을 확산시키지 않는 것”이 경쟁력이다.
한중엔시에스의 특허 포트폴리오는 이러한 미국 시장의 수요 방향성과 일치한다.
경쟁사 대비 경쟁력
한중엔시에스는 제품의 강점을 세 가지로 제시한다.
우선, Cooling Plate 하나가 아니라 Manifold, Chiller, HVAC, Main Pipe, Spray Pipe까지 이어지는 시스템형 밸류체인을 가져 제품 범위가 넓다.
둘째, 결로 방지, 누수 감지, 자동냉매 환기, 화재 진화 노즐까지 포함하여 안전 기능이 강하다.
셋째, 25년 미국 인디애나 생산법인 설립·27.1Q 생산 공장 준공을 통해 IRA 등 법령상 보조금 수령이 가능한 조건을 갖춰나가고 있다.

경쟁사와 비교해보면, Boyd는 배터리 보호·열관리·열폭주 방호까지 아우르는 광범위한 포트폴리오를 제시하고 있고,
Modine은 배터리 에너지저장장치용 열관리 시스템을 표준화된 패키지와 정밀 제어 중심으로 제시한다.
즉, 글로벌 선두 경쟁사는 이미 “단품”이 아니라 “플랫폼형 열관리 솔루션”을 판다.
한중엔시에스도 공개 제품 구조만 보면 동일한 방향성을 추구하고 있다.
중국 ENVICOOL과의 비교에서는 한중엔시에스가 보다 배터리 팩·ESS에 최적화된 냉각 시스템을 갖추고 있는 것으로 보인다.
다만 범용성에 있어서는 ENVICOOL이 더 우위에 있다.

로이터는 26.3월 구글이 AI 데이터센터용 액체 냉각 시스템 조달을 위해 중국의 Envicool과 접촉했다고 보도하여, 범용적 냉각 시스템 공급사로서 Envicool의 위상을 확인할 수 있다.

이 기사를 통해 Envicool이 액체 냉각 분야에서 상당한 기술력을 검증받았음은 확인할 수 있다.
다만, ESS 수냉식 냉각에 있어서는 명시적인 대기업과의 협업 및 상업화 레퍼런스의 존재로 한중엔시에스의 협업 가능성이 더 높다고 생각된다.
경제적 해자
한중엔시에스의 해자는 강한 범용 브랜드 해자라기보다, 삼성SDI 공급망 안에서 형성된 안전성 검증형·관계형 해자다.
삼성SDI는 공급업체 선정시 설계 복잡도, 제조공정 복잡도, 공급 중단 영향, 품질·성능, 특허·신기술, 기존 공급물과의 호환성, 과거 납품 실적을 공식 기준으로 반영하고,
원칙적으로 기존 공급자와의 수의계약을 유지할 수 있으며,
대체 공급 시 비호환이 발생하면 기존 공급자를 유지할 수 있도록 규정하고 있다.
또한 SSP와 G-SRM, 교육, 혁신과제, 금융지원까지 결합한 공급망 관리 체계를 운영한다.
이는 수냉식 ESS 부품처럼 안전성과 검증 이력이 중요한 품목에서 전형적인 잠김효과를 만든다.
무형자산
레퍼런스와 신뢰성
삼성SDI는 배터리와 ESS에서 안전성과 품질을 중시한다.
삼성SDI 배터리 사업 홈페이지는 전력/상업용 ESS가 전력망 안정화 역할을 하며 자사 배터리가 “안전성과 경제성”을 바탕으로 성능을 제공한다고 설명한다.
또한 배터리 안전정보 페이지에서는 리튬이온 배터리가 오·남용 시 화재·폭발 등 심각한 사고를 유발할 수 있으며, 삼성SDI 배터리는 개인에게 판매하지 않고 배터리 팩 제조사 또는 시스템 통합사업자에게만 판매한다고 명시한다.
이는 ESS 밸류체인에서 “검증된 B2B 공급망”이 필수임을 의미한다.
삼성SDI의 2026 지속가능경영보고서는 “고객 안전 및 제품 책임 강화”를 주요 주제로 두고,
제품 안전 및 책임 강화가 고객 신뢰도에 미치는 영향을 명시한다.
같은 보고서는 제품 안전과 품질이 관리자 성과평가 지표에 반영된다고 밝히고,
ESS 분야에서는 대규모 화재 안전성 시험인 LSFT를 통해 화재 안전성을 입증했으며,
LFP 기반 SBB 2.0이 구조적 안정성으로 ESS 운영 과정에서 화재 및 열적 위험을 낮춘다고 설명하며, 삼성SDI ESS 공급망의 핵심 가치가 안전성·신뢰성·화재 대응성임을 보여준다.
삼성SDI는 협력사를 단순 구매처로 보지 않고 파트너사 협의체인 SSP를 운영중으로,
25년 제11기 SSP를 총 56개 파트너사로 구성, 84개 파트너사에 상생협력펀드 1,925억원 지원, 85개 파트너사 2,305명에게 교육을 제공, 16개사 18개 과제로 혁신지원 활동을 확대했다.
한중엔시에스의 가장 강한 무형자산은 소비자 브랜드라기보다 “삼성SDI가 써 본 공급자”라는 레퍼런스다.
ESS는 고장 나면 성능 저하로 끝나는 분야가 아니라 화재, 정지, 규제, 보험 리스크가 발생한다.
따라서 삼성SDI 같은 배터리 OEM이 실제로 쓰는 부품 공급자라는 사실은 다른 신규 고객에게도 강한 신뢰 신호가 된다.
특히 미국처럼 프로젝트 금융, 보험, 화재안전, 통합운영 리스크가 중요한 시장에서는 레퍼런스의 가치가 더 크다.
이 점에서 한중엔시에스의 해자는 “브랜드 해자”라기보다 “검증 이력 해자”다.
삼성SDI가 공급망 내 제품 안전을 중대 토픽으로 다루고, ESS 제품의 화재 안전성 시험까지 전면에 내세우는 상황에서, 열관리 부품 공급자 역시 단순 조립업체가 아니라 안전 설계와 장기 운전 신뢰성을 입증해야 한다.
이는 신규 진입자에게 높은 문턱이다.
특허
앞서 회사가 제시하는 성장 내러티브에서 살펴본대로,
ESS 냉각 관련 이중 차단 커플러, 누수 감지 방법·장치, 수냉식 냉각수 연결 장치, 양방향 차단 구조 냉각 매니폴드, ESS 배터리용 칠러 운영시스템, COOLSPIN, 칠러 등 특허를 보유한다.
이러한 특허는 한중엔시에스가 제공하는 상품을 부품 단품이 아니라 시스템 전체로 보고 기술을 개발해나가고 있음을 의미한다.
또한, 화재와 안전에 대한 지역사회 민감도가 높은 미국 시장에서 “샌 적이 없고, 샜을 때 빨리 찾고, 국소 고장을 확산시키지 않는 방향”으로 개발된 한중엔시에스의 특허 포트폴리오는 다른 후발주자가 따라잡기 힘든 해자의 근거가 된다.
이러한 특허는 삼성SDI 조달 기준상 “특허·신기술”, “특수 품질·성능”, “기존 공급물과 비호환 시 기존 공급자 유지” 조항과 결합되어 해자를 강화할 수 있으며,
이 경우 특허는 소송용 방패보다도 고객에 대한 잠김효과를 강화하는 설계 자산에 가깝다.
잠김효과와 전환비용
단일 고객에 집중하여 상호 제품 설계 호환성과 품질 검증 체계를 자리잡는데 시간과 비용이 투입되기 때문에 삼성SDI 입장에서도 신규 기업과 계약을 체결하기 곤란하다.

삼성SDI의 공식 계약 가이드라인은 잠김효과를 분명하게 보여준다.
삼성SDI는 가이드라인을 통해 계약방식 결정 시 공급 중단 영향, 설계 복잡도, 제조공정 복잡도, 구매 이력, 시장 공급능력, 공급자 간 경쟁도, 진입장벽, 공급망 복잡성을 고려한다고 밝힌다.
또한 원칙적으로 기존 공급자와의 수의계약을 유지할 수 있으며,
다른 공급자가 공급할 경우 기존 물품과 호환되지 않는 경우,
특정 특허·신기술이 적용되는 경우, 특정 품질·성능·효율 등으로 대체 경쟁이 사실상 불가능한 경우 수의계약이 가능하다.
한중엔시에스의 경우 기술을 공동개발하여 대체 경쟁이 사실상 불가능한 경우에 해당되어 단독 수의계약으로 수냉식 냉각 시스템을 공급하고 있다.
이는 고객사의 업무와 대체불가하고 긴밀한 관련성을 맺어 생겨난 B2B 잠김효과다.
열관리 부품은 셀·모듈·랙·컨테이너·칠러·배관·BMS/EMS와 연결되기 때문에,
공급자 교체는 단순 BOM 변경이 아니라 재검증, 호환성 재설계, 품질 재승인이 필요해진다.
삼성SDI가 공식 문서에서 “기존 공급자 유지”, “비호환성”, “특허·특수 성능·실적”, “적격업체 10개 이하” 같은 문구를 조달 기준에 넣은 것은, 적어도 전략 품목에 대해서는 일반 부품처럼 가격입찰만으로 바꾸지 않는다, 또는 바꿀 수 없다는 것을 의미한다.
규모의 경제
Reuters에 따르면 Envicool은 중국의 대표적 액체냉각 제조사 중 하나로 평가되며, 2025년 첫 9개월 매출이 40% 급증했고 시가총액은 980억위안(21.7조원) 수준이었다.

즉, Envicool이 냉각 산업에서 단순 저가 조달처가 아닌 대형 고객에 대한 범용 냉각 솔루션을 소화하는 수준에 이르고 있음을 의미한다.
이에 비하면 한중엔시에스는 강한 비용우위 해자보다 조건부 기술·검증 해자로 보인다.
따라서 투자 판단의 핵심은 매출 규모·성장이 아니라, 범용 제품을 생산하는 기업이 완전히 장악하지 못한 니치마켓, 미국 ESS 시장에서 성장해가면서 매출총이익률이 유지되는 질 좋은 성장이 지속되는지에 집중되어야 한다.
한중엔시에스의 협상력
삼성SDI와 상호의존적인 관계를 구축하고는 있지만, 기업의 규모와 한중엔시에스 매출의 의존성을 고려할 때 협상력이 다소 약한 것은 사실이다.
이러한 관계는 앞으로 삼성 SDI 레퍼런스를 바탕으로 다른 기업 수냉식 냉각 시스템 수주를 받게 되면 더 평등하게 개선될 수 있을 것으로 보인다.

GPM 추이는 최근 4분기 연속 개선되는 흐름을 보이며 26.1분기에는 20%대를 넘어섰다.
이러한 추세는 협상력이 낮은 자동차 부품 산업에서 높은 ESS 냉각 시스템 산업으로 BM 믹스를 개선해나간 것이 강하게 작용한 것으로 보인다.
가격 협상력(P)
제품별 공시가격이나 실제 계약 ASP는 공개되어 있지 않아 직접 검증은 불가하다.
하지만 삼성SDI의 계약 가이드라인은 단가를 정할 때 수량, 품질, 규격, 납기, 결제방식, 원재료 가격, 노무비, 시장가격 추세를 반영해 합리적으로 협의해야 한다고 밝히며,
계약 기간 중 원재료·환율 등으로 초기 단가 변경 사유가 발생하면 30일내 재결정하도록 한다.
한중엔시에스가 Envicool 처럼 범용 시스템을 판매하지는 않아 가격 협상 우위는 아니지만,
삼성SDI 입장에서도 한중엔시에스가 SBB 개발에 참여하여 제품간 상호 최적화를 마쳤기때문에 신규 협력사와 최적화를 재진행하는 것은 큰 비용과 장기간이 소요되며,
따라서 한중엔시에스가 약간의 잠김효과를 바탕으로 일부 가격 협상력을 보유한다고 보인다.
고객 다변화가 진전될수록 가격 설정력은 강화될 수 있을 것으로 예상된다.
물량 결정권(Q)
한중엔시에스의 물량은 삼성SDI ESS 증설과 거의 같은 방향으로 움직일 가능성이 높다.
삼성SDI는 ESS 부문에서 NCA SBB 1.7, LFP SBB 2.0, 그리고 비중국계 prismatic ESS 솔루션 공급자라는 포지셔닝을 강조했다.
26년 프리뷰에서는 ESS prismatic full-capacity sales 20GWh, SBB 2.0 on-time mass production, 미국 현지 mass production in 4Q 2026를 제시했다.
26.1Q에는 미국 utility ESS와 AI 데이터센터 BBU를 포함한 ESS 프로젝트 확대도 언급했다.
삼성SDI의 ESS 수주·생산이 실제로 늘면, 설계에 포함된 부품 공급사는 물량을 늘릴 수 있다.
다만 한중엔시에스는 ESS 수주를 스스로 결정하지 못하기 때문에 핵심 고객 삼성SDI의 성장에 의존하는 투자대안에 가깝다.
비용 통제력(C)
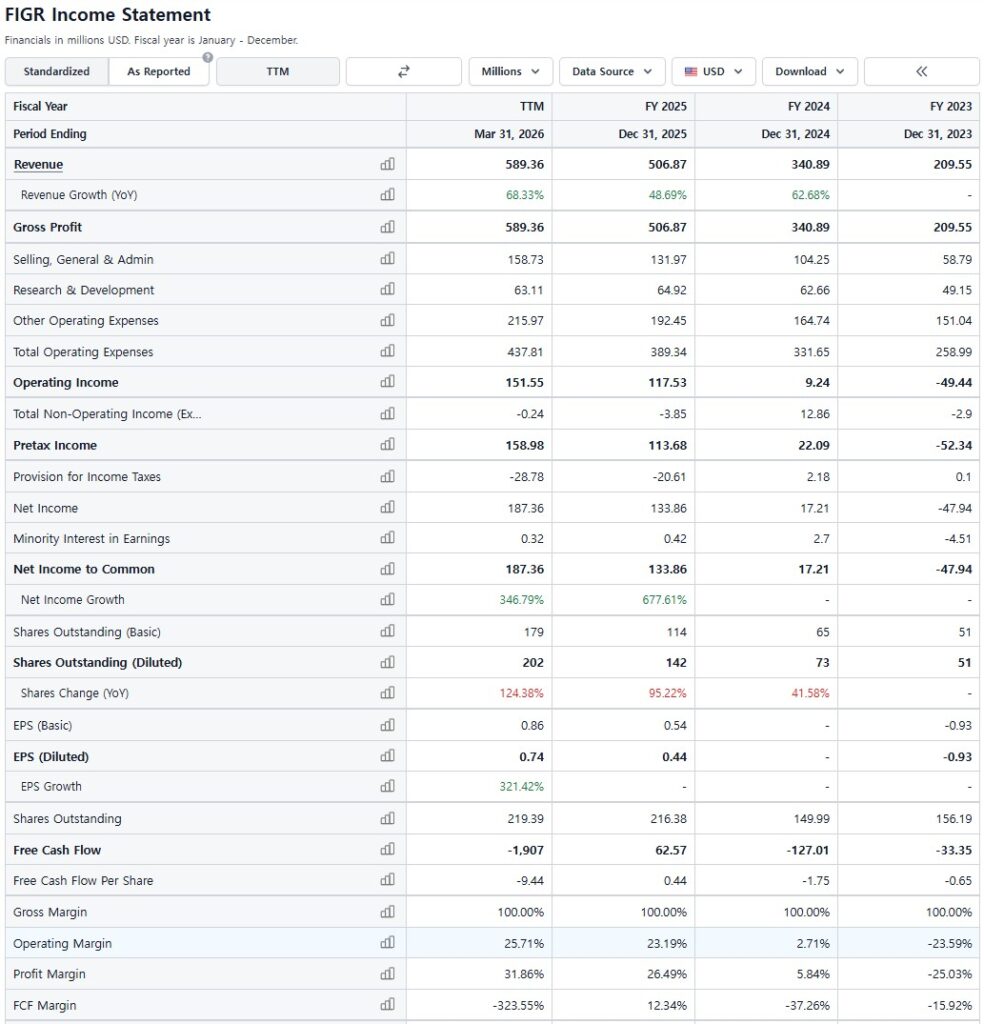
25년 한중엔시에스는 매출이 전년동기 대비 1.1% 감소했지만 매출원가는 4.1% 감소해 매출총이익은 오히려 15.1% 증가했다.
반면 판관비가 55.3% 늘어서 영업이익률은 24년 5.4%에서 25년 2.3%로 3.1%p 감소했다.

판관비 증가 기여도가 높은 항목들을 보면, 인건비 +50.9%, 복리후생비 +68.6%, 연구개발비 +36.4%, 지급수수료 +83.6% 증가가 확인된다.

즉, 이 회사는 제품 판매에 따라 이익은 증가하나, 고정성 성격이 강한 인력·R&D 비용이 선지출된 구조에 가깝다.
이건 시간이 지나면 선지출된 비용이 축소되며 영업레버리지가 작동할 수 있음을 뜻한다.
다만 공장 준공 지연, 삼성SDI 점유율 정체로 성장이 지연되면 이익 레벨이 정체될 수도 있다.
한중엔시에스의 자본배치
자본조달과 현금흐름
회사는 22~23년 적자와 높은 CAPEX로 창출 현금만으로 성장을 감당하지 못했다.
24년에 외부자본 조달과 이익 개선이 일어나면서 현금이 88억원에서 302억원으로 늘었다.
자금조달은 22년 차입금 282억원, 유상증자 124억원이 있었고,
24년에는 유상증자 490억원과 주식매입선택권 행사 46억원이 있었다.
자금조달은 CB보다 차입+보통주 자본조달 중심이었다.
자본조달은 양호한 것으로 평가할 수 있다.
성장 투자 국면에서 은행차입만으로 버티지 않고,
24년 자본확충을 크게 해 레버리지 부담을 낮췄기 때문이다.
부채비율은 23년 808.47%에서 24년 107.39%로 축소되었고,
25년은 다시 152.88%, 26.1Q 154.87%로 높아졌지만,
24년의 큰 증자는 재무안전판 역할을 했다.
증자 자체는 희석이지만, 적자·CAPEX 국면에서 차입만 늘렸다면 더 나빴을 가능성이 높다.
이자비용은 22년 22억원, 23년 42억원, 24년 45억원, 25.상반기 16억원이다.
이를 평균 차입금으로 나누면 대략 23년 7%대 중반, 24년 8%대 후반, 25.상반기 7%대 후반 수준으로 중소형 제조 성장주의 은행차입 비용으로 상식적 수준이다.
사업전략 : 자동차 사업 축소와 ESS 집중
한중엔시에스의 자동차 사업 축소는 법적 분할이나 대규모 자산매각 형태가 아니라,
내부 자원 재배치 형태로 진행되었다.
즉, “자동차 사업을 떼어 판” 것이 아니라 설비·영업의 중심을 ESS 쪽으로 옮긴 것에 가깝다.
이런 경우에는 회사법상 별도 주주총회 특별결의가 필요한 구조조정보다, 경영진과 이사회의 운영 의사결정일 가능성이 높다.
22년 매출총이익은 -14억원, 23년 27억원에 불과했는데, 24년에는 270억원으로 급증했다.
GPM은 -1.6% → 2.2% → 15.2%로 개선되었다.
이는 저마진 사업 축소와 고부가 사업 확대가 동시에 작동한 것으로 평가할 수 있다.
2차전지 산업 흐름도 같은 방향이다.
삼성SDI는 미국 EV 생산라인을 ESS용 LFP 배터리 공급으로 전환하고 있다.
이는 배터리 업계가 EV보다 ESS 쪽의 수요·정책 가시성을 더 높게 보고 생산 포트폴리오를 재배치하고 있다는 의미이다.
한중엔시에스가 삼성SDI 중심 공급망에 얹혀 있다면, 자동차 부품보다 ESS 냉각·팩 모듈 쪽으로 자본을 재배치한 것은 고객 방향과 맞춘 의사결정으로 해석할 수 있다.
승계와 지배구조

사회 환원, 좋은 일자리 제공 등 사회적 가치도 신경쓰는 상식적 경영인으로 보인다.
범법 행위나 비도덕적 행태, 거버넌스 문제는 검색을 통해 확인할 수 없었다.

희석 및 주주환원
25.9월 전환사채가 150억원 발행되어 전환가 33,628원에 446,056주 희석이 일어날 수 있다.
총 주식수 9,064,946주 대비 4.92% 수준의 희석이다.
만기 이자율은 연 1% 수준으로 낮은 수준이나, 주가가 상승할수록 희석 부담은 크다.

주주환원의 경우 아직 증설에 필요한 현금도 충분하지 않아 배당이나 자사주 매입은 없다.
물론 현재와 같은 성장기에 환원으로 현금을 유출했다면 자본배치를 잘 하고 있는 기업으로 보기 어려웠을 것 같다.
밸류에이션
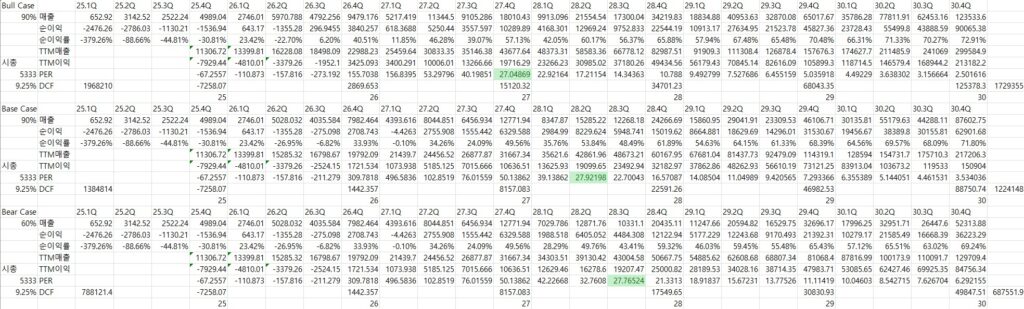
삼성 SDI가 미국 ESS 공장을 설립하여 30Gwh의 생산능력을 확보한다는 전제하에 27년 매출을 추정하고, 이후 미국 ESS 시장 성장률 수준으로 매출이 증가한다고 가정한다.
현재 8Gwh의 ESS 수요에 대응하면서 26.1Q 기준 ESS 부문 530.8억원의 매출을 냈으므로 연간 2천억원 수준의 매출이 난다고 보면, 이르면 미국 한중엔시에스 공장이 준공되는 27년, 늦으면 가동에 소요되는 기간을 감안하여 28년부터 추가되는 30Gwh 수준의 매출이 발생된다.
보수적으로 봤을 때 28년부터 ESS 부문 매출이 9,500억원 전후가 될 것으로 예상된다.

영업레버리지 효과로 이익률은 상승할 것으로 추정되나, 보수적으로 10% 수준이 유지된다고 가정하더라도 28년 이익 레벨은 950억원이며, 코스피 평균 PER 20.33, 중소형주 평균 PER 17.89를 감안하여 목표 멀티플 19, 내재가치 1.8조원을 산출할 수 있다.
이는 현재 시총 2,860억원 대비 6배 이상의 수익을 의미한다.
DCF 방식으로 28년 9,500억원의 매출을 달성한다고 가정했을 때, 27년 시점에서 적정 가치를 산출해봤다.
미국 ESS 시장 성장률로 우드맥킨지, ACP 등은 25~28년 CAGR 10% 수준을 예상하고 있다.
AI 데이터센터, 트럼프 중간선거 패배 이후 신재생 비중확대 등 업사이드 가능성도 있지만 옵션가치를 제외하더라도 10% 수준의 성장률은 달성할 수 있을 것으로 예상된다.
Bull Case의 경우 민주당 정권 차기 선거 승리, 신재생 설치 비중 확대 등으로 인해 시장이 더 빠르게 성장하고 다른 고객사를 유치하여 매출 성장률이 12%로 가속한다고 가정한다.
Bear Case의 경우 다른 고객을 찾지 못하고, 삼성SDI가 경쟁 심화로 점유율을 지켜내지 못한다고 가정하여 매출 성장이 8%로 감속한다고 가정한다.
영업 비용은 영업레버리지 효과를 감안하여 28년 비용 레벨에서 8%로 증가한다고 가정한다.
할인율은 향후 이자율이 어떻게 변화할지 예측이 어렵기 때문에 Bull Case의 경우 6%, Base Case의 경우 8%, Bear Case의 경우 10%로 매우 보수적으로 가정했다.
영구 성장률은 2038년 이후 2% 수준이 유지된다고 가정했다.
그랬을 때 Bull Case의 내재가치는 10.7조원, Base Case의 경우 5.2조원, Bear Case의 경우 1.8조원이 산출되었다.
즉, 삼성 SDI가 시장 성장률을 못 따라가면서 점유율을 잃고, 이자율이 올라가서 할인율이 10%로 상승하고, 영구 성장률은 2038년 이후 2%로 감속한다고 하더라도 28년 증설된 공장이 가동되기만 한다면 최소한 시총 1.76조원 수준이 합리적 내재가치의 하한이다.
그리고 신규 고객 수주, 신재생에너지에 우호적 미국 정부 출범, EU 등 국가 신규 진출 등 옵션가치가 더해지면 기업 가치 상승폭이 더해질 것으로 기대된다.
이런 관점에서 안전마진이 확보되는 한중엔시에스를 커버기업으로 편입하려고 한다.
많은 LTO 멤버들의 비판적 의견과 리스크에 대한 브레인스토밍을 요청드린다.
가치투자 커뮤니티를 성장시켜나가고 있습니다.
운영 계획과 방향성을 한 번 읽어보시고,
텔레그램과 유튜브 채널을 통해 소통하고 있으니 공감이 가신다면 참여해주세요!
쌍방향 소통을 원하는 분들은 카카오톡 채널로 와 주시면 좋을 거 같습니다.
자료실을 통해 리포트, 뉴스도 공유하고 있으니 참고하시면 도움이 될 거 같습니다.




































































{kind=link}